
1. 合并两个行集
表可以没有相同的字段列,但是他们对应列的数据类型必须相同,且具有相同的列个数,
select ename, deptno from emp union allselect '-----', null from t1 union allselect dname, deptno from dept;错误的写法,类型不对,
select deptno from emp union allselect ename from emp;列数不对,
select deptno, dname from dept unionselect deptno from emp;UNION和UNION ALL的区别是,
UNION ALL不会过滤重复项,UNION会过滤重复项。
因此,UNION可能会进行一次排序操作,以便删除重复项。当处理大结果集就需要考虑这个消耗。
UNION等同于对UNION ALL的结果执行一次DISTINCT,
select distinct deptno from (select deptno from emp union allselect deptno from dept);除非场景需要,否则不要用DISTINCT。
除非场景需要,否则不要用UNION代替UNION ALL。
2. 合并相关行
表关联无连接条件则会列出所有可能的行组合,即产生笛卡尔积,
select a.ename, d.loc from emp a, dept d;如果不是场景特殊的需求,应该避免表连接的笛卡尔积。
内连接中的相等连接,
select a.ename, d.loc from emp a, dept d where a.deptno = d.deptno;可显式使用JOIN子句,INNER则是可选项,
select a.ename, d.loc from emp a inner join dept d on (a.deptno = d.deptno);这两种的风格都是符合ANSI标准。如果习惯在FROM子句中,而不是WHERE子句中,写连接逻辑,则可以使用JOIN子句。
如果从可阅读性角度来说,表关联的时候,关联条件写在ON子句中,过滤条件写在WHERE子句中,会更让人理解。
3. 查找两个表中相同的行
WHERE关联,
select e.empno, e.ename from emp e, dept d where e.deptno = d.deptno and e.sal = d.sal;
JOIN关联,
select e.empno, e.ename from emp e join dept d on (e.deptno = d.deptno and e.sal = d.sal);INTERSECT关联,
select empno, ename from emp where (deptno, sal) in (select deptno, sal from empintersetselect deptno, sal from dept);集合运算INTERSECT返回两个行集的相同部分,但是必须保证两张表比较的列数相同,并且数据类型都相同,当执行集合运算,默认不会返回重复项。
4. 查找只存在于一张表中的数据
DB2、PG,
select deptno from deptexceptselect deptno from emp;Oralce,
select deptno from dept minusselect deptno from emp;MySQL、SQL Server,
select deptno from dept where deptno not in (select deptno from emp);EXCEPT和MINUS函数不会返回重复项,并且NULL值不会产生问题。
NOT IN这种形式,会得到emp所有deptno,外层查询会返回dept表中”不存在于”或者”未被包含在”子查询结果集中的deptno值。需要自行考虑重复项的过滤操作。如果deptno是主键,不需要改,如果不是,则需要使用DISTINCT来确保每个在emp表中缺少的deptno值只出现一次,如下所示,
select distinct deptno from dept where deptno not in (select deptno from emp);但是使用NOT IN,可能要注意NULL值,因为IN和NOT IN本质上就是OR运算,但是由于NULL值参与OR逻辑运算的方式不同,IN和NOT IN将会产生不同的结果。
做个实验,测试表,t01的记录是10、20、30,t02的记录是10、50、null,
SQL> select * from t01; ID---------- 10 20 30
SQL> select * from t02; ID----------
10 50IN操作,
SQL> select * from t01 where id in (10, 50, null); ID---------- 10
SQL> select * from t01 where (id=10 or id=50 or id=null); ID---------- 10NOT IN操作,
SQL> select * from t01 where id not in (10, 50, null);no rows selected
SQL> select * from t01 where not (id=10 or id=50 or id=null);no rows selected因为TRUE or NULL返回TRUE,但是FALSE or NULL返回NULL,所以当使用IN和OR时,要注意是否会涉及到NULL值。
为了避免NOT IN和NULL值带来的问题,可以结合使用NOT EXISTS和关联子查询。关联子查询指的是外层查询执行的结果集会被内层子查询引用。
SQL> select * from t01 where not exists (select null from t02 where t01.id = t02.id); ID---------- 30 20他的逻辑是,
(1) 执行子查询,检查当前t01的id是否存在于t02。
(2) 如果子查询有结果就返回给外层查询,那么EXISTS的结果是TRUE,NOT EXISTS就是FALSE,如此一来,外层查询就会舍弃当前行。
(3) 如果子查询没有返回任何结果,那么NOT EXISTS的结果是TRUE,由此外层查询就会返回当前行(因为他是一个不存在于t02的记录)。
EXISTS/NOT EXISTS和关联子查询一起使用时,SELECT中的列,不重要,之所以使用了NULL,是为了让注意力集中在子查询的连接操作上,而不是SELECT的列上。
5. 从一个表检索和另一个表不相关的行
基于共同列将两个表连接起来,返回一个表的所有行,不论这些行在另一个表中是否存在匹配行,然后,只存储这些不匹配的行即可。
select d.* from dept d left outer join emp e on (d.deptno = e.deptno) where e.deptno is null;P. S. 关键字OUTER是可选的。
如果是Oracle 9i+,可使用专用外连接的语法,如果是Oracle 8i,则只能使用这种专用的语法,
select d.* from dept d left outer join emp e on d.deptno = e.deptno (+) where e.deptno is null;这种操作有时候被称为反链接(anti-join)。
6. 新增连接查询而不影响其他连接查询
如果是DB2、MySQL、PG以及SQL Server、Oracle 9i以上,可使用,
select e.ename, d.loc, eb.received from emp e join dept d on (e.deptno = d.deptno) left join emp_bonus eb on (e.empno = eb.empno) order by 2;如果是Oracle 8i,可使用,
select e.ename, d.loc, eb.received from emp e, dept d, emp_bonus eb where e.deptno = d.deptno and e.empno = eb.empno(+) order by 2;还可以使用标量子查询(将子查询放置到了SELECT的列表),模仿外连接,标量子查询适合于所有数据库,
select e.ename, d.loc, (select eb.received from emp_bonus eb where eb.empno = e.empno) as received from emp e, dept d where e.deptno = d.deptno order by 2;外连接查询会返回一个表中的所有行,以及另外一个表中和之匹配的行。标量子查询,不需要改主查询中正确的连接操作,他是为现有查询增加新数据的最佳方案。但是当使用标量子查询时,必须保证返回的是标量值(单值),不能返回多行。
7. 确定两个表是否有相同的数据
可以用求差集(MINUS或EXCEPT),还可以在比较数据之前先单独比较行数,
select count(*) from emp unionselect count(*) from dept;因为UNION子句会过滤重复项,如果两个表的行数相同,则只会返回一行数据,如果返回两行,说明这两个表中没有完全相同的数据。
8. 识别并消除笛卡尔积
为了消除笛卡尔积,通常用到n-1法则,其中n代表FROM子句中的表个数,n-1则代表了消除笛卡尔积所必需的链接查询的最少次数。
笛卡尔积经常用到变换或展开(合并)结果集,生成一系列的值,以及模拟loop循环。
9. 组合适用连接查询和聚合函数
如果连接查询产生了重复行,通常有两种办法来使用聚合函数,
(1) 调用聚合函数时,使用关键字DISTINCT,每个值都会先去掉重复项再参与计算。
(2) 在进行连接查询之前先执行聚合运算(以内嵌视图),避免错误的结果,因为聚合运算产生在连接查询之前。
MySQL和PG,使用DISTINCT计算工资总额,
select deptno, sum(distinct sal) as total_sal, sum(bonus) as total_bonus from (select e.empno, e.ename, e.sql, e.deptno, e.sql * case when eb.type = 1 then .1 when eb.type = 2 then .2 else .3 end as bonus from emp e, emp_bonus ebwhere e.empno = eb.empno and e.deptno = 10 ) x group by deptno;DB2、Oracle和SQL Server除了以上操作,还可以使用窗口函数sum over,
select distinct deptno, total_sal, otal_bonus from (select e.empno, e.ename, sum(distinct e.sal) over (partition by e.deptno) as total_sal, e.deptno, sum(e.sql * case when eb.type = 1 then .1 when eb.type = 2 then .2 else .3) over (partition by deptno) as total_bonus from emp e, emp_bonus ebwhere e.empno = eb.empno and e.deptno = 10 ) x;第二种解决方案,就是先计算员工的工资总额,然后连接表,如下语句适用于所有的数据库,
select e.deptno, d.total_sal, sum(e.sal * case when eb.type = 1 then .1 when eb.type = 2 then .2 else .3) as total_bonus from emp e, emp_bonus eb, (select deptno, sum(sal) as total_sal from empwhere deptno = 10 group by deptno ) dwhere e.deptno = d.deptno and e.empno = eb.empno group by d.deptno, d.total_sal;DB2、Oracle和SQL Server除了以上操作,还可以使用窗口函数sum over,
select e.deptno, d.total_sal, sum(distinct e.sal) over (partition by e.deptno) as total_sal, e.deptno, sum(e.sal * case when eb.type = 1 then .1 when eb.type = 2 then .2 else .3) over (partition by deptno) as total_bonus from emp e, emp_bonus eb,where e.empno = eb.empno and e.deptno = 10;10. 组合使用外连接查询和聚合函数
如果部门编号为10的员工只有部分有奖金,如果只是全连接,可能会漏掉无奖金的员工,此事要使用外连接将所有员工包括进来,同时去掉编号为10的员工的重复项,如下所示,
select deptno, sum(distinct sal) as total_sal, sum(bonus) as total_bonus from (select e.empno, e.ename, e.sql, e.deptno, e.sql * case when eb.type is null then 0 when eb.type = 1 then .1 when eb.type = 2 then .2 else .3 end as bonus from emp e left outer join emp_bonus eb on (e.empno = eb.empno)where e.deptno = 10 ) group by deptno;还可以使用窗口函数sum over,
select distinct deptno, total_sal, otal_bonus from (select e.empno, e.ename, sum(distinct e.sal) over (partition by e.deptno) as total_sal, e.deptno, sum(e.sql * case when eb.type is null then 0 when eb.type = 1 then .1 when eb.type = 2 then .2 else .3) over (partition by deptno) as total_bonus from emp e left outer join emp_bonus eb on (e.empno = eb.empno)where e.deptno = 10 ) x;对Oracle,还可以使用专有的外连接语法,
select distinct deptno, total_sal, otal_bonus from (select e.empno, e.ename, sum(distinct e.sal) over (partition by e.deptno) as total_sal, e.deptno, sum(e.sql * case when eb.type is null then 0 when eb.type = 1 then .1 when eb.type = 2 then .2 else .3) over (partition by deptno) as total_bonus from emp e, emp_bonus ebwhere e.empno = eb.empno(+) and e.deptno = 10 ) group by deptno;如果计算编号为10的员工的工资总额,然后连接两表,这就避免了使用外连接,如下所示,
select e.deptno, d.total_sal, sum(e.sal * case when eb.type = 1 then .1 when eb.type = 2 then .2 else .3) as total_bonus from emp e, emp_bonus eb, (select deptno, sum(sal) as total_sal from empwhere deptno = 10 group by deptno ) dwhere e.deptno = d.deptno and e.empno = eb.empno group by d.deptno, d.total_sal;11. 多个表中返回缺少的值
使用全外连接,基于一个共同值从两个表中返回缺少的值,全外连接查询就是合并两个表的外连接查询的结果集。
DB2、MySQL、PG和SQL Server,可以用,
select d.deptno, d.dname, e.ename from dept d full outer join emp e on (d.deptno = e.deptno);还可以合并两个外连接的查询结果,
select d.deptno, d.dname, e.ename from dept d right outer join emp e on (d.deptno = e.deptno) unionselect d.deptno, d.dname, e.ename from dept d left outer join emp e on (d.deptno = e.deptno);如果是Oracle,可以使用专有的外连接语法,
select d.deptno, d.dname, e.ename from dept d, emp e where d.deptno = e.deptno(+) unionselect d.deptno, d.dname, e.ename from dept d, emp e where d.deptno(+) = e.deptno;12. 运算比较中使用NULL
NULL不等于任何值,甚至不能和其自身进行比较,但是对从NULL列返回的数据进行评估,就像评估具体的值一样。
coalesce函数能将NULL转成一个具体的,可以用于标准评估的值,coalesce函数返回参数列表里的第一个非NULL值,
select ename, comm, coalesce(comm, 0) from empwhere coalesce(comm, 0) < (select comm from emp where ename = 'WARD');可能有朋友会问,coalesce函数和nvl函数,有什么区别?
(1) nvl(expr, 0)
如果第一个参数为null,则返回第二个参数。
如果第一个参数为非null,则返回第一个参数。
(2) coalesce(expr1, expr2, expr3 … exprn)
从左往右数,遇到第一个非null值,则返回该非null值。
看着很像,但是有些区别,
(1) nvl只适合于两个参数的,coalesce适合于多个参数。
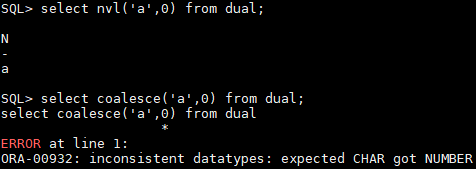
(2) coalesce里的所有参数类型必须保持一致,nvl可以不一致,如下所示,

声明:文中观点不代表本站立场。本文传送门:https://eyangzhen.com/136789.html


