
很久没有更新了,因为最近一段时间有点小忙,最近也是有同学问我说自己在idea里面写spark程序测试,每次都要打包然后上传到集群,然后spark-submit提交很麻烦,可不可以在idea里面直接远程提交到yarn集群呢? 当然是可以的,今天就给大家分享一下具体的操作过程.
那先来说一下spark任务运行的几种模式:
1,本地模式,在idea里面写完代码直接运行.
2,standalone模式,需要把程序打jar包,上传到集群,spark-submit提交到集群运行
3,yarn模式(local,client,cluster)跟上面的一样,也需要打jar包,提交到集群运行
如果是自己测试的话,用上面几种方法都比较麻烦,每次改完代码都需要打包上传到集群,然后spark-submit提交到集群运行,也非常浪费时间,下面就介绍怎么在本地idea远程提交到yarn集群
直接看下面的demo(代码写的比较简单)package spark
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf}
import spark.wordcount.kafkaStreams
object RemoteSubmitApp {
def main(args: Array[String]) {
// 设置提交任务的用户
System.setProperty(“HADOOP_USER_NAME”, “root”)
val conf = new SparkConf()
.setAppName(“WordCount”)
// 设置yarn-client模式提交
.setMaster(“yarn”)
// 设置resourcemanager的ip
.set(“yarn.resourcemanager.hostname”,”master”)
// 设置executor的个数
.set(“spark.executor.instance”,”2″)
// 设置executor的内存大小
.set(“spark.executor.memory”, “1024M”)
// 设置提交任务的yarn队列
.set(“spark.yarn.queue”,”spark”)
// 设置driver的ip地址
.set(“spark.driver.host”,”192.168.17.1″)
// 设置jar包的路径,如果有其他的依赖包,可以在这里添加,逗号隔开
.setJars(List(“D:\develop_soft\idea_workspace_2018\sparkdemo\target\sparkdemo-1.0-SNAPSHOT.jar”
))
conf.set(“spark.serializer”, “org.apache.spark.serializer.KryoSerializer”)
val scc = new StreamingContext(conf, Seconds(1))
scc.sparkContext.setLogLevel(“WARN”)
//scc.checkpoint(“/spark/checkpoint”)
val topic = “jason_flink”
val topicSet = Set(topic)
val kafkaParams = Map[String, Object](
“auto.offset.reset” -> “latest”,
“value.deserializer” -> classOf[StringDeserializer]
, “key.deserializer” -> classOf[StringDeserializer]
, “bootstrap.servers” -> “master:9092,storm1:9092,storm2:9092”
, “group.id” -> “jason_”
, “enable.auto.commit” -> (true: java.lang.Boolean)
)
kafkaStreams = KafkaUtils.createDirectStream[String, String](
scc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](topicSet, kafkaParams))
kafkaStreams.foreachRDD(rdd=> {
if (!rdd.isEmpty()) {
rdd.foreachPartition(fp=> {
fp.foreach(f=> {
println(f.value().toString)
})
})
}
})
scc.start()
scc.awaitTermination()
}
}
然后我们直接右键运行,看下打印的日志
19/08/16 23:17:24 INFO SparkContext: Running Spark version 2.2.019/08/16 23:17:25 INFO SparkContext: Submitted application: WordCount19/08/16 23:17:25 INFO SecurityManager: Changing view acls to: JasonLee,root19/08/16 23:17:25 INFO SecurityManager: Changing modify acls to: JasonLee,root19/08/16 23:17:25 INFO SecurityManager: Changing view acls groups to: 19/08/16 23:17:25 INFO SecurityManager: Changing modify acls groups to: 19/08/16 23:17:25 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(JasonLee, root); groups with view permissions: Set(); users with modify permissions: Set(JasonLee, root); groups with modify permissions: Set()19/08/16 23:17:26 INFO Utils: Successfully started service 'sparkDriver' on port 62534.19/08/16 23:17:26 INFO SparkEnv: Registering MapOutputTracker19/08/16 23:17:26 INFO SparkEnv: Registering BlockManagerMaster19/08/16 23:17:26 INFO BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information19/08/16 23:17:26 INFO BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up19/08/16 23:17:26 INFO DiskBlockManager: Created local directory at C:UsersjasonAppDataLocalTempblockmgr-6ec3ae57-661d-4974-8bc9-7357ab4a0c0619/08/16 23:17:26 INFO MemoryStore: MemoryStore started with capacity 4.1 GB19/08/16 23:17:26 INFO SparkEnv: Registering OutputCommitCoordinator19/08/16 23:17:26 INFO log: Logging initialized @2170ms19/08/16 23:17:26 INFO Server: jetty-9.3.z-SNAPSHOT19/08/16 23:17:26 INFO Server: Started @2236ms19/08/16 23:17:26 INFO AbstractConnector: Started ServerConnector@4a534663{HTTP/1.1,[http/1.1]}{0.0.0.0:4040}19/08/16 23:17:26 INFO Utils: Successfully started service 'SparkUI' on port 4040.19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.ServletContextHandler@427b5f92{/jobs,null,AVAILABLE,@Spark}19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.ServletContextHandler@1991f767{/jobs/json,null,AVAILABLE,@Spark}19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.ServletContextHandler@4c6daf0{/jobs/job,null,AVAILABLE,@Spark}19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.ServletContextHandler@2488b073{/jobs/job/json,null,AVAILABLE,@Spark}19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.ServletContextHandler@55787112{/stages,null,AVAILABLE,@Spark}19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.ServletContextHandler@7db82169{/stages/json,null,AVAILABLE,@Spark}19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.ServletContextHandler@f74e835{/stages/stage,null,AVAILABLE,@Spark}19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.ServletContextHandler@19fe4644{/stages/stage/json,null,AVAILABLE,@Spark}19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.ServletContextHandler@5be067de{/stages/pool,null,AVAILABLE,@Spark}19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.ServletContextHandler@18245eb0{/stages/pool/json,null,AVAILABLE,@Spark}19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.ServletContextHandler@24fb6a80{/storage,null,AVAILABLE,@Spark}19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.ServletContextHandler@72a85671{/storage/json,null,AVAILABLE,@Spark}19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.ServletContextHandler@18f20260{/storage/rdd,null,AVAILABLE,@Spark}19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.ServletContextHandler@7a48e6e2{/storage/rdd/json,null,AVAILABLE,@Spark}19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.ServletContextHandler@3a94964{/environment,null,AVAILABLE,@Spark}19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.ServletContextHandler@6d0b5baf{/environment/json,null,AVAILABLE,@Spark}19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.ServletContextHandler@2a3591c5{/executors,null,AVAILABLE,@Spark}19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.ServletContextHandler@346a361{/executors/json,null,AVAILABLE,@Spark}19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.ServletContextHandler@1643d68f{/executors/threadDump,null,AVAILABLE,@Spark}19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.ServletContextHandler@2e029d61{/executors/threadDump/json,null,AVAILABLE,@Spark}19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.ServletContextHandler@4052274f{/static,null,AVAILABLE,@Spark}19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.ServletContextHandler@24faea88{/,null,AVAILABLE,@Spark}19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.ServletContextHandler@64beebb7{/api,null,AVAILABLE,@Spark}19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.ServletContextHandler@29ef6856{/jobs/job/kill,null,AVAILABLE,@Spark}19/08/16 23:17:26 INFO ContextHandler: Started o.s.j.s.ServletContextHandler@3faf2e7d{/stages/stage/kill,null,AVAILABLE,@Spark}19/08/16 23:17:26 INFO SparkUI: Bound SparkUI to 0.0.0.0, and started at http://192.168.17.1:404019/08/16 23:17:26 INFO SparkContext: Added JAR D:develop_softidea_workspace_2018sparkdemotargetsparkdemo-1.0-SNAPSHOT.jar at spark://192.168.17.1:62534/jars/sparkdemo-1.0-SNAPSHOT.jar with timestamp 156596864636919/08/16 23:17:27 INFO RMProxy: Connecting to ResourceManager at master/192.168.17.142:803219/08/16 23:17:27 INFO Client: Requesting a new application from cluster with 2 NodeManagers19/08/16 23:17:27 INFO Client: Verifying our application has not requested more than the maximum memory capability of the cluster (8192 MB per container)19/08/16 23:17:27 INFO Client: Will allocate AM container, with 896 MB memory including 384 MB overhead19/08/16 23:17:27 INFO Client: Setting up container launch context for our AM19/08/16 23:17:27 INFO Client: Setting up the launch environment for our AM container19/08/16 23:17:27 INFO Client: Preparing resources for our AM container19/08/16 23:17:28 WARN Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.19/08/16 23:17:31 INFO Client: Uploading resource file:/C:/Users/jason/AppData/Local/Temp/spark-7ed16f4e-0f99-44cf-8553-b4541337d0f0/__spark_libs__5037580728569655338.zip -> hdfs://master:9000/user/root/.sparkStaging/application_1565990507758_0020/__spark_libs__5037580728569655338.zip19/08/16 23:17:34 INFO Client: Uploading resource file:/C:/Users/jason/AppData/Local/Temp/spark-7ed16f4e-0f99-44cf-8553-b4541337d0f0/__spark_conf__5359714098313821798.zip -> hdfs://master:9000/user/root/.sparkStaging/application_1565990507758_0020/__spark_conf__.zip19/08/16 23:17:34 INFO SecurityManager: Changing view acls to: JasonLee,root19/08/16 23:17:34 INFO SecurityManager: Changing modify acls to: JasonLee,root19/08/16 23:17:34 INFO SecurityManager: Changing view acls groups to: 19/08/16 23:17:34 INFO SecurityManager: Changing modify acls groups to: 19/08/16 23:17:34 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(JasonLee, root); groups with view permissions: Set(); users with modify permissions: Set(JasonLee, root); groups with modify permissions: Set()19/08/16 23:17:34 INFO Client: Submitting application application_1565990507758_0020 to ResourceManager19/08/16 23:17:34 INFO YarnClientImpl: Submitted application application_1565990507758_002019/08/16 23:17:34 INFO SchedulerExtensionServices: Starting Yarn extension services with app application_1565990507758_0020 and attemptId None19/08/16 23:17:35 INFO Client: Application report for application_1565990507758_0020 (state: ACCEPTED)19/08/16 23:17:35 INFO Client: client token: N/A diagnostics: AM container is launched, waiting for AM container to Register with RM ApplicationMaster host: N/A ApplicationMaster RPC port: -1 queue: spark start time: 1565997454105 final status: UNDEFINED tracking URL: http://master:8088/proxy/application_1565990507758_0020/ user: root19/08/16 23:17:36 INFO Client: Application report for application_1565990507758_0020 (state: ACCEPTED)19/08/16 23:17:37 INFO Client: Application report for application_1565990507758_0020 (state: ACCEPTED)19/08/16 23:17:38 INFO Client: Application report for application_1565990507758_0020 (state: ACCEPTED)19/08/16 23:17:39 INFO Client: Application report for application_1565990507758_0020 (state: ACCEPTED)19/08/16 23:17:40 INFO YarnSchedulerBackend$YarnSchedulerEndpoint: ApplicationMaster registered as NettyRpcEndpointRef(spark-client://YarnAM)19/08/16 23:17:40 INFO YarnClientSchedulerBackend: Add WebUI Filter. org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter, Map(PROXY_HOSTS -> master, PROXY_URI_BASES -> http://master:8088/proxy/application_1565990507758_0020), /proxy/application_1565990507758_002019/08/16 23:17:40 INFO JettyUtils: Adding filter: org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter19/08/16 23:17:40 INFO Client: Application report for application_1565990507758_0020 (state: ACCEPTED)19/08/16 23:17:41 INFO Client: Application report for application_1565990507758_0020 (state: RUNNING)19/08/16 23:17:41 INFO Client: client token: N/A diagnostics: N/A ApplicationMaster host: 192.168.17.145 ApplicationMaster RPC port: 0 queue: spark start time: 1565997454105 final status: UNDEFINED tracking URL: http://master:8088/proxy/application_1565990507758_0020/ user: root19/08/16 23:17:41 INFO YarnClientSchedulerBackend: Application application_1565990507758_0020 has started running.19/08/16 23:17:41 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 62586.19/08/16 23:17:41 INFO NettyBlockTransferService: Server created on 192.168.17.1:6258619/08/16 23:17:41 INFO BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy19/08/16 23:17:41 INFO BlockManagerMaster: Registering BlockManager BlockManagerId(driver, 192.168.17.1, 62586, None)19/08/16 23:17:41 INFO BlockManagerMasterEndpoint: Registering block manager 192.168.17.1:62586 with 4.1 GB RAM, BlockManagerId(driver, 192.168.17.1, 62586, None)19/08/16 23:17:41 INFO BlockManagerMaster: Registered BlockManager BlockManagerId(driver, 192.168.17.1, 62586, None)19/08/16 23:17:41 INFO BlockManager: Initialized BlockManager: BlockManagerId(driver, 192.168.17.1, 62586, None)19/08/16 23:17:41 INFO ContextHandler: Started o.s.j.s.ServletContextHandler@3bb9ca38{/metrics/json,null,AVAILABLE,@Spark}19/08/16 23:17:44 INFO YarnSchedulerBackend$YarnDriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) (192.168.17.145:40622) with ID 119/08/16 23:17:44 INFO BlockManagerMasterEndpoint: Registering block manager storm1:44607 with 366.3 MB RAM, BlockManagerId(1, storm1, 44607, None)19/08/16 23:17:48 INFO YarnSchedulerBackend$YarnDriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) (192.168.17.147:58232) with ID 219/08/16 23:17:48 INFO YarnClientSchedulerBackend: SchedulerBackend is ready for scheduling beginning after reached minRegisteredResourcesRatio: 0.819/08/16 23:17:48 INFO BlockManagerMasterEndpoint: Registering block manager storm2:34000 with 366.3 MB RAM, BlockManagerId(2, storm2, 34000, None)19/08/16 23:17:49 WARN KafkaUtils: overriding enable.auto.commit to false for executor19/08/16 23:17:49 WARN KafkaUtils: overriding auto.offset.reset to none for executor19/08/16 23:17:49 WARN KafkaUtils: overriding executor group.id to spark-executor-jason_19/08/16 23:17:49 WARN KafkaUtils: overriding receive.buffer.bytes to 65536 see KAFKA-3135可以看到提交成功了,然后我们打开yarn的监控页面看下有没有job
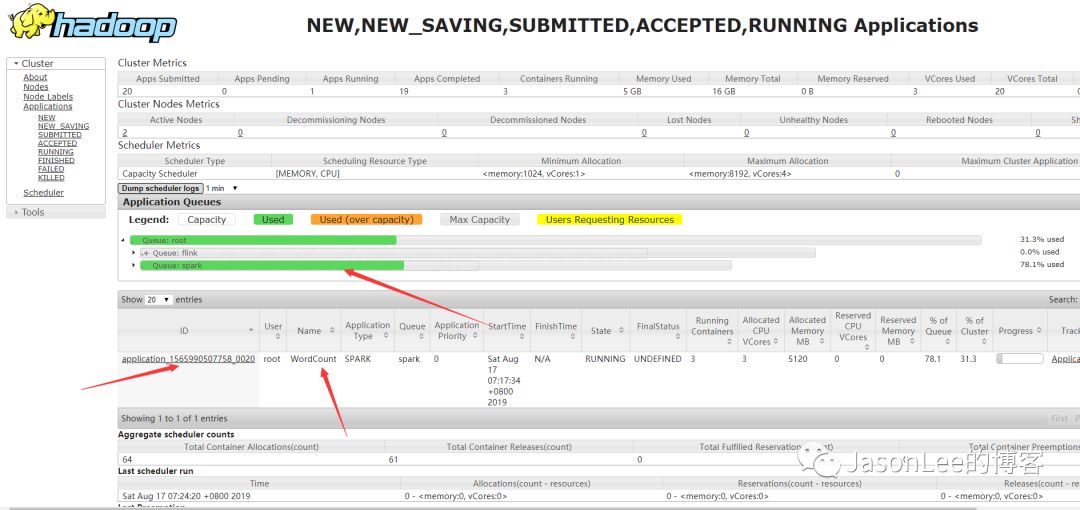

可以看到有一个spark程序在运行,然后我们点进去,看下具体的运行情况
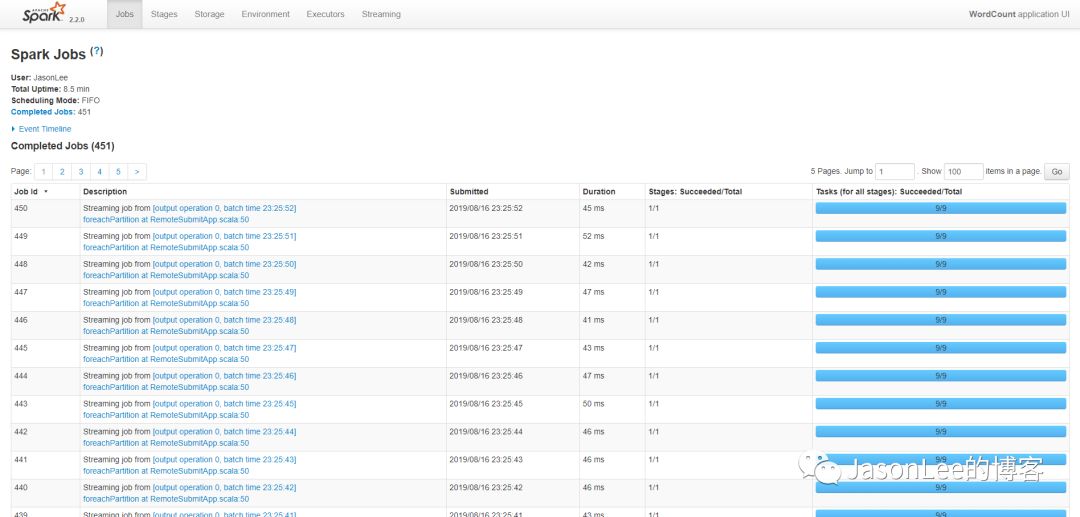
可以看到运行的正常,选择一下job,看下executor打印的日志
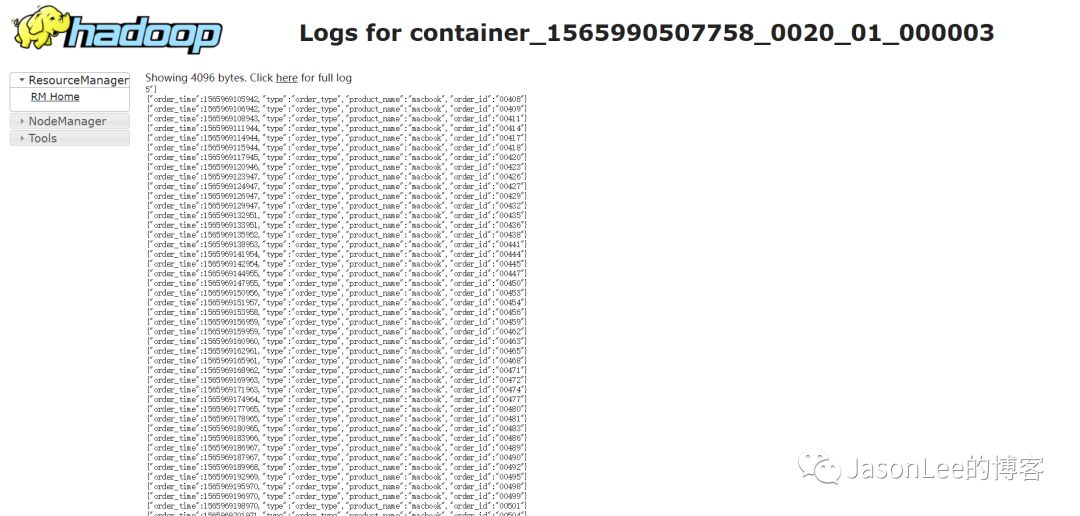
这个就是我们写到kafka的数据,没什么问题,停止的时候,只需要在idea里面点击停止程序就可以了,这样测试起来就会方便很多.
运行过程中可能会遇到的问题:
1,首先需要把yarn-site.xml,core-site.xml,hdfs-site.xml放到resource下面,因为程序运行的时候需要这些环境.
2,权限问题
Caused by: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.AccessControlException): Permission denied: user=JasonLee, access=WRITE, inode="/user":root:supergroup:drwxr-xr-x at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.check(FSPermissionChecker.java:342) at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:251) at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:189) at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1744) at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1728) at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkAncestorAccess(FSDirectory.java:1687) at org.apache.hadoop.hdfs.server.namenode.FSDirMkdirOp.mkdirs(FSDirMkdirOp.java:60) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.mkdirs(FSNamesystem.java:2980) at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.mkdirs(NameNodeRpcServer.java:1096) at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.mkdirs(ClientNamenodeProtocolServerSideTranslatorPB.java:652) at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java) at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:503) at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:989) at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:868) at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:814) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1886) at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2603)这个是因为在本地提交的所以用户名是JasonLee,它没有访问hdfs的权限,最简单的解决方法就是在代码里面设置用户是rootSystem.setProperty(“HADOOP_USER_NAME”, “root”)
3,缺失环境变量
Exception in thread "main" java.lang.IllegalStateException: Library directory 'D:develop_softidea_workspace_2018sparkdemoassemblytargetscala-2.11jars' does not exist; make sure Spark is built. at org.apache.spark.launcher.CommandBuilderUtils.checkState(CommandBuilderUtils.java:248) at org.apache.spark.launcher.CommandBuilderUtils.findJarsDir(CommandBuilderUtils.java:347) at org.apache.spark.launcher.YarnCommandBuilderUtils$.findJarsDir(YarnCommandBuilderUtils.scala:38) at org.apache.spark.deploy.yarn.Client.prepareLocalResources(Client.scala:526) at org.apache.spark.deploy.yarn.Client.createContainerLaunchContext(Client.scala:814) at org.apache.spark.deploy.yarn.Client.submitApplication(Client.scala:169) at org.apache.spark.scheduler.cluster.YarnClientSchedulerBackend.start(YarnClientSchedulerBackend.scala:56) at org.apache.spark.scheduler.TaskSchedulerImpl.start(TaskSchedulerImpl.scala:173) at org.apache.spark.SparkContext.<init>(SparkContext.scala:509) at org.apache.spark.streaming.StreamingContext$.createNewSparkContext(StreamingContext.scala:839) at org.apache.spark.streaming.StreamingContext.<init>(StreamingContext.scala:85) at spark.RemoteSubmitApp$.main(RemoteSubmitApp.scala:31) at spark.RemoteSubmitApp.main(RemoteSubmitApp.scala)这个报错是因为我们没有配置SPARK_HOME的环境变量,直接在idea里面的configurations里面的environment variables里面设置SPARK_HOME就可以了,如下图所示:
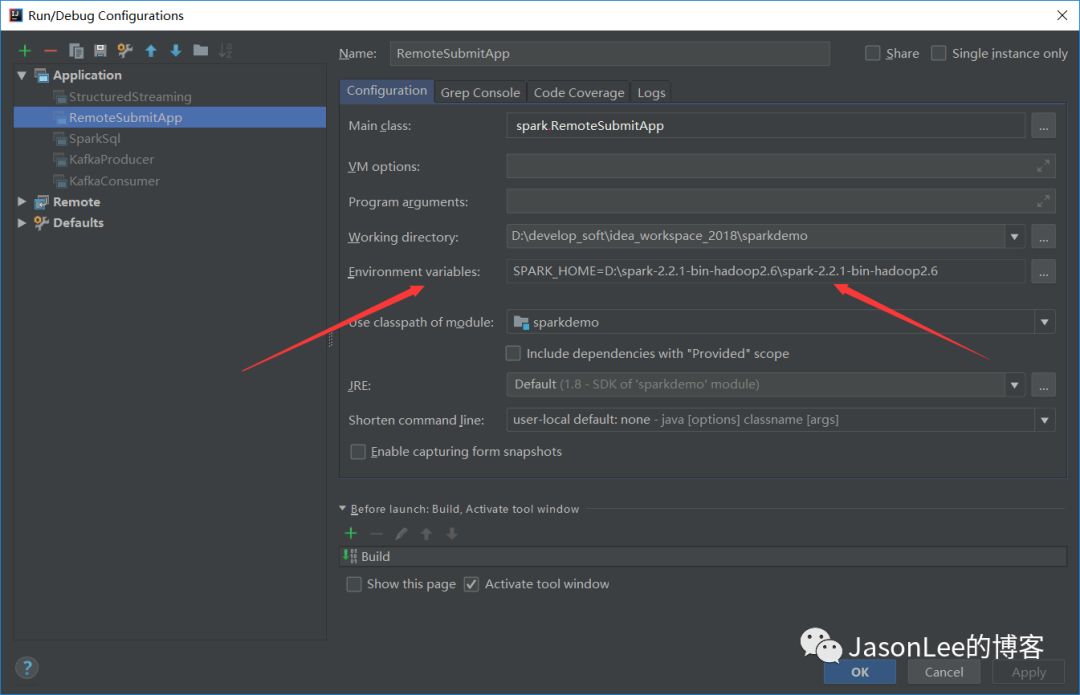
4,没有设置driver的ip
19/08/17 07:52:45 ERROR ApplicationMaster: Failed to connect to driver at 169.254.42.204:64010, retrying ...19/08/17 07:52:48 ERROR ApplicationMaster: Failed to connect to driver at 169.254.42.204:64010, retrying ...19/08/17 07:52:48 ERROR ApplicationMaster: Uncaught exception: org.apache.spark.SparkException: Failed to connect to driver! at org.apache.spark.deploy.yarn.ApplicationMaster.waitForSparkDriver(ApplicationMaster.scala:577) at org.apache.spark.deploy.yarn.ApplicationMaster.runExecutorLauncher(ApplicationMaster.scala:433) at org.apache.spark.deploy.yarn.ApplicationMaster.run(ApplicationMaster.scala:256) at org.apache.spark.deploy.yarn.ApplicationMaster$$anonfun$main$1.apply$mcV$sp(ApplicationMaster.scala:764) at org.apache.spark.deploy.SparkHadoopUtil$$anon$2.run(SparkHadoopUtil.scala:67) at org.apache.spark.deploy.SparkHadoopUtil$$anon$2.run(SparkHadoopUtil.scala:66) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1692) at org.apache.spark.deploy.SparkHadoopUtil.runAsSparkUser(SparkHadoopUtil.scala:66) at org.apache.spark.deploy.yarn.ApplicationMaster$.main(ApplicationMaster.scala:762) at org.apache.spark.deploy.yarn.ExecutorLauncher$.main(ApplicationMaster.scala:785) at org.apache.spark.deploy.yarn.ExecutorLauncher.main(ApplicationMaster.scala)这个报错是因为没有设置driver host,因为我们运行的是yarn-client模式,driver就是我们的本机,所以要设置本地的ip,不然找不到driver.
.set(“spark.driver.host”,”192.168.17.1″)
5,还有一个就是需要保证自己的电脑和虚拟机在同一个网段内,而且要关闭自己电脑的防火墙,不然可能会出现连接不上的情况.
我是以yarn-client模式提交的,yarn分了两个队列,提交的时候需要设置下队列的名称,还有很多参数都可以在代码里面设置,比如executor的内存,个数,driver的内存等,大家可以根据自己的情况去设置,当然了这个也可以提交到standalone集群.
声明:文中观点不代表本站立场。本文传送门:https://eyangzhen.com/247108.html


