


1,复制功能可以在不同的操作系统上使用吗?

可以,复制功能可以在不同的操作系统上面共同使用。
2,复制功能可以在不同架构的硬件上使用吗?
可以,可以在32位或64位架构的系统上共同使用。
3,主从复制时,从服务器必须总是连接到主服务器吗?
不是。从服务器与主服务器的连接可以断开,当重新连接主服务器,从服务器会追赶主服务器上的更新。主从复制依赖于服务器上面的二进制日志,当从服务器能够从最后读取事件的位置继续读取二进制日志时复制才能工作。因此,必须保证主服务器中尚未复制到从服务器二进制日志文件没被删除,才可以使断开的从服务器重新连接主服务器继续进行复制。
4,如何知道从服务器落后于主服务器多少?
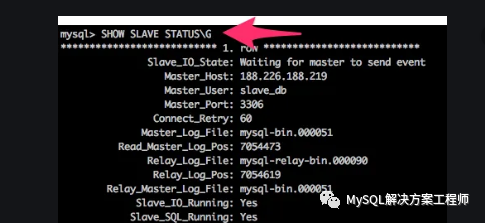
执行SHOW SLAVE STATUS 语句,确认Seconds_Behind_Master 列的信息。
5,是否可以强制主服务器阻止更新,直到从服务器赶上为止?
可以,执行如下步骤:
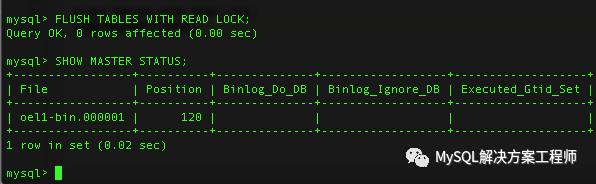
a.在主服务器上执行:
mysql> FLUSH TABLES WITH READ LOCK;
mysql> SHOW MASTER STATUS;
b.在从服务器上执行下面的语句,函数的值使用上面输出里面相对应的值。
mysql> SELECT MASTER_POS_WAIT(‘log_name’, log_pos);
SELECT语句被阻塞,直到从服务器到达指定的日志文件和位置后,从服务器与主服务器保持同步,语句返回。
c.主服务器上,执行下面的语句,恢复更新处理:
mysql> UNLOCK TABLES;
6,搭建双向复制时应该注意哪些问题?
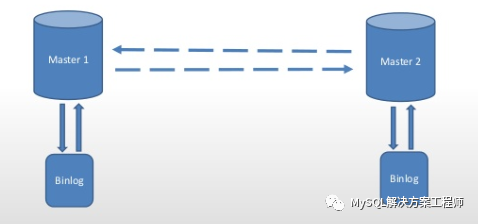
MySQL的主从复制目前不支持主服务器和从服务器之间的任何锁协议,无法保证分布式(跨服务器)更新的原子性。假设客户端A对服务器1进行更新,同时,在它传播到服务器2之前,客户端B可以对服务器2进行更新,这使得客户端A的更新与对服务器1的更新不同。因此,当客户端A更新到服务器2时,它生成的表与服务器1上的表不同。这意味着以双向复制关系会具有非常大的风险——破坏数据的一致性,除非确保更新可以以任何顺序安全地进行,或者以某种方式在客户端的代码中处理。此外,就更新而言,双向复制实际上并没有显著提高性能。每个服务器必须执行相同数量的更新,就像单个服务器所做的一样。惟一的区别是锁的争用要少一些,因为源自另一台服务器的更新是在一台从服务器线程中序列化的。但这种好处也可能被网络延迟所抵消。
7,如何利用复制改善系统性能?
可以将一台服务器设置为主服务器,并将所有写入指向它。然后在允许的范围内配置尽可能多的从服务器,并在主服务器和从服务器之间分配读操作。还可以使用–skip-innodb选项启动从服务器,启用low_priority_updates系统变量,并将delay_key_write系统变量设置为ALL,用以提升从服务器端速度。
对于处理频繁读取和少量写入的系统,MySQL复制是最有效的。理论上,使用一主多从的设置,可以添加更多的从服务器来扩展系统,直到耗尽网络带宽,或者写入负载增长到主服务器无法处理它的程度。
如果想要确定使用多少台从服务器可以提升性能,用户必须了解系统的查询模式,并对主服务器和从服务器上的读写吞吐量之间的关系进行基准测试。
假设系统负载由10%的写入和90%的读取组成,我们通过基准测试确定 R =1200 – 2 *W。(R 和 W 代表每秒的读取和写入次数)换句话说,系统可以在不进行写入的情况下每秒读取1200次,平均的写入速度是平均读取速度的两倍时长,并且关系是线性的。假设主服务器和每个从服务器的性能相同,我们有一个主服务器和N个从服务器。每台服务器计算下面的等式:
R = 1200 – 2 * W
R = 9 * W/ (N + 1) (10%写,90%读。读取被拆分,写入被复制到所有从服务器。)
9 * W / (N + 1) + 2 * W = 1200
W = 1200 / (2 + 9/(N + 1))
最后一个等式表示了N个从服务器的最大写入次数,给定最大可能的读取速率为每秒1,200次,每次写入的读取次数为9次。
通过分析可以得出以下结论:
如果N=0,表示没有使用复制功能,系统每秒可以处理1200/11=109次写操作。
如果N=1,系统每秒可以处理184次写操作。
如果N=8,系统每秒可以处理400次写操作。
如果N=17,系统每秒可以处理480次写操作。
当N趋于无穷大时,我们可以非常接近每秒600次写操作,将系统吞吐量提高约5.5倍。然而,在只有8台服务器的情况下,我们将其增加了近4倍。
这些计算假定网络带宽是无限的,因而忽略了其他几个可能对系统很重要的因素。在大多数情况下,用户可能无法执行类似的计算,但该计算可以准确地预测如果添加N个从服务器将会在系统上发生什么。
考虑以下问题可以帮助决定复制是否会改善系统的性能,以及在多大程度上改善系统的性能:
a.系统的读/写比率是多少?
b.如果减少读操作,一台服务器可以处理多少写负载?
c.网络上有多少个从服务器可用带宽?
8,如何使用复制功能提供高可用性?
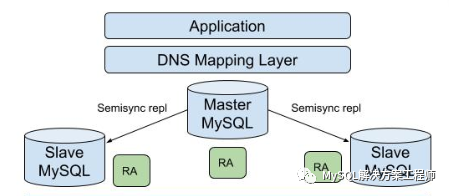
如何实现冗余取决于应用程序和系统环境。
高可用性解决方案(带有自动故障转移)需要系统监视工具、自定义脚本或中间件来提供从MySQL主服务器到从服务器的故障转移。MySQL Router可以提供故障转移。
如果要手动处理这个过程,可以通过修改应用程序,让其与新MySQL服务器通信,或者将DNS从宕机的服务器调整到新的服务器。
9,如何防止 GRANT 和 REVOKE 语句复制到从服务器?
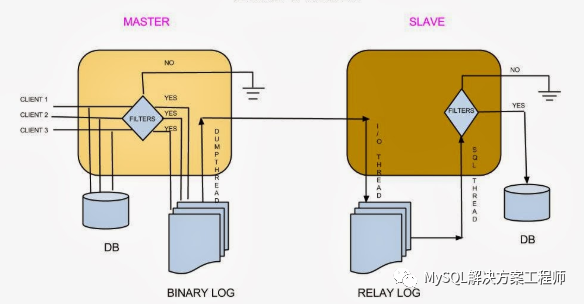
启动服务器时,使用–replicate-wild-ignore-table=mysql.% 选项,可以忽略复制 mysql 数据库下面的表。
10,如何知道从服务器复制最后一条语句的时间?
当从服务器的SQL线程执行从主服务器获得的事件时,它用事件的时间戳修改自己的时间。( 这也是 TIMESTAMP 可以复制的原因。) 在 SHOW PROCESSLIST 输出的 Time 列中,从服务器SQL线程所显示的秒数是上次复制事件的时间戳与从服务器的实际时间之间的秒数。可以使用它来确定最后一次复制事件的时间。假设从服务器与主服务器断开连接一个小时,然后重新连接,可能会在 SHOW PROCESSLIST 的 Time列看到类似 3600 这样的大时间值,这是因为从服务器正在执行一个小时前的语句。
声明:文中观点不代表本站立场。本文传送门:https://eyangzhen.com/191054.html


