
随着rust的对产品安全特别是内存安全的大幅提升,其获得越来越广泛的应用。
我们看看谷歌安卓10-13中rust在总代码中占比的变化:
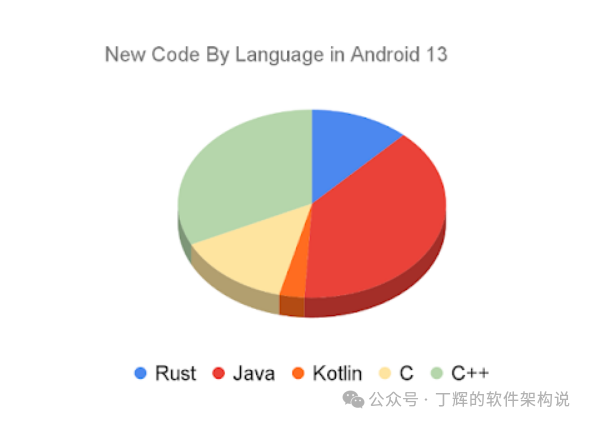

在 Android 13 中,大约 21% 的新原生代码 (C/C++/Rust) 都是用 Rust 编写的。
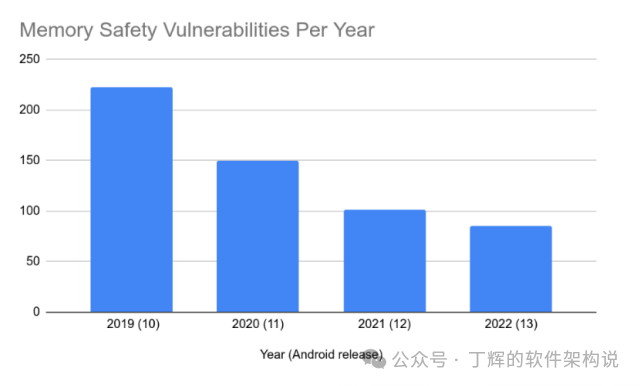
随着rust占比的提升,内存安全漏洞数量也相应从 223 个下降到 85 个,下降了60%以上。
绝大多数情况下,都可以使用混合编程的方式进行,对于新增系统或新增模块,可以使用rust开发,存量功能仍用c/c++。
但是对于有些对产品安全较高的产品,可能需要更高比例的rust开发。这就需要新产品把继承的老系统中海量的存量c代码转换为rust,这部分工作量非常巨大,在没有巨额的人力投入的情况,几乎是不可能完成的工作。
目前业界比较主流的方式是采用工具进行c2rust的转换,但从公开资料和我们试用的情况看,效果都不是很明显。
我们对c2rust最新版本做了穿刺,选择把c语言的json-c模块转换成rust。
可以看出,转换后的rust有以下问题:
- 正确性:.转换后的代码无法正确编译
- 可读性:转换后的代码可读性比较差,违背了rust的设计
- 安全性:转换后的代码几乎全部是unsafe块,unsafe代码是不进行rustc编译器检查的,安全性降低。
可以看到工具转换效果基本不可用。
目前大模型在很多跨语言的代码转换中都做了不少的应用,那能不能借助大模型进行c2rust的转换呢?
我们先设定转换目标:
目标主要体现c2rust转换的效率和质量。
效率很好理解,质量包括外部质量和内部治理,外部质量表征功能正确性,内部质量则表达了其易于维护的程度。
内部质量我们一般用AEI指数来表征。AEI指标-架构度量指数,600分是及格,800分是优秀。
其中代码级指数主要表征代码的可维护性,关键要素为代码评价圈复杂度和重复度;组件级指数主要表征系统中所有组件的分层和依赖关系(无反向依赖和违规依赖)。
整体思路就是c-》DDD-》代码这样一条路径。实现层面主要考虑分别从c-》DDD和DDD-》rust两个方向进行。其中后半段也可以兼顾新功能生成rust代码。
整个过程其实是从细节-》抽象-》细节的过程。对应到本课题,就是代码-》模型-》代码转化的过程,其本质是业务语义层次抬升和降解的过程。
这个过程很像民航的飞机的起落过程,上升和降落的阶段都是有个盘旋的过渡阶段,让乘客逐步适应这一过程,从而获得更好的感受和体验。
代码到模型的过程同样是语义抬升的过程,这个怎么理解呢?我们举个例子,如果用汇编语言写一个while循环,其中的控制语义就需要mov、add、test、jump等多个指令组合实现;而使用c语言控制语义只需要一个while语句就能实现,这个就是语义的抬升。
同理,从ddd-》rust代码过程,就是抬升的一个逆操作还原,是语义逐层降解的过程。
无论是语义抬升还是语义降解,越是层次拆分的细致,上下的过程越是平缓,层与层直接的step越小,实现的复杂度越小,整个过程的可理解性越强。
针对c2ddd2rust的语义抬升和降解的过程,我们总结了c2rust 4步转换法,见下图:
我们都知道,并行开发,接口先行。这里的接口就是语义抬升和降解的交汇点-ddd模型。
如何充分表达ddd模型中的细节,并且要足够严谨和形式化是关键,既要人易于理解,又可以程序易于识别,这块是整个过程成败的关键。
这里我们设计了一整套ddd细粒度模版,用来承载和表达ddd模型、业务对象、业务行为和约束,如果需要的可以和我私下联系。
一、语义抬升
1、抽取统一语言
上图最左端为存量c语言遗留代码,一般都是代码长期腐化,圈复杂度和重复度都很高,代码层次之间互相依赖、循环依赖严重,往往都是以大泥球的面目出现。
我们首先使用大模型把遗留代码中的词汇抽取出来,再根据语义相似或功能相同把词汇进行进行合并,形成统一语言。
统一语言是由名词、动词(含动宾)组成,来自于代码中的目录名、文件名、结构体名、字段名、类名、函数名、函数名中的宾语等。
2、领域建模
a、名词
把统一语言中的名词抽取出来,名词按粒度分为两层:
上层为high level概念,对应ddd建模中的领域、子域、bc、bc map等。
下层为领域核心概念,对应ddd建模中的聚合、实体、值对象、属性等,另外需要找出核心概念间的关系,比如继承、关联、依赖、组合等,以及关系的数量对比,比如一对一、一对多、多对多等。
上层概念统帅下层概念,下层概念组成上层概念,形成层次结构。
b、动词
动词为领域中的行为,按粒度从上到下分别为:应用服务、领域服务和对象职责三个层,相互直接也是以上统下,上层调度编排下层,形成业务功能。
上层调度编排下层也有三种关系,分别为自担-即独立完成业务功能;委托-调用下层行为完成业务功能;协作-即自己完成部分功能,委托别人完成部分功能,然后再进行融汇组合,最终完成业务功能。
这里其实也是TDA原则的集中体现,让每个领域对象都完全承担自己名称相对应的职责,然后通过上层行为进行调用编排形成整个业务功能,这样代码的才是高内聚低耦合的代码,才能易于维护易于理解。
最后重塑成ddd细粒度模版的模型,作为下一阶段工作的的输入。
这一过程可以把大模型生成ddd细粒度模型和人工建模的ddd细粒度模型进行对比,从而实现这一阶段的评测。
当然模型最终的准确性还要参考生成代码的最终外部质量和内部质量进行评估。
二、语义降解
ddd2rust中的业务语义通过ddd-》开发框架-》代码的方式降解。
1、ddd-》开发框架
首先通过ddd细粒度模型中静态部分使用大模型生成整个开发框架,包括目录(分层架构、模块)、文件(聚合、实体、值对象)、业务行为(应用服务、领域服务、对象贴身职责)的函数签名。
其次使用ddd细粒度模型的动态部分生成整个业务行为的实现摘要,包括每个步骤的实现注释和框架。
2、开发框架-》rust代码
这又是一个语言逐层降解的过程。具体做法就是通过测试用例来逐层降解语义。
首先使用大模型通过函数签名生成测试用例,然后人工走查测试用例(测试用例都是顺序编程,可理解性比较强,相对比较容易看懂)。
接下来有两个方式实现代码:
i、通过测试用例生成代码,然后用copilot进行完善。
ii、通过存量代码根据函数签名生成实现代码,然后用copilot进行完善。
最后,使用测试用例验收生成实现代码。
三、效果评估
转换效果如何评测呢?这就是大模型相关应用的关键,任何一个大模型相关的应用要想做好,都要提前设计后评测体系和评测用例,然后用用例来驱动的应用的效果。
参照上图,首先要保证功能的正确性,即利用已有的c代码的FT测试框架和测试用例,和重构后的rust静态库和动态库进行link生成测试exe,并100%通过测试。
有的同学可能会有疑问,就是存量c的FT用例调用是c的接口,rust是不是要把外部接口全部对齐?这里可以采用皮下测试的方式,即外部接口还是c/c++的,而领域实现是rust,通过c/c++的 DTO的方式进行调用。
其次利用存量代码中的st进行对外暴露的协议进行测试,使其100%通过测试。
最后通过领域模型生成新的Rust ut,并100%通过。
小结
使用大模型把存量c语言转换成rust的过程本质就是一个业务语义逐步抬升和降解的过程。首先通过存量c代码-》统一语言-》领域对象-》领域行为-》DDD细粒度模型这一过程进行语义抬升;然后通过DDD细粒度模型-》开发框架-》测试用例-》实现代码这一过程进行语义的降解。最后依赖存量UT/FT/ST测试用例进行最终验收,从而完成整个转换。
当然,按这个思路进行其他两种语言的互转,或者就是同一种语言的依赖腐化代码重构也同样可行。
我们已经在实际项目中验证了这一过程,希望能给大家带来启示。
另外,目前很多项目应用大模型都想尝试通过需求直接就到rust代码,即0号员工或编程机器人的思路,其实也可以通过把特定场景的需求,通过自动或人工修订的方式,转换成我们ddd细粒度模版,然后通过模板生成开发框架,再通过签名自动生成测试用例和实现代码,最后进行用例验证和人工走查的方式保障其正确性,可以使我们尽可能多的提升自动化的占比。
声明:文中观点不代表本站立场。本文传送门:https://eyangzhen.com/424414.html
