
最近在学习ctf,偶尔会做一些ctf题,打算记录下做题的步骤和思路,打算学习ctf的小白可以跟着一起动手学习。本题是安卓题目。
题目apk下载地址
下载完后,重命名为 easy-apk.apk。
使用 jeb 反编译,本次使用的是 jeb 3.19 ,网上有破解版本下载,也可以在公众号回复 jeb 获取
把 apk 文件拖到 jeb 窗口中进行反编译
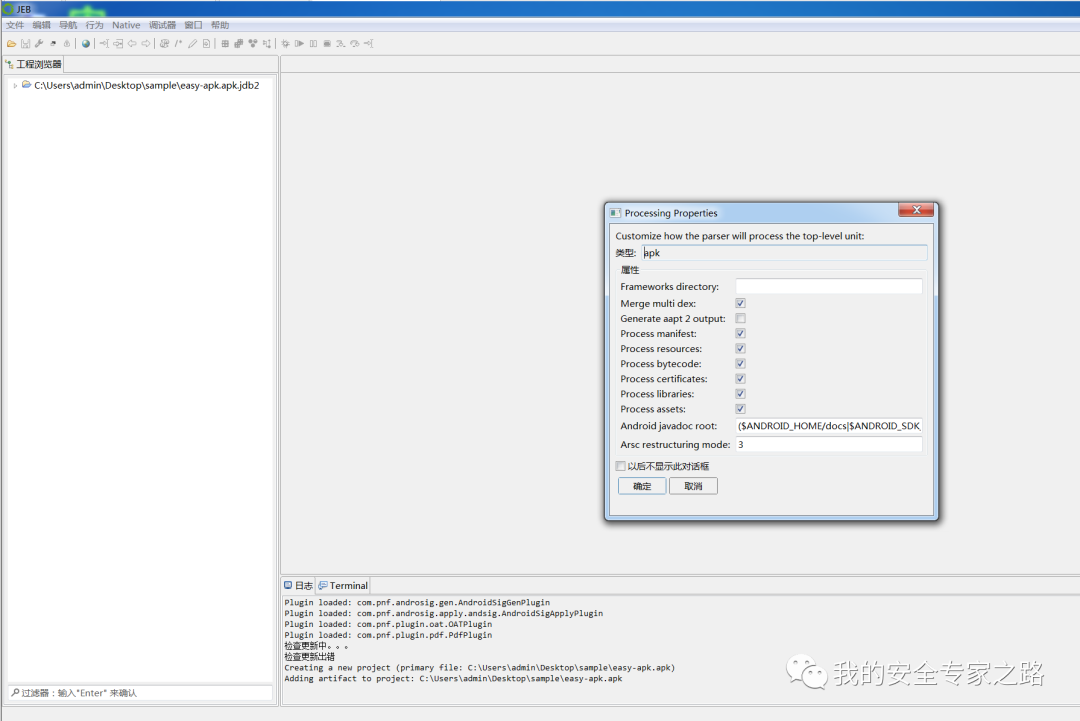

反编译完成后,点击 MainActivity 查看主界面的代码逻辑。
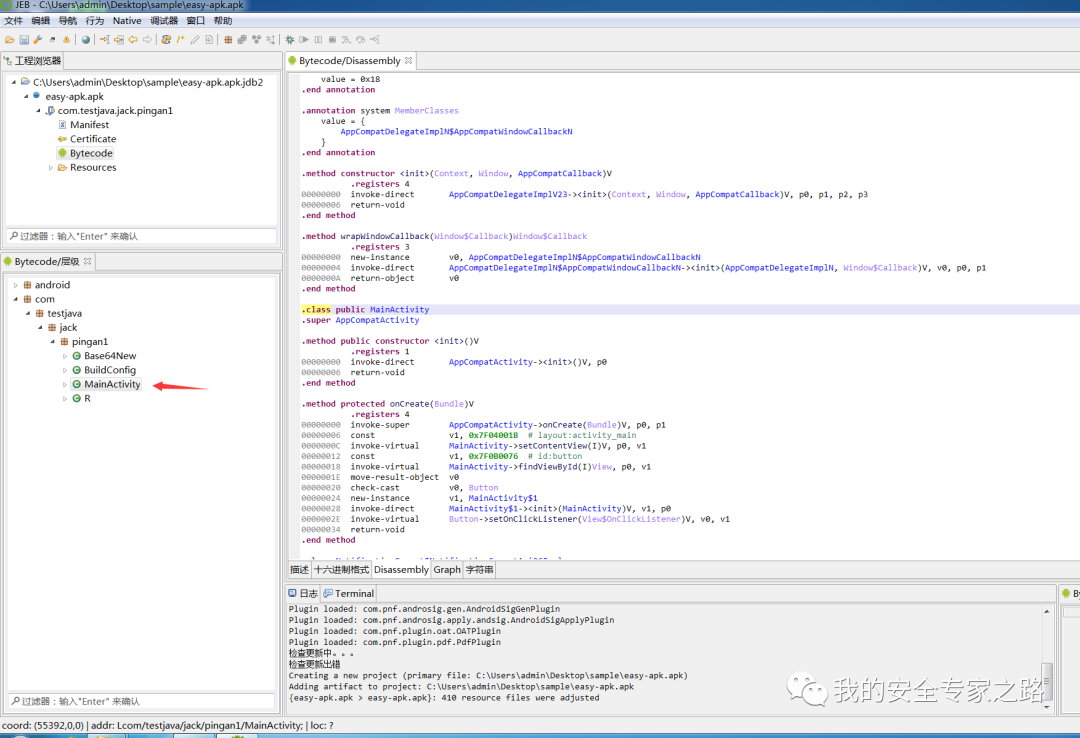
反编译显示的代码默认是 smail 代码,可读性不高,先转换为 java 代码,点击下图所示图标,转换成 java 代码。
代码如下
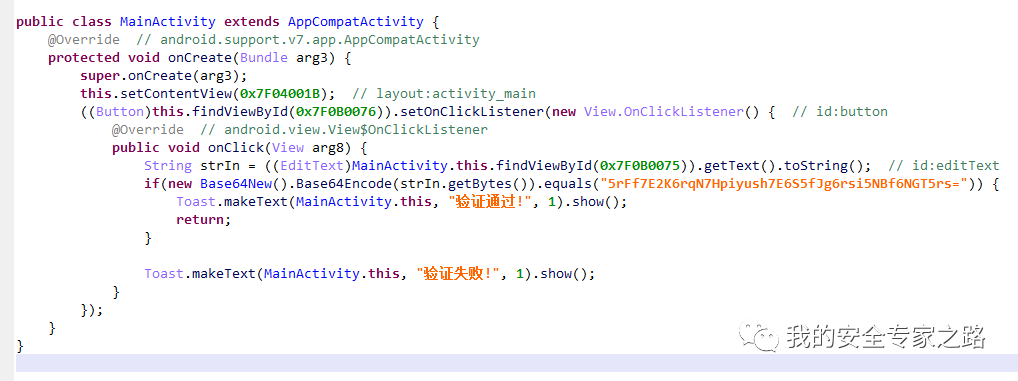
代码中通过 EditText 的 getText() 方法获取了输入框的文字,然后进行base64 编码后和 5rFf7E2K6rqN7Hpiyush7E6S5fJg6rsi5NBf6NGT5rs= 进行比较,如果一致,则验证通过。猜想 flag 就是
5rFf7E2K6rqN7Hpiyush7E6S5fJg6rsi5NBf6NGT5rs=
解码后的内容。
直接在网上找个在线解码 base64 的网站,发现解码后是乱码
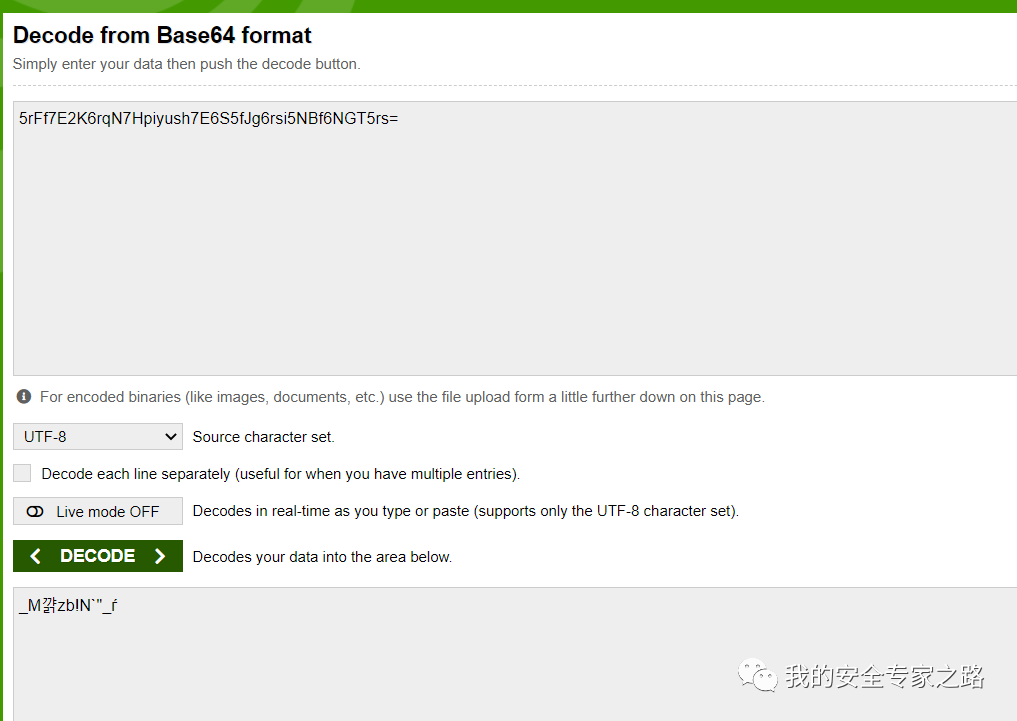
再看看代码中的 base64 是怎样编码的,双击 Base64Encode 方法,查看相应代码。

可以看到这里是一个使用了自定义索引表的 base64 编码算法。
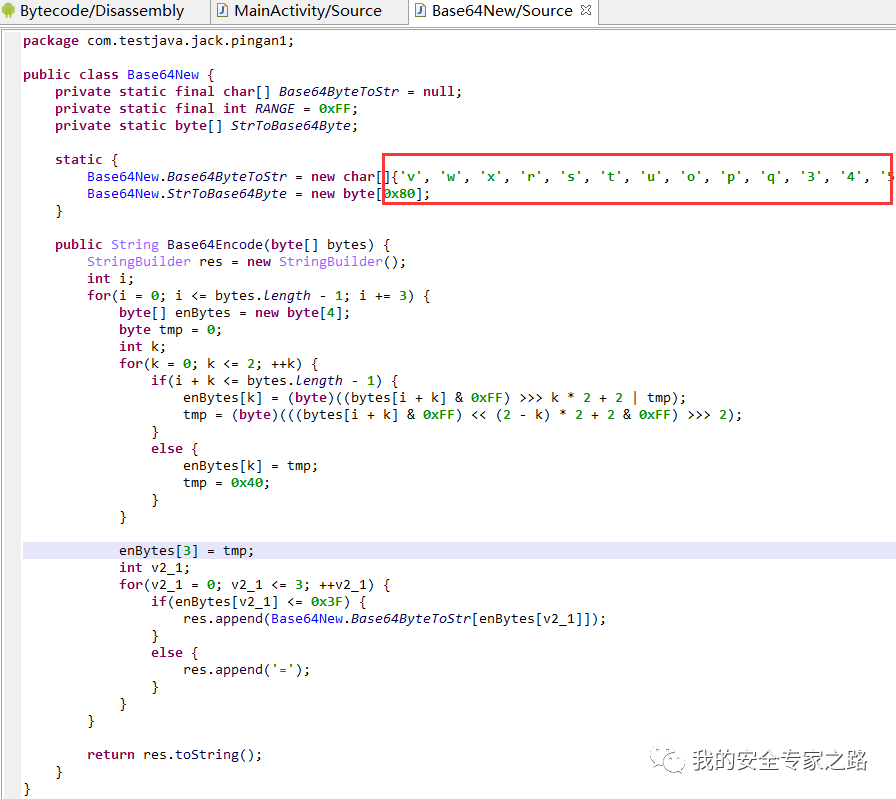
这里简单说下 base64 编码的原理,在参数传输的过程中经常遇到的一种情况:使用全英文的没问题,一旦涉及到中文就会出现乱码情况。与此类似,网络上传输的字符并不全是可打印的字符,比如二进制文件、图片等。Base64的出现就是为了解决此问题,它是基于64个可打印的字符来表示二进制的数据的一种方法。base64 编码后的数据只会是下面索引表中的64个字符。
第一步,将待转换的字符串每三个字节分为一组,每个字节占8bit,那么共有24个二进制位。
第二步,将上面的24个二进制位每6个一组,共分为4组。
第三步,在每组前面添加两个0,每组由6个变为8个二进制位,总共32个二进制位,即四个字节。
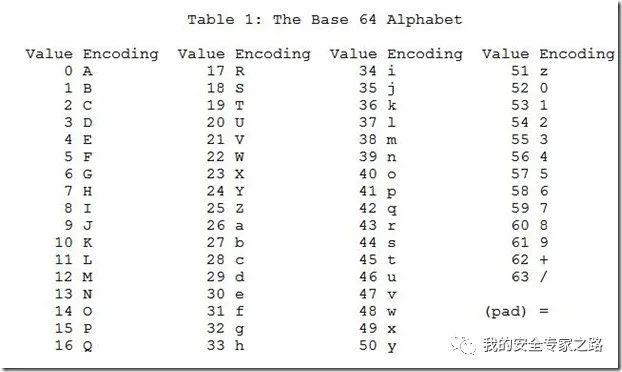
第四步,这四个字节的值根据Base64编码对照表(上图)获得对应的值
如果字节数不足三个,则在后面补=号
例如二进制值为 1、2、3 的3个数据,转换成 base64 编码的过程如下
//二进制值00000001,00000010,00000011//将上面的24个二进制位每6个一组,共分为4组。000000,010000,001000,000011//在每组前面添加两个0,每组由6个变为8个二进制位,总共32个二进制位,即四个字节。00000000,00010000,00001000,00000011//这四个字节的值根据Base64编码对照表(上图)获得对应的//对应的十进制数分别为0,16,8,3//查表得0 -> A16 -> Q8 -> I3 -> D// base64 编码后的结果是AQID在题目中,该 base64 编码使用了自定义的索引表,如使用 v 代替 A,w 代替 B 。那么我们需要换回去,再进行正常的 base64 解码。
自定义编码后的值如下,
5rFf7E2K6rqN7Hpiyush7E6S5fJg6rsi5NBf6NGT5rs=
如 r 字符为例,r 字符为自定义索引表的第4个字符,对照原来的索引表是 D,所以要把 r换成 D。其它字符同理,可以使用下面 python 代码进行转换,并求出 flag
#coding=utf-8import base64import stringstr1 = "5rFf7E2K6rqN7Hpiyush7E6S5fJg6rsi5NBf6NGT5rs="string1 = "vwxrstuopq34567ABCDEFGHIJyz012PQRSTKLMNOZabcdUVWXYefghijklmn89+/"string2 = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"str2 = str1.translate(str.maketrans(string1,string2))print("转换后的字符串:" + str2)print("flag:" + str(base64.b64decode(str2)))
flag值为:
05397c42f9b6da593a3644162d36eb01
声明:文中观点不代表本站立场。本文传送门:https://eyangzhen.com/247200.html


