
MySQL Shell 8.1与MySQL 8.1 同日发行,在这个创新版里,MySQL Shell推出了一个新的功能——MySQL InnoDB Cluster Read Replicas,为InnoDB Cluster增加了只读副本。通过该功能,用户可以分散集群的工作负载,将数据的读取从InnoDB Cluster分散到一个或多个只读副本上,并为InnoDB Cluster提供额外的数据副本。这同样也是MySQL的一个高可用性方案,该架构的示意图如下:
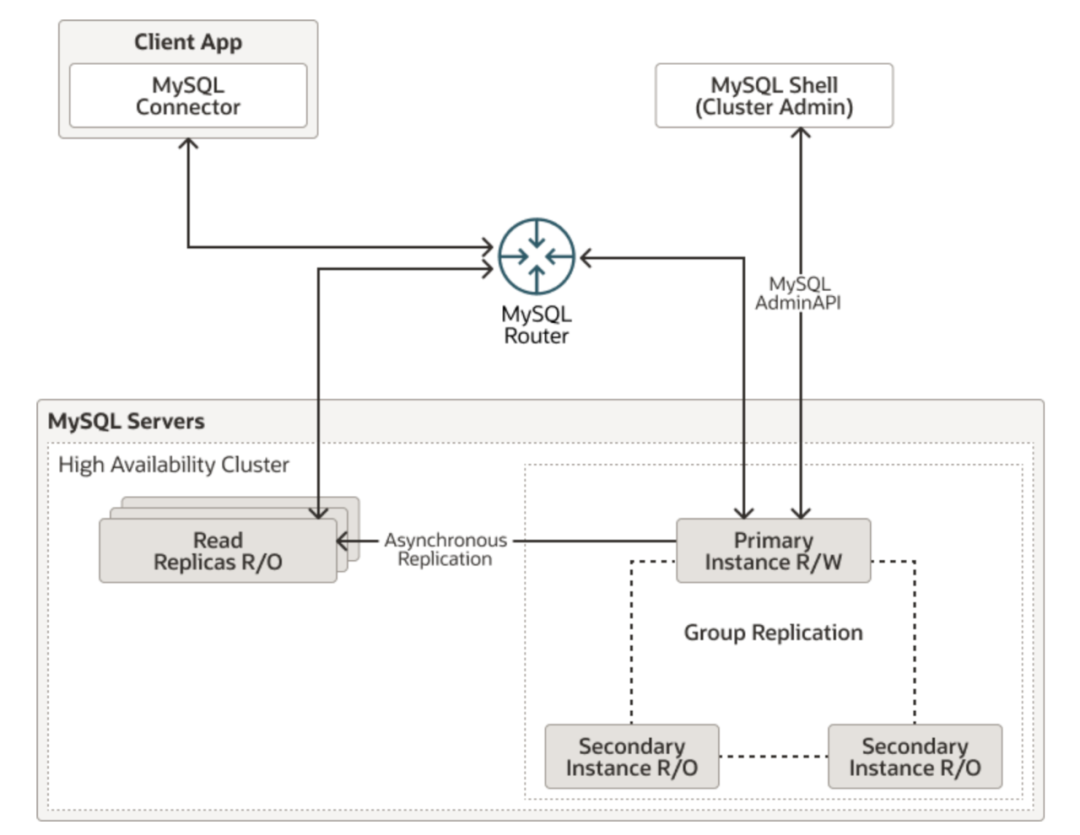

到目前为止,MySQL的高可用方案包括如下:
- InnoDB Cluster
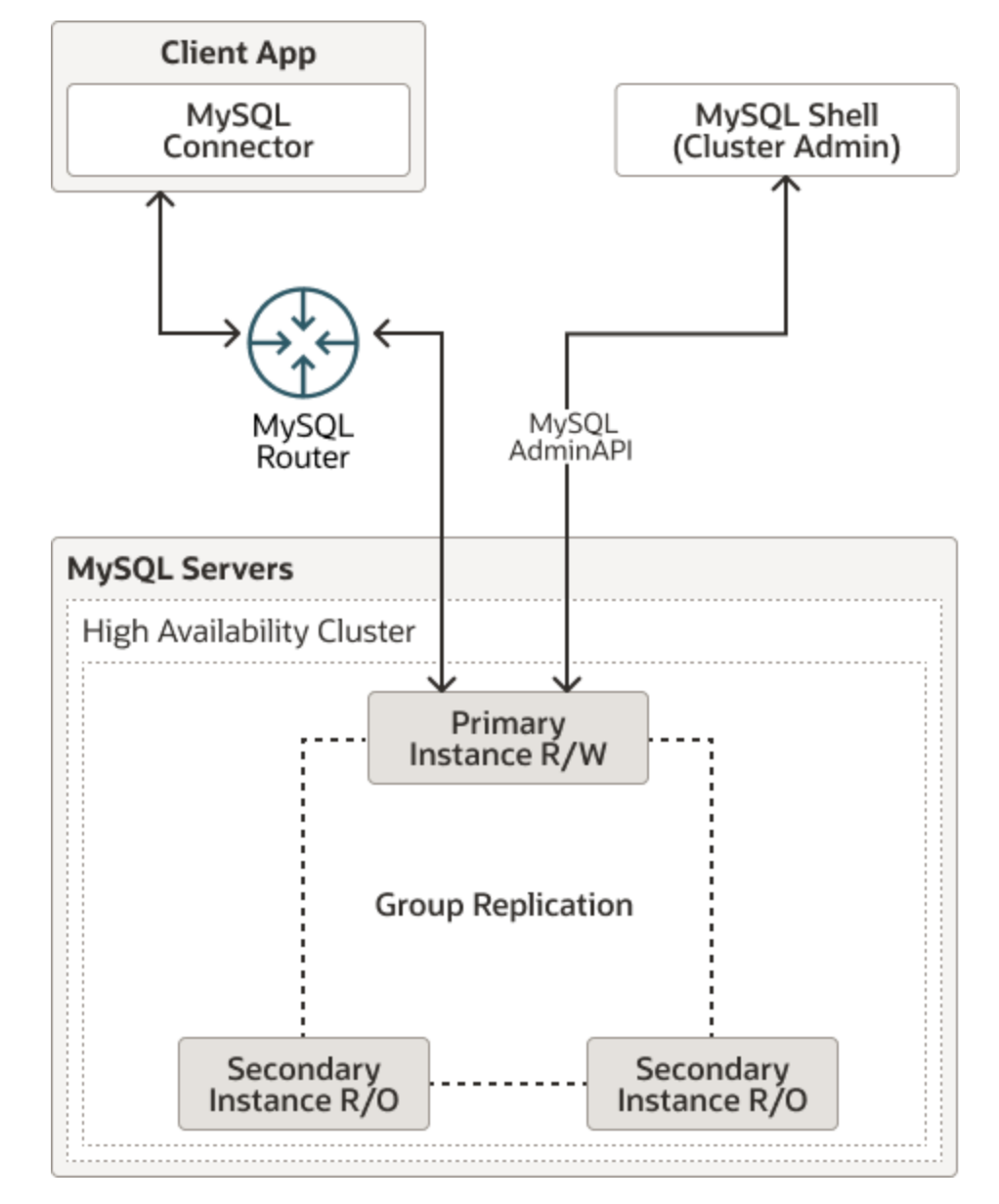
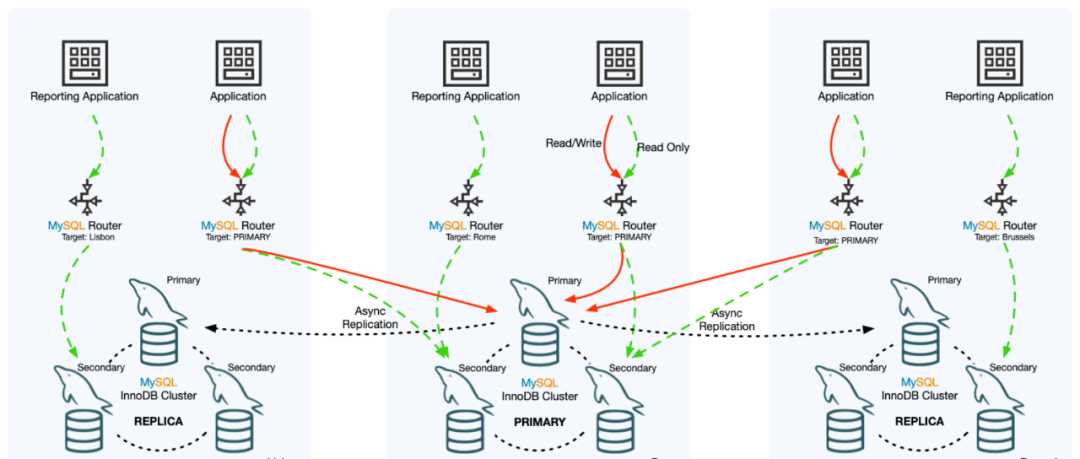
- InnoDB ClusterSet
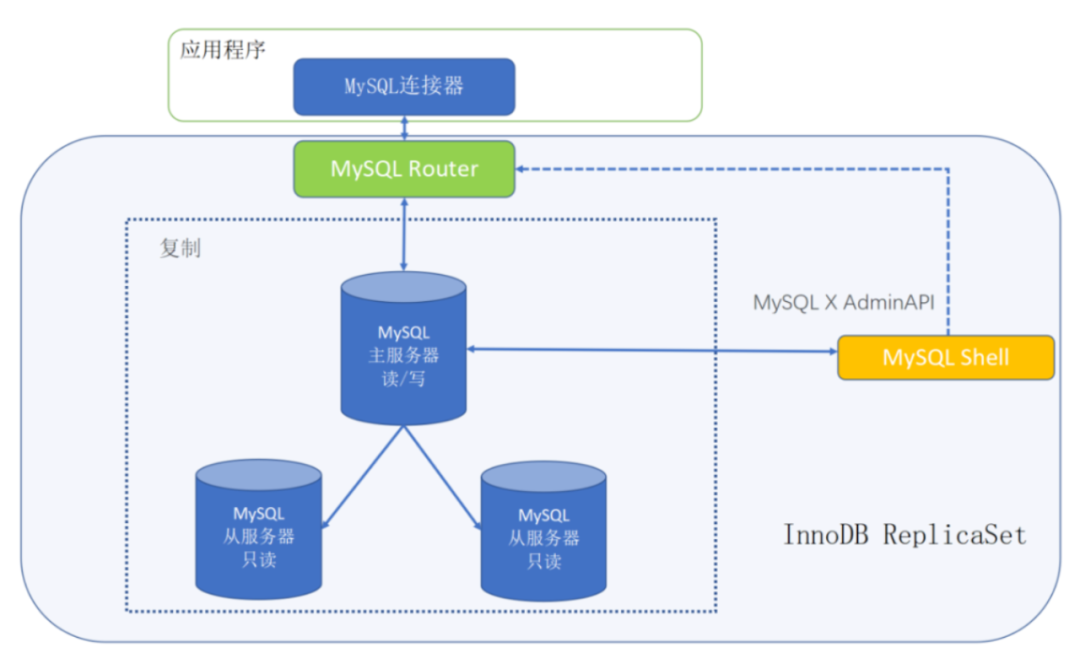
- InnoDB ReplicaSet
相对于InnoDB ClusterSet而言,InnoDB Cluster ReadReplicas的架构更为简单,通过异步复制,提供InnoDB Cluster的一个或多个只读副本,在一些场景上(读写分离等)更便于DBA对MySQL的操作。
配置InnoDB Cluster ReadReplicas非常灵活,用户可以选择InnoDB Cluster中的任意一成员作为副本的复制源,可以是主要成员,也可以是次要成员,当InnoDB Cluster发生故障转移时,副本可以按照事先的配置重新选择正确的复制源。创建和配置只读副本使用如下语句:
Cluster.addReplicaInstance('host4:4110', {label: 'RReplica1', replicationSources: ['host2:4101']})使用该语句的前提是已经利用MySQL Shell创建了一个InnoDB Cluster,并通过Shell获得该集群的对象“Cluster”,之后使用“addReplicaInstance”进行添加。其中的host4是需要添加的副本,host2则为用户选择的复制源。复制源除了直接指定主机名,还可以使用“primary”或“secondary”,例如
Cluster.addReplicaInstance('host4:4110', {label: 'RReplica1', replicationSources: 'primary']}) Cluster.addReplicaInstance('host4:4110', {label: 'RReplica1', replicationSources: 'secondary']})选择“primary”作为复制源时,副本将仅从主要成员进行复制,如果主要成员发生故障转移,则副本等待新的主要成员上线时继续进行复制。
此外,用户也可以配置复制源列表,复制源发生故障时,可以按照用户配置的权重,按序选择复制源。例如,
Cluster.addReplicaInstance('host4:4110', {label: 'RReplica1', replicationSources: ['host2:4101','host3:4102']]})当用户部署一个新的只读副本时,副本可以通过克隆方式接受数据,并能够指定数据源。例如,
cluster.addReplicaInstance('host5:4113',{label: 'RReplica5', recoveryMethod: "clone", cloneDonor: "host2:4101"})用户可以对加入集群后的只读副本进行修改或删除,删除只读副本时,首先,会删除用于从InnoDB Cluster中进行复制的用户,其次,会删除该副本的元数据,最后,停止复制通道,重置该副本的相关变量值。当删除副本时,副本需要将当前的事务与InnoDB Cluster进行同步,用户可以设置超时,如果超时范围内未能结束同步,则删除操作进行回滚,该副本不能删除。
副本如果暂时离开集群后可以通过“ Cluster.rejoinInstance”方法重新加入集群,但需要注意,副本中不能出现与InnoDB Cluster不同的GTID。注意,如果副本已经从集群中删除(集群中不存在该副本的元数据),则该副本无法重新加入,只能将其作为新的副本加入。
只读副本可以通过“Cluster.status()”及“Cluster.describe() ”进行监视,输出信息中包括,角色、状态、地址等信息。例如:
"topology": { "host1:4100": { "address": "host1:4100", "memberRole": "PRIMARY", "mode": "R/W", "readReplicas": { "RReplica1": { "address": "host4:4110", "role": "READ_REPLICA", "status": "ONLINE", "version": "8.1.0" }, "RReplica2": { "address": "host5:4120", "role": "READ_REPLICA", "status": "ONLINE", "version": "8.1.0" }, "RReplica3": { "address": "host6:4130", "role": "READ_REPLICA", "status": "ONLINE", "version": "8.1.0" } }, "replicationLag": "applier_queue_applied", "role": "HA", "status": "ONLINE", "version": "8.1.0" }, { "address": "127.0.0.1:4110", "label": "RReplica1", "replicationSources": [ "PRIMARY" ], "role": "READ_REPLICA" }, { "address": "127.0.0.1:4120", "label": "RReplica2", "replicationSources": [ "PRIMARY" ], "role": "READ_REPLICA" },MySQL InnoDB Cluster Read Replicas的推出,为MySQL又增加了一个高可用性解决方案,用户可以通过它实现读写分离,保存多个数据副本等目的,在一些场景的应用上,又多了一个选择。
感谢关注“MySQL解决方案工程师”
声明:文中观点不代表本站立场。本文传送门:https://eyangzhen.com/251024.html
