
上一篇提示工程Prompt Engineering中介绍了提示,提示只是更改了LLM的输入,提示对于词汇的分布非常敏感,一个小的提示变化可能会对词汇的分布产生很大的变化。由于模型的参数是固定的,通过单独使用提示,我们可以更改模型在词汇上的分布程度,但当我们希望在一个全新领域使用一个在其他领域上训练的模型时,仅使用提示无法满足我们的要求。与提示相反,在训练的过程中,我们实际上要修改模型的参数。可以简单的理解为,训练是为模型提供输入的过程,模型猜测出一个对应的输出,然后基于这个输出答案,我们更改模型的参数,令下一次的输出更加接近正确的答案。
模型训练是改变词汇分布的一个更重要的方法,从零开始训练一个模型需要耗费大量的成本,对于一般用户来说是不可能完成的任务。用户通常会使用一个已经在大规模数据上训练好的预训练模型进行进一步训练,这个预训练模型可能是在一个通用任务或数据集上训练得到的,具有对一般特征和模式的学习能力。训练的类型通常包括Fine-tuning、Prarm. Efficent FT、Soft prompting,及Continue pre-training等。
- Fine-tuning:微调会采用预先训练的模型(例如,BERT)和带有标签的数据集对全部的参数进行调整,是经典的机器学习训练方法。
- Prarm. Efficent FT:通过将一组非常小的参数隔离起来进行训练或者向模型中添加一些新参数,可以降低训练成本。(例如,LORA)
- Soft prompting:将参数添加到提示中,可以将其视为利用专门的引号将词汇添加到模型中,以执行特定的任务。与提示不同,添加到提示中的那些专门词汇的参数是在训练期间随机初始化并迭代微调的。
- Continue pre-training:类似于微调,但不需要使用标签数据。在持续的预训练期间,输入任何类型的数据,并要求模型不断预测下一个词汇。如果尝试将一个模型适应一个新的领域,例如,从一般文本到专门的科学领域,通过不断进行预训练,预测来自该专业科学领域的数百万句中的下一个词汇可以非常有效。
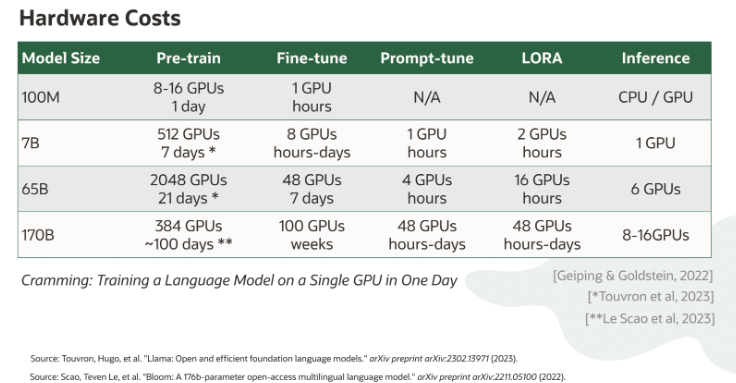
训练成本
模型训练需要耗费硬件成本,最后给出一个基于OCI的不同训练方法的硬件成本。

感谢关注“MySQL解决方案工程师”!
声明:文中观点不代表本站立场。本文传送门:https://eyangzhen.com/417678.html
