
背景
当监控平台发现流量突增,业务系统应用或链路监控出现一定范围的告警,此时我们查看问题的方向为:
- APP或网站是否被攻击了,如DDOS、CC、暴力破解等;
- 合作推广带来的业务流量增高,应用系统压力过大;
- 数据库是否出现因连接数满、事务死锁导致压力过大;
以上几种情况都是我们在处理生产故障过程中比较常见的, 本次我们就应用系统压力过大的场景,需要进行横向扩容的方向来讲解。
需求
当应用系统压力过大,除了临时调整线程数或直接横向扩容来解决外,更深入的优化代码以及调用链路上的耗时接口就更加滞后了。因此我们决定通过应用横向扩容来应对系统压力过大,此时实现如何快速扩容就成了我们重点关注的问题。
传统架构下,对于应用横向扩容我们需要做的重点步骤如下:
- 闲置的服务器资源;
- 系统标准化部署步骤(应用发布、标准目录、配置发布、应用启动);
- 应用启动自动健康检查;
- 应用启动后自动接入负载均衡或注册中心;
- 应用横向扩容后同步到系统监控平台;
- CMDB资产同步添加到对应业务分组;
- 应用服务器同步至堡垒机;
以上是新的应用服务器上线在运维管理过程中流转涉及的各个主要环节,除了提前准备闲置的服务器资源以节省不必要的时间外,其他都是需要根据我们系统架构及运维平台的实际情况去适配,我这里只是提供了一个思路。
假设,一套比较主流的架构为:
- CMDB,基础设施统一纳管
- Zabbix监控,统一的健康检查
- JumpServer堡垒机,服务器统一登录管理
- Spring Cloud 框架
- Eureka注册中心
- Apollo配置中心
解决方案
在此我们通过Pipeline支撑运维自动化的思想来实现应用横向扩容,以流水线的形式编排不同级别的原子模块来实现不同运维场景的功能需求。
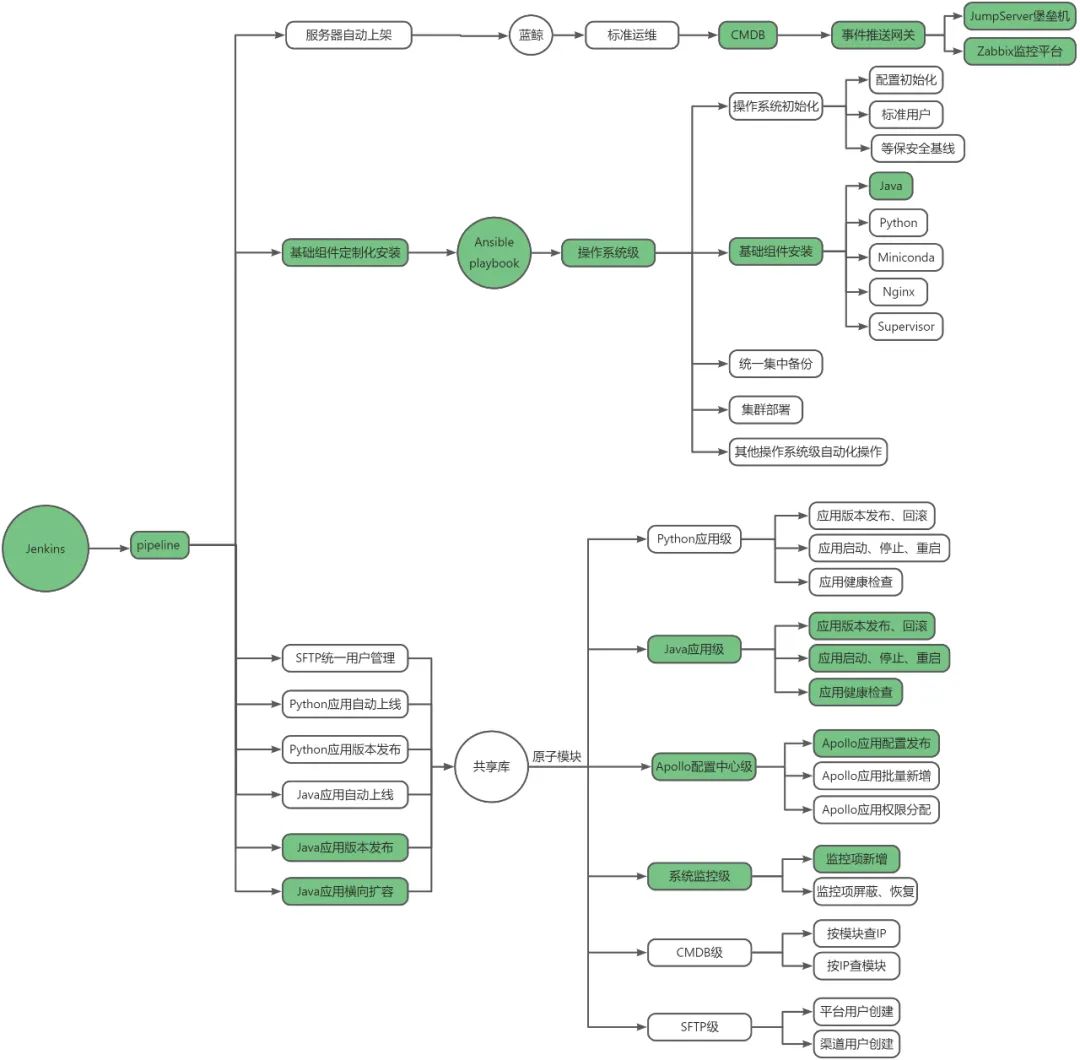

根据系统架构,应用横向扩容流水线的实现涉及的功能模块上图中已经标注出来,其中:
- CMDB+事件推送网关,可通过CMDB对空闲服务器资源分配触发资产在Zabbix监控和堡垒中自动同步;
- 基础组件安装,实现了Java环境包括标准部署目录、JDK环境、管理脚本等内容的自动配置;当然我们默认空闲服务器已经是按操作系统初始化(配置初始化、标准用户、等保安全基线)交付的,因此我们在此没有过多介绍。
- Java应用级原子模块,实现应用的发布、启停、健康检查等功能;
- Apollo配置中心级原子模块,实现应用的配置发布;
- 系统监控级原子模块,扩容后应用的健康检查同步添加到监控平台;
具体实现
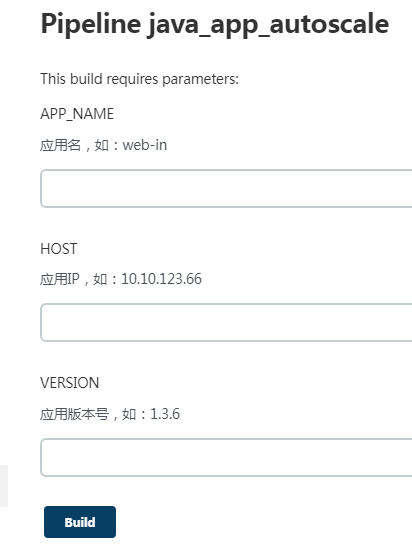
1.构建
我们只需输入应用名、新应用IP、版本号,就可以实现应用的横向扩容,但是目前只支持逐台扩容,还不能批量横向扩容。
2.构建结果
通过对流水线的stage的时间统计,应用扩容耗主要为版本发布过程中的启动时间。

3.Pipeline
@Library('shared-library') _
pipeline {
agent any
options {
timestamps()
}
stages {
stage('基础组件初始化') {
steps {
script {
build job: 'init_system', parameters: [text(name: 'HOST_IP', value: "${HOST}"), string(name: 'PLAYBOOK', value: 'software_install.yml'), string(name: 'TAG', value: 'java,filebeat')]
}
}
}
stage('应用初始化') {
steps {
script {
java_deploy.InitApp("${APP_NAME}")
}
}
}
stage('拉取Yunweiconfig配置') {
steps {
script {
java_deploy.PullFromYunweiconfig("${APP_NAME}")
}
}
}
stage('从制品库拉取包文件') {
steps {
script {
java_deploy.PullFromArtifactory("${APP_NAME}", "${VERSION}")
}
}
}
stage('apollo更新') {
steps {
script {
apollo.ApolloDeploy("${APP_NAME}")
}
}
}
stage('版本发布') {
steps {
script {
app_port = apollo.ApolloGetPort("${APP_NAME}")
java_deploy.DeployApp("${APP_NAME}", "${VERSION}", "${HOST}")
ip_port = "${HOST}" + ':' + "${app_port}"
//健康检查
java_deploy.HealthCheck("${ip_port}")
}
}
}
stage('添加zabbix健康检查 ') {
steps {
script {
app_prot = apollo.ApolloGetPort("${APP_NAME}")
//println("test pass")
println("${app_prot},${HOST}")
ip_port = "${HOST}" + ':' + "${app_prot}"
build job: 'zabbix_newalert', parameters: [string(name: 'APP_NAME', value: "${APP_NAME}"), string(name: 'IP_PORT', value: ""), string(name: 'HTTP_URL', value: "${ip_port}")]
}
}
}
}
}
PK容器
- 弹性伸缩相对于传统架构,操作系统CPU、内存资源阈值的粒度太粗,无法精确地进行适时扩容;另外对于批量扩容,需要提前准备好资源,相对于容器的解决方案还是不够灵活。
- 启动时间无论是容器还是传统架构,限制快速扩容的主要原因在于应用的启动时间,这方面要提前进行优化。
- IP地址分配传统架构无法做到IP地址的自动分配,在生产环境使用DHCP不仅会导致keepalived切换产生脑裂,还会因租期问题产生其他问题。而云原生架构的可以做到自定义IP池,因此后续扩容会使用IP池中的地址。
以上几点是通过本次对应用自动横向扩容,与容器使用过程中的几点对比,印象比较深刻。
总结
本次PK,传统架构虽然输了,但也并不是一败涂地。至少让我发现只要细心,坚持标准化、原子化、场景化的原则,我们还是有很大空间可以提升的。容器给了我们目标和方向,剩下就要看我们自己了。
声明:文中观点不代表本站立场。本文传送门:https://eyangzhen.com/164574.html


