
背景
上周线上服务出现一个问题,打开某个页面,会导致其它接口请求响应超时,排查后发现数据库响应超400s,之前1s就可查到数据。
具体原因是有个大屏统计页面,会实时查看各业务服务近几个月的统计数据,根据多个指标统计,最近导入了几千万数据,数据量变大了,之前没数据。
前端页面设置的是5s刷新一次。每次刷新会有十几个SQL发给Mysql执行,导致SQL查询任务在排队执行,所以后面系统其它页面全部不可用,SQL等待超时。
本篇不讨论通过SQL来做统计的合理性。只介绍Mysql诊断分析思路。
诊断分析
客户方Mysql版本8.0.16。
登录数据库服务器
- 登录服务器后
top 命令查询系统负载,发现 Load Average 第一个数值达25,说明系统在过去一分钟超过25个任务在等待执行。 - Mysql进程当前占用cpu达
260%(linux服务器有12核cpu)。 - 登陆Mysql实例,执行
show processlist查看活动连接,看到有400多个线程(大部分是 sleep 状态),其中几十个线程在等待执行 SQL,有的连接 Time 达到了1400多秒。 show global status like '%Thread%'; 查看同时有40多个活跃线程正在执行。- 捕获问题 SQL 语句。通过
explain 分析 SQL发现基本走的全表扫描。对一张业务表通过 A 业务字段 去分组统计每天的值、每个月的值,这个 A 存储的值离散度很低。所以查询很慢,请求多了,就阻塞了。
解决方案:
kill掉耗时长的 SQL 线程,等待一会后再次通过 top 命令查看 cpu 使用率恢复正常;- 针对问题 SQL 中 某些字段
加索引(离散度低,全表统计,所以效果不明显); - 和产品确定相关业务,定下来是
代码加缓存,统计数据延迟更新,不实时加载; - 通过
慢日志定位慢 sql,找到时间长的 sql,逐个优化。
Mysql 参数调优
参数优化对 Mysql 性能也非常重要,合理配置参数,可以提升 Mysql 的性能和稳定性。
- 调大缓存池(
InnoDB Buffer Pool):默认128M,通常设置机器内存的50-80%,假如机器内存是10个G,设置5G-8G是合理的,根据机器负载及运行的服务来定。 - 调整
innodb_log_file_size参数:该参数表示redo log的日志大小,此值太小会造成日志的频繁切换;值太大,数据库恢复时,会占用更多时间。推荐256M ~ 1GB。 - 设置
max_connections值:该值用于设置数据库服务器同时允许的最大连接数,我通常设置在1500左右; wait_timeout参数配置:表示连接最长空闲时间,默认8小时,超过8小时 Mysql 则关闭该连接。建议设置 1800秒。interactive_timeout 和 wait_timeout要设置一致,分别代表交互式等待时间和非交互式等待时间。
命令详解
show processlist;
查看活动连接和查询执行的命令。
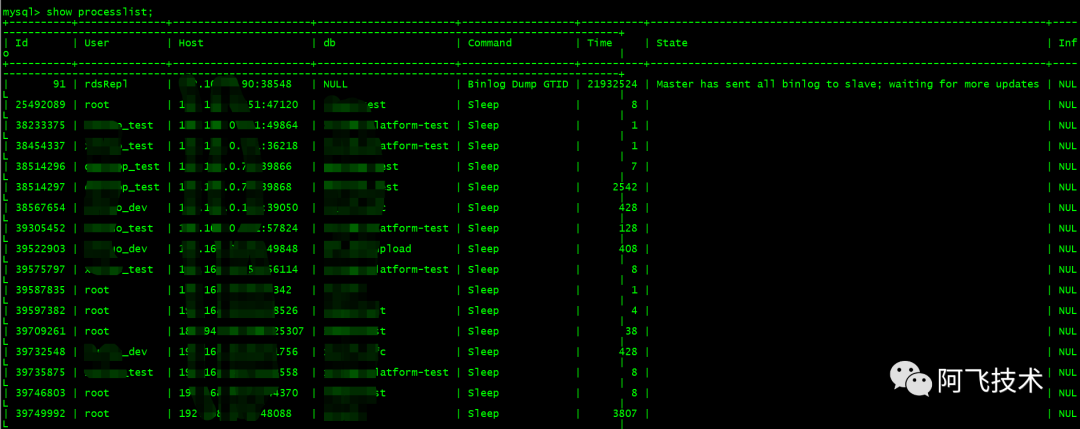

show full processlist命令可以看到完整的SQL语句信息。
返回的信息:
- Id: 连接的唯一标识符。
- User: 连接的数据库用户。
- Host: 连接的客户端主机名或 IP 地址。
- db: 连接正在使用的数据库。
- Command: 连接当前正在执行的命令类型,如 Query、Sleep、Connect 等。
- Time: 查询已经执行的时间(秒),用于判断是否有长时间运行的查询。
- State: 表示连接状态,例如 Sending data、Waiting for table lock 等。
- Info: 正在执行的查询文本,可以看到具体的 SQL 查询。
Command 状态及含义:
- Sleep:连接处于空闲状态,没有正在执行的查询。
- Query:连接正在执行一个查询语句。
- Execute:连接正在执行一个准备好的语句(prepared statement)。
- Connect:正在与数据库建立连接。
- Init DB:正在初始化数据库连接。
- Quit:连接正在关闭。
- Statistics:正在收集数据库统计信息。
- Binlog Dump:正在复制二进制日志。
- Table Dump:正在导出表数据。
- Close:连接正在关闭。
- Change User:正在更改连接的用户。
- Ping:连接正在执行心跳检测。
- Kill:正在终止一个连接。
- Delayed insert:正在执行延迟插入。
- Change master:正在更改主服务器信息。
- Prepare:连接正在准备一个语句。
- Daemon:MySQL 服务器内部的守护进程或后台线程。
State 状态及含义:
- Sending data:连接正在发送数据到客户端,通常意味着查询正在执行,并且结果集正在被发送。
- Waiting for table lock:连接正在等待获取某个表的锁,可能由于其他并发查询正在使用该表而导致阻塞。
- Locked:连接被锁定,可能由于其他并发操作或事务而导致。
- Copying to tmp table:连接正在将数据复制到临时表,通常在使用临时表进行排序或分组时出现。
- Repair by sorting:连接正在执行表的修复操作,并使用排序算法进行修复。
- Repair with keycache:连接正在执行表的修复操作,并使用键缓存进行修复。
- Sorting result:连接正在对结果集进行排序。
- Creating sort index:连接正在创建用于排序的索引。
- Sending cached result:连接正在发送缓存的结果集。
- Converting HEAP to MyISAM:连接正在将 HEAP 表转换为 MyISAM 表。
- Waiting for tables:连接正在等待所有表被锁定,通常在执行复杂查询时出现。
- Opening tables:连接正在打开表,通常在查询开始时出现。
- Init:连接刚刚创建,还没有开始执行任何操作。
- Killed:连接的查询被管理员或其他进程终止。
- starting:连接开始的状态(瞬时的,表示连接准备好执行查询或操作)。
- Waiting on empty queue:表示一个等待连接的线程在等待事件队列为空。(通常会后台线程完成任务后进入此状态)
- Sending to client:是一个连接线程的状态,表示该连接正在将查询结果数据发送给客户端。
Top命令

前五行是系统整体的统计。
第一行:top表头
- top:显示 top 命令当前的运行时间。
- up:表示系统的运行时间。格式为:天-小时:分钟。
- 3 users — 当前有3个用户登录系统。
- load average:平均负载。分别表示系统在过去 1 分钟、5 分钟和 15 分钟内的平均负载。
Load Average 表示系统在不同时间间隔内的平均负载情况。
第一个数值(0.01):在过去1分钟内,系统的平均进程等待数为0.01。
第二个数值(0.03):在过去5分钟内,系统的平均进程等待数为0.01。
第三个数值(0.08):在过去15分钟内,系统的平均进程等待数为0.05。
之前SQL排队的问题情况下,第一个数字到了25,意味着在过去1分钟内,系统的平均进程等待数为25。这样的负载是非常高的,表示系统在这段时间内有大量的进程在等待CPU资源,系统可能会响应缓慢甚至出现性能问题。
第二行:任务(进程)
- total:系统中的总进程数。
- running:当前正在运行的进程数。
- sleeping:当前休眠的进程数。
- stopped:停止的进程数。
- zombie:僵尸进程数。
系统共有244个进程,其中处于运行中的有1个,242个在休眠(sleep),stoped状态的有1个,zombie状态(僵尸)的有0个。
第三行:CPU 使用情况
- us:用户态使用 CPU 的百分比。
- sy:系统态使用 CPU 的百分比。
- ni:修改过优先级的进程使用 CPU 的百分比。
- id:空闲 CPU 百分比。
- wa:等待磁盘 I/O 的 CPU 百分比。
- hi:硬中断(Hardware IRQ)占用CPU的百分比。
- si:软中断(Software Interrupts)占用CPU的百分比。
- st:虚拟机等待CPU时间的百分比(也就是宿主机从当前虚拟机偷取的CPU时间)。
第四行:KiB Mem(内存使用情况)
- total:总内存量。
- used:已使用的内存量。
- free:空闲内存量。
- buffers:用于缓冲的内存量。
- cached:用于缓存的内存量。
24521472k total — 物理内存总量(23.38GB)。
4434672k used — 使用中的内存总量(4.23GB)。
10843452k free — 空闲内存总量(10.34G)。
9243348k buffers — 缓存的内存量(8.81GB)。
第五行:KiB Swap(交换空间使用情况)
- total:总交换空间大小。
- used:已使用的交换空间大小。
- free:剩余的交换空间大小。
- available:可用的交换空间大小。
5242876k total — 交换区总量(5GB)。
4615932k used — 使用的交换区总量(4.40GB)。
626944k free — 空闲交换区总量(612MB) 13232772k cached — 缓冲的交换区总量(12.61GB)。
各进程(任务)的状态监控
- PID:进程ID。
- USER:进程所有者。
- PR:进程优先级。
- NI:nice值。负值表示高优先级,正值表示低优先级。
- VIRT:进程使用的虚拟内存总量,单位kb。
- RES:进程使用的、未被换出的物理内存大小,单位kb。
- SHR:共享内存大小,单位kb。
- S:进程状态。D(不可中断的睡眠状态)、R(运行)、S(睡眠)、T(跟踪/停止)、Z(僵尸进程)。
- %CPU:进程当前占用CPU资源的百分比。
- %MEM:进程当前使用的物理内存百分比。
- TIME+:进程使用的CPU时间总计。
- COMMAND:进程名称(命令名/命令行)。
图中 mysql进程 TIME+ 列显示:140129:37 ,表示进程在CPU上的累计运行时间为 140129 分钟 37 秒。
总结
本篇只介绍了 top 命令,我们还可以用 vmstat 和 mnon 来监控系统性能。
vmstat:
用于查看系统虚拟内存和系统资源使用情况的命令。它提供了对系统内存、CPU、交换空间等性能指标的实时监控。
mnon:
是一个虚拟内存性能监控工具,它用于监控和诊断 Linux 系统上的内存和交换空间使用情况。
声明:文中观点不代表本站立场。本文传送门:https://eyangzhen.com/260902.html
