
相信做后端的同学肯定离不开一个话题,就是 mysql,大家也花式的执行过各种各样的 sql 语句,然后得到返回结果,那么一条 sql 语句执行究竟经历了哪些步骤呢?今天让我们来一探究竟。
我们先来看一看 mysql 的整体的架构图
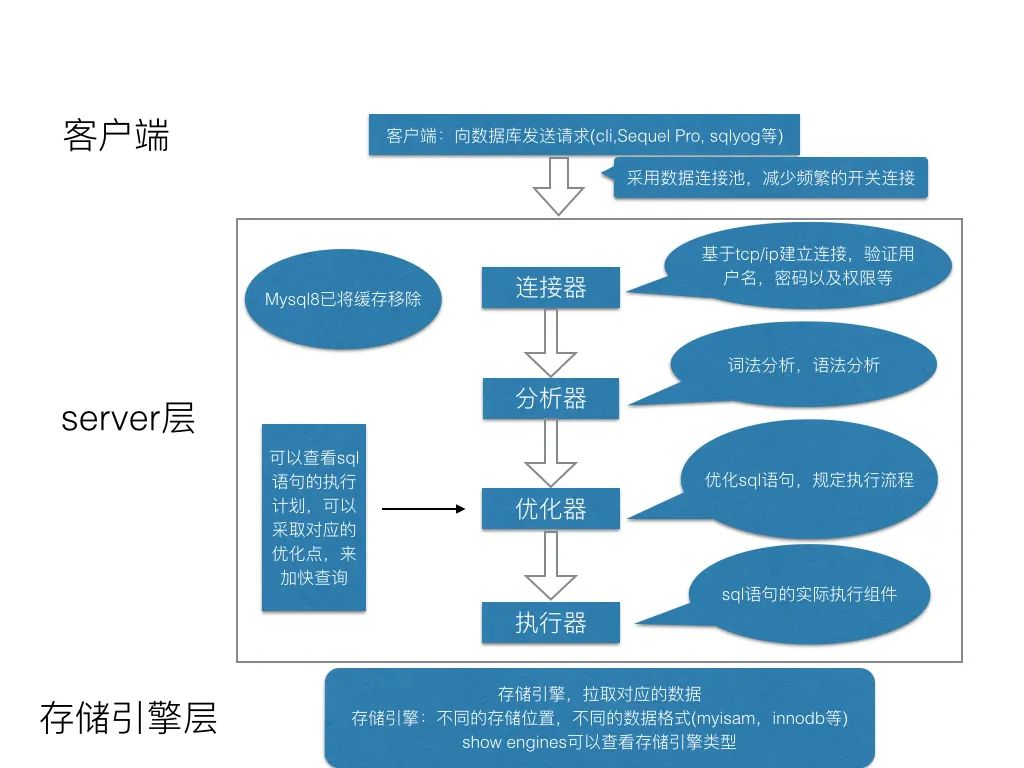

其实从上图可以看出,由客户端发出请求之后,mysql主要分为server层和存储引擎层
server层
连接器
连接器主要是与客户端建立连接, 包含本地socket和大多数基于客户端/服务端工具实现的类似于tcp/ip的通信。连接成功之后会同时校验用户的权限,等相关安全方案。如我们常用的建立连接方式
mysql -h ip -P 3306 -u root -p
只要用过数据库的同学,相信对上面的连接方式并不陌生,在连接之后还有一些权限验证等等,这些都是在连接器中完成的。
这里需要注意的一点就是,在线上的应用中,会采用数据库连接池的方式,来避免频繁的开关连接。
另外可以用show processlist; 用来显示用户正在运行的线程。
分析器
对客户端传来的 sql 进行分析,这将包括预处理与解析过程,并进行关键词的提取、解析,并组成一个解析树。具体的解析词包括但不局限于 select/update/delete/or/in/where/group by/having/count/limit 等,如果分析到语法错误,会直接抛给客户端异常:
ERROR:You have an error in your SQL syntax.
比如:
select * from user where userId =1234;
在分析器中就通过语义规则器将select from where这些关键词提取和匹配出来,mysql会自动判断关键词和非关键词,将用户的匹配字段和自定义语句识别出来。这个阶段也会做一些校验:比如校验当前数据库是否存在user表,同时假如User表中不存在userId这个字段同样会报错:
unknown column in field list
优化器
进入优化器说明sql语句是符合标准语义规则并且可以执行。优化器会根据执行计划选择最优的选择,匹配合适的索引,选择最佳的方案。比如一个典型的例子是这样的:
表T,对A、B、C列建立联合索引(A,B,C),在进行查询的时候,当sql查询条件是:select xx where B=x and A=x and C=x.很多人会以为是用不到索引的,但其实会用到,虽然索引必须符合最左原则才能使用,但是本质上,优化器会自动将这条sql优化为:where A=x and B=x and C=X,这种优化会为了底层能够匹配到索引,同时在这个阶段是自动按照执行计划进行预处理,mysql会计算各个执行方法的最佳时间,最终确定一条执行的sql交给最后的执行器
执行器
执行器会调用对应的存储引擎执行 sql。主流的是MyISAM 和 Innodb。
缓存
数据库在8.0以前是有缓存的,但是说实话这个用处不大,一般线上也不会开启数据库缓存,首先因为开启缓存也是占一定的开销的,另外实际应用中一模一样的sql语句重复多次查询的场景很少很少,所以在8.0以后直接把缓存给去掉了,所以缓存这里咱们就不讨论了。
总结
MySQL server层逻辑架构从上往下可以分为三层:
(1)第一层:处理客户端连接、授权认证等。
(2)第二层:服务器层,负责查询语句的解析、优化、缓存以及内置函数的实现、存储过程等。
(3)第三层:存储引擎,负责MySQL中数据的存储和提取。MySQL中服务器层不管理事务,事务是由存储引擎实现的。MySQL支持事务的存储引擎有InnoDB、NDB Cluster等,其中InnoDB的使用最为广泛;其他存储引擎不支持事务,如MyIsam、Memory等。具体过程都在图中有所标注,篇幅有限,大家可以先有个大概的认识,具体的步骤咱们后面继续更新。
往期精选
redis源码之zset结构的实现
redis源码之set结构
redis源码之hash结构的实现
redis源码之list结构的实现
redis源码之dict
redis源码之SDS
redis的两种持久化的机制,你真的了解么?
绝对能让你彻底明白的Redis的内存淘汰策略
redis缓存穿透穿透解决方案-布隆过滤器
redis五种数据的应用场景
redis中setbit(位操作)的实际应用
扫描二维码
获取更多精彩
微信号 : quven2014
声明:文中观点不代表本站立场。本文传送门:https://eyangzhen.com/239285.html


