
2012年12月,最新一届ImageNet的获胜者出炉,深度学习大神Hinton及其弟子带着卷积神经网络AlexNet,将识别正确率一举提高到了84%,由此开启了之后十年的AI革命。
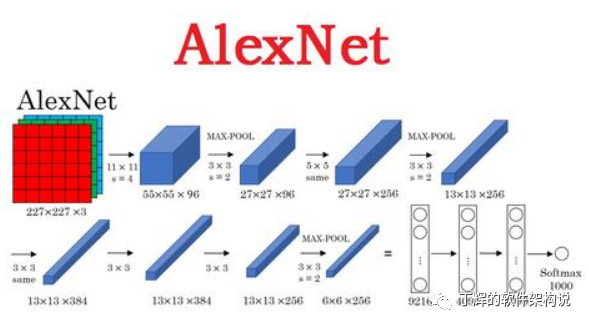

让业内震惊的不只是ImageNet模型本身。这个需要1400万张图片、总计262千万亿次浮点运算训练的神经网络,一个星期的训练过程中仅用了四颗英伟达Geforce GTX 580。作为参考,上一任冠军谷歌猫识别率74.8%,谷歌猫用了1000万张图片、16000颗CPU、1000台计算机。
GPU是何方神圣,可以有如此高的魔力?
NVIDIA于1999年8月正式发布第一个GeForce产品——GeForce 256,GPU这个词汇也是由它的诞生伴随而来,它采用了0.22微米制程打造,拥有四条渲染流水线,达到2300万个晶体管,分为SDRAM和DDR SDRAM两种版本,DDR带宽性能基本是SDRAM的两倍,在高分辨率中优势明显。
NVIDIA把Graphics Processing Unit的首字母「GPU」提炼出来,把GeForce 256冠以“世界上第一块GPU”称号,巧妙地定义了GPU这个新品类,并占据这个词的用户心智直到今天。

GPU为谁所生?图像。
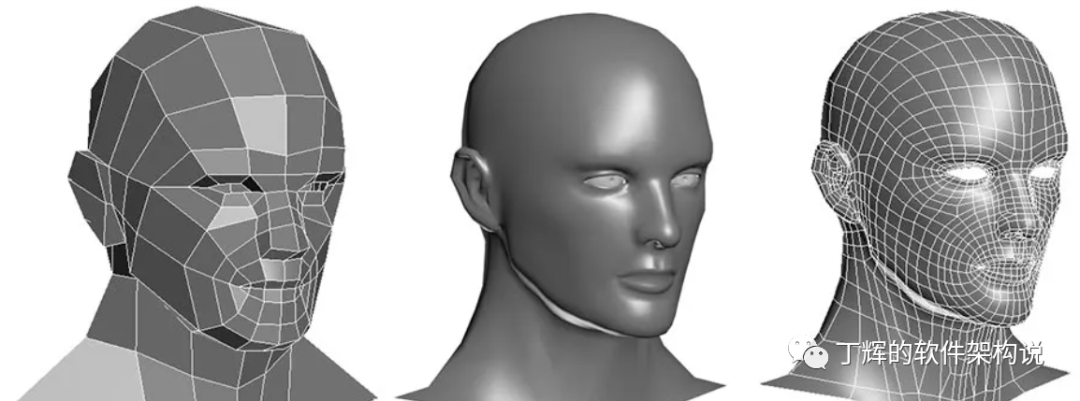
3D 游戏里的人脸,其实是用多边形建模创建出来的,而实际这些人物在画面里面的移动、动作,乃至根据光线发生的变化,都是通过计算机根据图形学的各种计算,实时渲染出来的。这个对于图像进行实时渲染的过程,每个像素或多边形顶点可以被分解成下面这样 5 个各自独立串行步骤:
顶点处理(Vertex Processing)
图元处理(Primitive Processing)
栅格化(Rasterization)
片段处理(Fragment Processing)
像素操作(Pixel Operations)
我们可以想一想,如果用 CPU 来进行这个渲染过程,需要花上多少资源呢?我们可以通过一些数据来做个粗略的估算。
在上世纪 90 年代的时候,屏幕的分辨率还没有现在那么高。一般的 CRT 显示器也就是 640×480 的分辨率。这意味着屏幕上有 30 万个像素需要渲染。为了让我们的眼睛看到画面不晕眩,我们希望画面能有 60 帧。于是,每秒我们就要重新渲染 60 次这个画面。也就是说,每秒我们需要完成 1800 万次单个像素的渲染。从栅格化开始,每个像素有 3 个流水线步骤,即使每次步骤只有 1 个指令,那我们也需要 5400 万条指令,也就是 54M 条指令。
90 年代的 CPU 的性能是多少呢?93 年出货的第一代 Pentium 处理器,主频是 60MHz,后续逐步推出了 66MHz、75MHz、100MHz 的处理器。以这个性能来看,用 CPU 来渲染 3D 图形,基本上就要把 CPU 的性能用完了。因为实际的每一个渲染步骤可能不止一个指令,我们的 CPU 可能根本就跑不动这样的三维图形渲染,必须使用GPU。
GPU为什善于并行计算呢?
这里解释下并行。
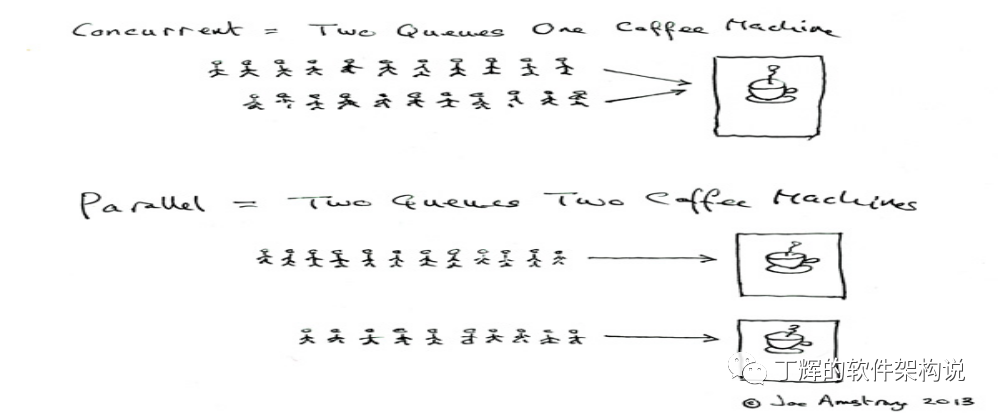
并行计算是指在同一时间内,在多个处理器或核心上同时执行多个计算任务。这种方式可以显著提高计算机的效率和性能,特别是对于大规模的数据处理和计算密集型应用来说。
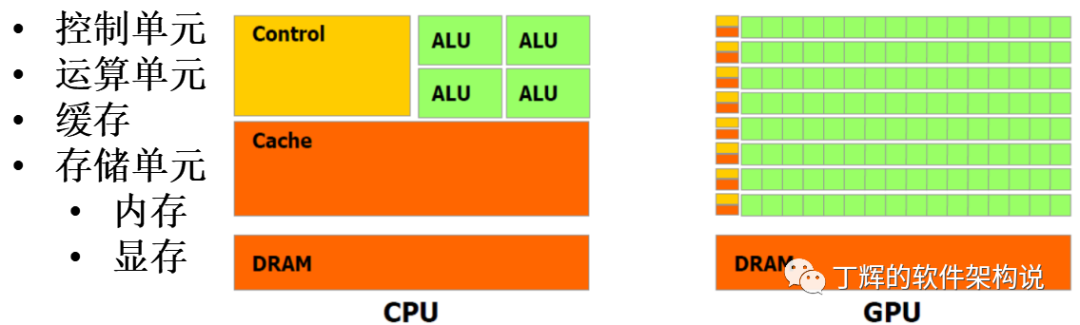
不怪CPU弱,而是其本就以线程调度见长,为此将更多的空间让渡给了控制单元和存储单元,用于计算的计算单元只占据20%的空间。简单说CPU就是一个老教授,积分微分无所不能,可以完成十分复杂的任务。衡量CPU的指标是这个老教授有多厉害。
GPU则相反,80%以上空间是计算单元,这就带来了超强并行计算能力,更适合图片显示这种步骤固定、重复枯燥而又可以并行处理的工作,像上述图片渲染的例子,图片不同像素之间是可以互相独立并行处理的。而GPU就像很多很多个小学生,每个小学生只会简单地加减乘除。衡量GPU的指标是一个班有多少个小学生。
从上面可以看出,什么类型的程序适合在GPU上运行?那就是可并行的计算密集型的程序。
GPU拥有成百上千个核,每一个核在同一时间最好能做同样的事情,这种结构带来了强大的并行计算能力,例如在进行图片渲染时,相当于每个小学并行相对独立同时算各自的题目,每道题相当于图形上一个点,这样把逐点串行计算变成了多点并行计算,极大缩短了处理时间。
其他还包括科学模拟、图像和视频处理、数据挖掘、金融分析、破解密码、挖矿等等高并行场景(尽管都知道矿机最废显卡)。。。
让人欢喜的是GPU成了深度学习的“炼丹炉”
深度学习的训练过程是对每个输入值根据神经网络每层的函数和参数进行分层运算,每层上每个节点相当于一个图形像素,最终得到一个输出值,跟图形渲染一样都需要大量的可并行浮点数矩阵运算——而这恰巧就是GPU最擅长的东西。
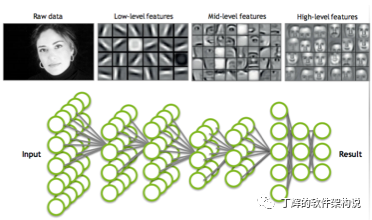
全连接神经网络
由于神经网路每层的计算和图像每帧的渲染技术方式和计算量何其相似,这不正好让GPU大显身手吗?很多经典的神经网络理论早被提了出来,但苦于算力不支持,一直没有突破,GPU的出现正好误打误撞的解决了大规模神经网络的算力问题。
接下来要做的就是把神经网络每层计算转化为图像渲染计算结构进行计算,结果再转成神经网络的值。
亚马逊的Kumar Chellapilla于2006年在GPU GeForce 7800上用矩阵浮点运算和图形渲染结构互转等乾坤大挪移式的复杂操作实现CNN(大名鼎鼎的卷积神经网络,它在图像识别中属于一哥)是已知的将GPU用于深度学习的最早尝试,据说比CPU快了4倍。

GeForce 7800
这个过程非常复杂,非一般小白能染指的。
直到2007年,NVIDIA推出了CUDA编程架构(C语言的小子集),同时可以支持图形处理和高性能计算。
由于其对并行计算高超的抽象和C语言语法糖衣带来的通用性和易用性,打败了Apple的OpenCL,成为GPU编程接口的实际标准。
时来天地同协力,有利于并行计算的算法又有了新突破。2009年6月,斯坦福大学的Rajat Raina和吴恩达合作发表文章,论文采用DBNs模型和稀疏编码,模型参数高达一亿,使用GPU运行速度训练模型,相比传统双核CPU最快时相差70倍,把本来需要几周训练的时间降到了一天,算力的进步再次加速了人工智能的快速发展。这时GPU也从游戏、视频、矿机玩家的顶配成为深度学习的利器。

吴恩达
虽然支撑深度学习的GPU的厂商也较多,比如Intel、AMD、谷歌(TPU)、国内的景嘉微、寒武纪等,但是性能最高、通用性最强、应用最广泛的还是NVIDIA的GPU,我们以它为例讲解。
GPU架构和并行计算原理
咱们看看GPU是怎么实现并行计算的(以CUDA架构为例)?
实体的能力,一定是由它的内部架构决定的,GPU架构分为物理架构和逻辑架构。
先看下GPU(以P100为例)的物理架构,下图中,GPU物理处理单元由SP、SM组成。


SP:最基本的处理单元,streaming processor,也称为CUDA Core。最后具体的指令和任务都是在SP上处理的。GPU进行并行计算,也就是很多个SP同时做处理。
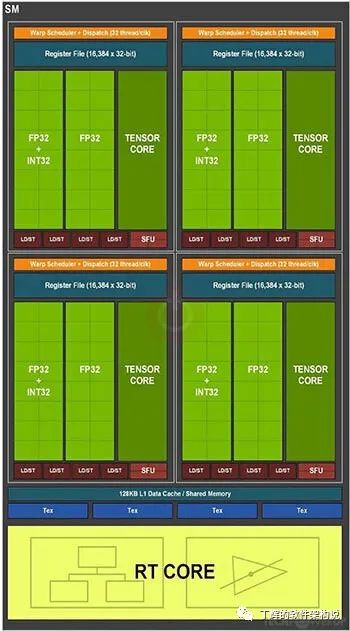
SM:多个SP加上其他的一些资源组成一个streaming multiprocessor。也叫GPU大核(对比CPU核心)。其他资源包括warp scheduler、register、shared memory等。
其中,P100芯片中包含60个SM,1个SM中包含64个SP。总的SP个数为60*64=3840。可用的SP个数为56*64=3584。
下面再看看逻辑架构:
 4
4
上图中,
thread:线程,独立并发体。
block:若干个threads会组成,同一个block中的threads可以通过共享内存进行通信。block大小可以为一维,二维或者三维。
grid:多个blocks则会再构成grid。grid大小可以是一维、二维。
warp:由grid组成。
这种结构,既可以非常容易的和图像的点线面体对应,也非常容易和一维,二维,三维,n维矩阵相对应,而且全部是并发体,天生就是为图形渲染和矩阵运算而生的。
软硬件架构映射关系:
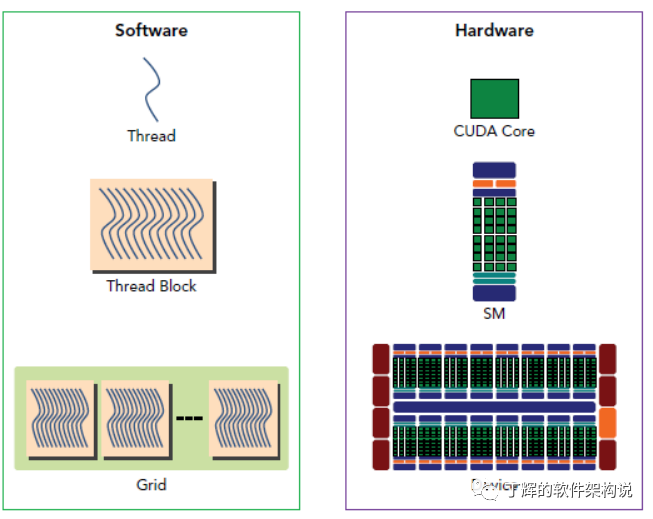
thread对应sp,block对应sm
虽然GPU逻辑上支持成千上万个线程同时并行计算。但是物理上实际运行的线程个数受限于SP个数。所以在CUDA编程中,GPU的线程个数不是越多越好。
CUDA不光可以用于大模型训练,还可以用于HPC(高性能计算),许多并行问题需要做CDG(计算依赖图),使用并行加速等,大家有兴趣,可以参加我的《CUDA并行计算战训营》,手把手带领大家掌握并行计算的精髓。不仅在深度学习(定制TensorFlow、pytorch、caffe等深度学习平台底层加速源码),而且可以在图形渲染、挖矿、数据统计(比如上亿级别数据的中位数计算等)等大显身手。
而且等你熟悉了并行计算的思想,你的眼中就是个并行的世界,比如,数组求和就不再是串行算法,而是妥妥的并行计算,类似情况很多很多。。。
NVIDIA GPU的发展
GPU厂商很多,但NVIDIA最有代表性和主流。其高性能计算GPU出了好几代,每一代都是以大科学家的名字命名。越往后显存越大,sp(CUDA核)越多,并行能力几何数量级增加。

了解了这么多,我们自己要使用GPU进行大模型预训练、精调等,该怎么选用GPU呢?别着急,GPU带来的可不都是惊喜,还有淡淡的忧伤。
那么GPU的忧来自哪呢?烧钱、烧大量的钱,落伍、快速的落伍。
对于深度学习GPU来说,有几个指标我们比较关注:
1、显存
深度学习特别是大模型兴起,模型参数的数量级急剧膨胀(大家熟知的ChatGPT3.5就有1750亿的参数),即使以目前优秀的几个小模型的推理和精调为例:
a、chat-glm fp32(单精度)加载就需要13g显存,至少需要一块p100,p100是16g显存。
b、vicuna-7b 使用Fine-tuning方式精调需要 4 x A100 (40GB).
2、单精度性能
每秒浮点运算次数,1 TFLOPS=每秒10的12次方次浮点运算。这个也和物理CUDA Core(上文中的SP)数量强相关。
3、单机多卡(多机多卡后面会谈)通讯方式
目前主流有两种:nvlink和pcie
其中nvlink是NVIDIA提出的多卡互联方式,卡间双向速度p100可以达到160GBps,一般可以达到pcie gen3的5倍。a100可达600GBps,h100可达900GBps,那比pcie快的可不是一点两点。
这个要根据GPU服务的主板是否支持nvlink来选择。
大规模训练中,无论采用数据并行,还是模型并行(每张GPU只负责大模型中1层或少数几层,通过GPU串联形成模型层间串联);无论是同步计算(并行时层间拉齐)还是异步计算,卡间数据传输都会成为最短的那块板(卡的性能提升被卡间数据传输性能下降抵消),谁不想全换成nvlink啊,这时就得全换成GPU专用服务器而不是利旧改造已有服务器,预算又超了。。。
4、阉割版
老美为了限制我们,把最新的H100和A100最牛b的双精浮点运算给砍了,另外nvlink带宽也限制到400GBps(A100能到600GBps,H100能到900GBps),价格更高,成了H800和A800,导致这两货一听名字搞得比100系列还牛b。
搞得咱们花大价钱还买不到尖货,找谁说理去。
5、可靠性
一般分为桌面型和服务型,服务型一般加上错误校验功能,另外散热会处理更好,高端GPU都是服务型。
笔者16年做深度学习训练时,买了很多Titan X,就属于桌面型,插到我们自研服务器上,密集计算时温度很容易超过90摄氏度,我们特意做了个监控温度agent,如果过热(超过104摄氏度)就把运算任务暂停一会,人工实现土法过热保护。
从使用角度看,GPU有哪些烧钱的方式呢?
业界公认,使用大模型目前基本有三种方式:
1、使用公网的ChatGPT3.5/4、Copilot等,虽然好用,但有以下问题:
a、私域知识缺失
大模型的基本能力来自于预训练,ChatGPT里没有私域知识进行过预训练,私域知识使用场景下ChatGPT能力大打折扣,这块我们实践中也表现明显。
b、安全性问题
这块很明显,上传需求、规划和代码有泄密风险。
另外提供私域数据委托openai预训练和精调,花费巨大,数据安全也要考虑。
2、开源模型二次精调
使用llama、alpaca、vicuna、chat-glm、moss、bloom等进行精调,但是我们实践发现,有两点结论:
a、精调很容易碰到对齐税(对齐税原理另开文章分享),即某一方面精度提升,大模型会忘记很多已有的知识,表现为精调数据量越大,其他方面性能越是急剧下降,这就造成以开源大模型为基础自研领域通用大模型较难,只能从领域偏科大模型入手。
b、对于领域偏科大模型,又分为两种情况:
i 单领域精调语料过多
ii主副领域叠加(llama精调成中文后,再使用领域代码语料精调)
上述情况语料也很容易达到上限;特别是第二种情况更是很容易导致模型性能急剧下降的。比如汉化并附加领域代码生成的场景非常常见,如何在精调中处理语料的上限就需要额外特殊技能(我们正在测试中,相关成果有机会跟大家分享)。
3、预训练大模型
根据我们的经验数据,以30天A800/80G/nvlink完成预训练计算:
LLaMA-7B~192卡
LLaMA-13B~384卡
LLaMA-30B~1024卡
LLaMA-65B~2048卡
综上,如果要达到开悟(至少750亿以上参数)或涌现级别的领域大模型,必须从预训练开始。
如果效果较好的话,至少需要192卡开始,目前主流A800(A100的阉割版),预计都超过¥10w/张(H100已经涨到4万美金/张),光卡就¥2000w,换上最新的H100/H800估计还要翻翻;
加上配套的8卡nvlink服务器(pcie的便宜点),每台也得20-30w,预计¥500w左右;
GPU服务器之间组建算力网络,进行多机多卡组网形成HPC集群,需要rdma网卡和IB交换机,也挺贵,甚至ib网线也超贵。
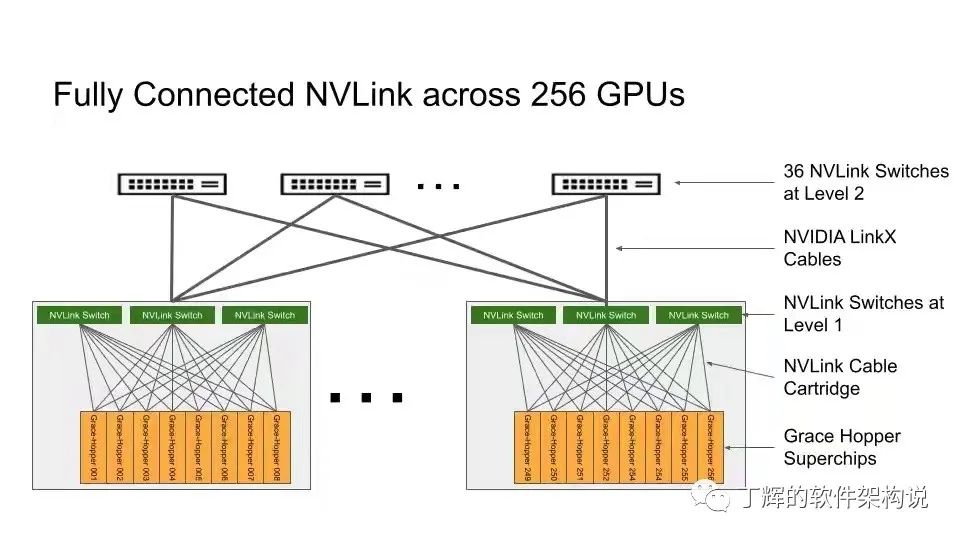
NVIDIA最新的组网方式可以通过nvlink switch把256张GPU连接起来,相当于一个大256的GPU。
原来nvlink只能用于单机卡间通讯,现在可以实现主机间nvlink通讯了,900GB,一般网速400Gb就很厉害了,大B和小b的区别,很酷很牛,不过钱可能像流水一样哗哗哗。。。
简单说,如果进行预训练,最小也要投资¥2000w往上;如果上千块卡,肯定要过亿了。
至于GPU功耗高耗电(P100单卡300W),再加上服务器耗电,电费占比还不算大,更大的还有机房建设(多路供电,UPS,高性能空调,消防设施,甚至液冷),也是花钱无算。。。
以上种种坑,笔者都一一踩过。。。
这还不算,目前主流GPU卡普遍缺货,有钱也不能短期内买到,等你能买到,已经落伍一大截了。等你全刚刚部署完,主流大模型和GPU又升级换代了,属于费尽千辛万苦,花钱如流水之后,一抬头,又落伍了那种。
刚刚建完A800的集群,还没来得及升级到H100,最新的H200已经要发售了。
所以,GPU是大模型的炼丹炉,可喜的是极大促进了AI的大发展。对AI玩家,特别是中小型玩家来说,让人忧的是太烧钱太容易落伍。。。

参考:
The Art of Multiprocessor Programming
Structured parallel programming
基于CUDA的GPU并行程序开发指南
英伟达帝国的一丢丢丢裂缝
声明:文中观点不代表本站立场。本文传送门:https://eyangzhen.com/213228.html
