
前言
如果只需要代码可以跳转到最后一步(记着更换商品ID和评论页的的页数)
话不多说,直接开干!
文章所提供的代码不能用于商业用途 仅建议学习交流使用 否则后果自负
部分代码来源于网络 如有侵权私我立删 谢谢
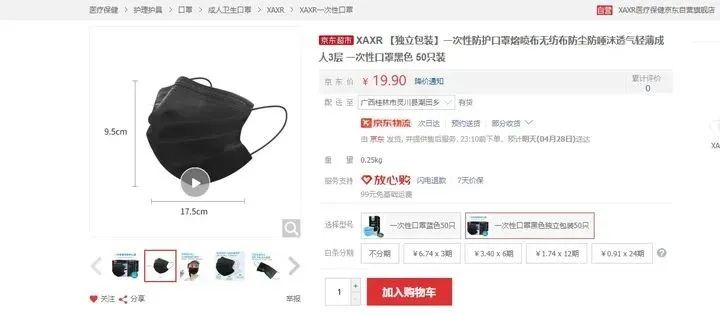
今天要干的活
京东某口罩产品的全部评价,要爬取的数据

最终结果
遇到问题(重点!!)
今天使用的方法就是用requests请求获取页面数据 返回并且分析其结果。
今天的重点在于京东商品全部评价的问题。我们今天要爬取的这个商品评论显示的数据为10w+的 但是我们会发现 一个页面只有10条 就算显示全部页面也只有100页 那么就是1000多条 那么!剩下的数据 去了哪里呢??你品 你细品??
我在网上查阅了很多资料 发现很多博主都是直接爬取100页 这样将会导致数据的不完整。最终我在csdn网站上一位博主的文章下面发现了此问题的解决方法(真的很强)
链接:https://blog.csdn.net/hgjiayou/article/details/109777572.
我总结下此文章的内容!
假如一个商品全部评论数据为20w+ 默认好评15w+ 这15w+的默认好评就会不显示出来。那么我们可以爬取的数据就只剩下5w+ 接下来 我们就分别爬取全部好评 好评 中评 差评 追加评价 但是就算这些数据加起来 也仍然不足5w+ 上文的博主猜测可能有两点原因:
1.出现了数据造假,这个数字可能是刷出来的(机器或者水军)
2.真的有这么多的评论,但这时候系统可能只显示其中比较新的评论,而对比较旧的评论进行了存档。
在博主理论的基础上我也进行了很多相应的测试,就是说无论如何 我们最终都爬不到剩下的5w条数据 只能爬取一部分但这一部分数据也将近上千多条 如果有小伙伴能爬取下更多欢迎补充。
整体思路
全部评价 好评 中评 差评 追加评价的网址都是涉及到一定的参数的 只要修改网页的数据, 修改遍历页码 即可完成全部的爬取。
分析URL
我们首先解析全部数据中的url 其实大家爬虫写多了就会知道 东京 淘宝这些页面的数据绝对不可能requests请求获取完毕的 所以我们将从json文件中下手。
先复制一条全部评论的数据–》F12–》网络–》Ctrl+f 粘贴一条评论上去 可以发现显示出一个对应的网址 打开其url查看数据
其实这是一个特别的json文件 所以浏览器的json插件没给我们直接按标准格式显现出来。需要我们手动打开http://json.cn网址 将这些内容复制上去 注意因为不是标准格式所以需要删除开头的fetchJSON_comment98(【注意 !!这里也要删除那个小括号】和结尾的);
真的亲妈级的教程了, 手把手教(忽略我的不要脸)
所以我们发现https://club.jd.com/comment/productPageComments.action?&productId=100008054085&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1这个就是对应评论的url了 。
接下来我将解释其中的重要参数。
productid相当于 你在京东买XR苹果手机 有黑色 白色 银色等 一个颜色分类就对应一个ID 但其实这个并不重要 无论产品分类id如何 都不影响数据的多少。
page为其对应的页码数 需要注意的是 不是所有评价页面都有100页的
score表示为评论的数据类型 如 0全部评价 1好评 2中评 3差评 5追加评价
说到这一部分 相信大家聪明的小脑瓜子应该知道怎么写了吧。我们只需要依次修改score抓取其下全部数据即可
函数:发起请求到京东并获取特定页面的数据
def start(page):
# 构建京东商品评论页面的URL
url = (‘https://club.jd.com/comment/productPageComments.action?’
‘&productId=100041430694’ # 商品ID
f’&score=0′ # 0表示所有评论,1表示好评,2表示中评,3表示差评,5表示追加评论
‘&sortType=5’ # 排序类型(通常使用5)
f’&page={page}’ # 要获取的页面数
‘&pageSize=10’ # 每页评论数
‘&isShadowSku=0’
‘&fold=1’)
# 设置headers以模拟浏览器请求
headers = {
"User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Mobile Safari/537.36"
}
time.sleep(2)
# 发送GET请求获取数据
response = requests.get(url=url, headers=headers)
# 将返回的JSON数据解析为字典
data = json.loads(response.text)
return data解析页面
大家其实写多了就会知道 其实json格式下数据的提取是很容易的 这里就不解释啦。有问题可以评论区告诉我 身在伯明翰的我还是会尽力回大家消息的
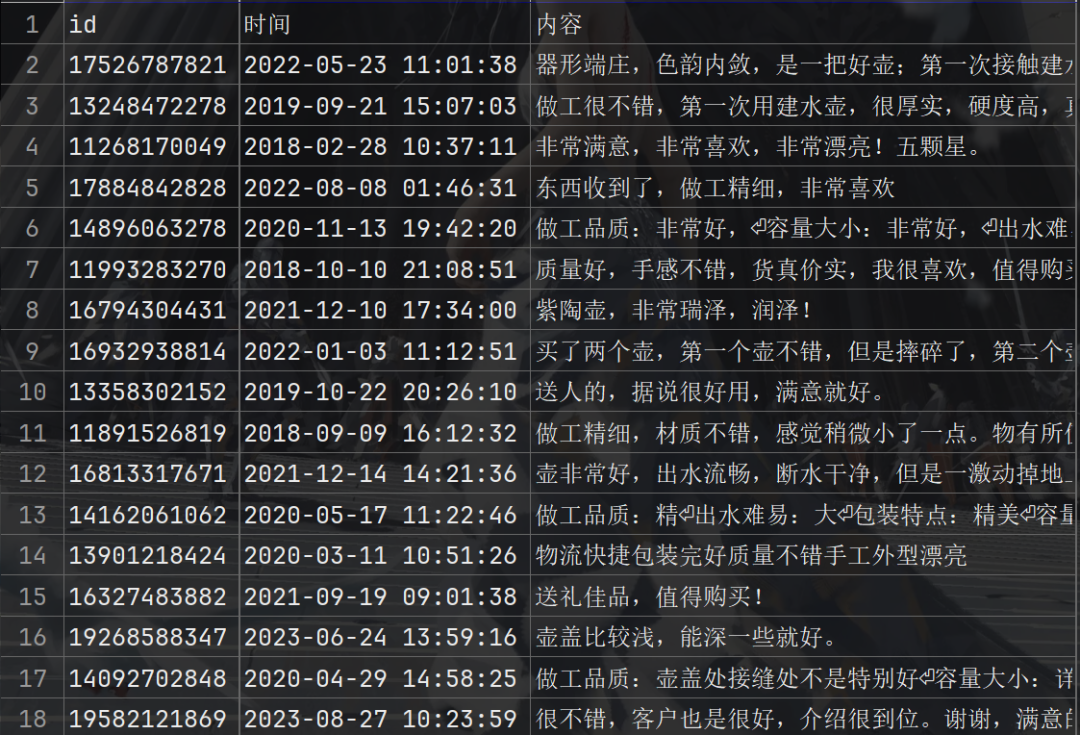
处理好的数据 为标准json格式
解析函数:从返回的数据中提取所需信息
def parse(data):
items = data[‘comments’]
for i in items:
yield (
i[‘id’],
i[‘creationTime’],
i[‘content’]
)
写入文件
CSV函数:将数据写入CSV文件
def csv(items, file_path=’建水紫陶.csv’):
# 如果文件不存在,创建文件并写入列名
try:
pd.read_csv(file_path)
except FileNotFoundError:
df = pd.DataFrame(columns=[‘id’, ‘时间’, ‘内容’])
df.to_csv(file_path, index=False, encoding=’utf-8′)
# 将数据写入CSV文件,header参数用于控制是否写入列名
df = pd.DataFrame(items, columns=['id', '时间', '内容'])
df.to_csv(file_path, index=False, mode='a', header=False, encoding='utf-8')总代码
导入必要的库
import requests
import json
import time
import pandas as pd
函数:发起请求到京东并获取特定页面的数据
def start(page):
# 构建京东商品评论页面的URL
url = (‘https://club.jd.com/comment/productPageComments.action?’
‘&productId=100041430694’ # 商品ID
f’&score=0′ # 0表示所有评论,1表示好评,2表示中评,3表示差评,5表示追加评论
‘&sortType=5’ # 排序类型(通常使用5)
f’&page={page}’ # 要获取的页面数
‘&pageSize=10’ # 每页评论数
‘&isShadowSku=0’
‘&fold=1’)
# 设置headers以模拟浏览器请求
headers = {
"User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Mobile Safari/537.36"
}
time.sleep(2)
# 发送GET请求获取数据
response = requests.get(url=url, headers=headers)
# 将返回的JSON数据解析为字典
data = json.loads(response.text)
return data解析函数:从返回的数据中提取所需信息
def parse(data):
items = data[‘comments’]
for i in items:
yield (
i[‘id’],
i[‘creationTime’],
i[‘content’]
)
CSV函数:将数据写入CSV文件
def csv(items, file_path=’建水紫陶.csv’):
# 如果文件不存在,创建文件并写入列名
try:
pd.read_csv(file_path)
except FileNotFoundError:
df = pd.DataFrame(columns=[‘id’, ‘时间’, ‘内容’])
df.to_csv(file_path, index=False, encoding=’utf-8′)
# 将数据写入CSV文件,header参数用于控制是否写入列名
df = pd.DataFrame(items, columns=['id', '时间', '内容'])
df.to_csv(file_path, index=False, mode='a', header=False, encoding='utf-8')主函数:控制整个爬取过程
def main():
total_pages = 4 # 设置要爬取的总页数
for j in range(total_pages):
time.sleep(1.5)
current_page = j + 1
# 发起请求并获取数据
data = start(current_page)
# 解析数据
parsed_data = parse(data)
# 将数据写入CSV文件
csv(parsed_data)
print('第' + str(current_page) + '页抓取完毕')如果作为独立脚本运行,则执行主函数
if name == ‘main‘:
main()
最后
理性交流学习,看到这里了,麻烦动动你的小手给我点点赞吧!
声明:文中观点不代表本站立场。本文传送门:https://eyangzhen.com/412988.html



