

谈到链表之前,先说一下线性表。线性表是最基本、最简单、也是最常用的一种数据结构。线性表中数据元素之间的关系是一对一的关系,即除了第一个和最后一个数据元素之外,其它数据元素都是首尾相接的。线性表有两种存储方式,一种是顺序存储结构,另一种是链式存储结构。
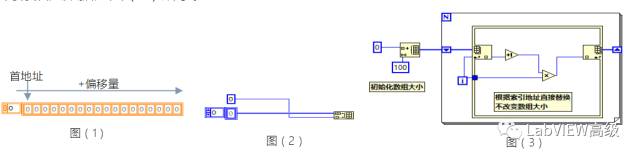
顺序存储结构就是两个相邻的元素在内存中也是相邻的。这种存储方式的优点是查询的时间复杂度为O(1),通过首地址和偏移量就可以直接访问到某元素,关于查找的适配算法很多,最快可以达到O(logn)。缺点是插入和删除的时间复杂度最坏能达到O(n),如果你在第一个位置插入一个元素,你需要把数组的每一个元素向后移动一位,如果你在第一个位置删除一个元素,你需要把数组的每一个元素向前移动一位。还有一个缺点,就是当你不确定元素的数量时,你开的数组必须保证能够放下元素最大数量,遗憾的是如果实际数量比最大数量少很多时,你开的数组没有用到的内存就只能浪费掉了。
对于LabVIEW语言本身自带了顺序存储结构_数组,如图(1)所示。在数组插入时,要动态开辟内存空间,非常耗资源,严重影响软件效率,如2图所示。优化方向只能在动态内存修改为固定内存,有些不知道要预设多少,只能开辟足够大,保证放下元素的足够数量,有部分内存是要浪费的,固定内存插入数据如图(3)所示。
双向链表
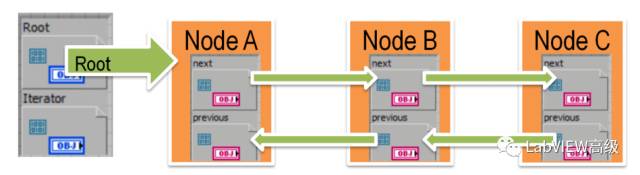
双向链表的指针域有两个指针,每个数据结点分别指向直接后继和直接前驱。双向链表不但可以从前向后遍历,也可以从后向前遍历。除了双向遍历的优点,双向链表的删除的时间复杂度会降为O(1),因为直接通过目的指针就可以找到前驱节点。遗憾的是LabVIEW没有提供数据链表数据容器,如何构建LabVIEW语言的双向链表?
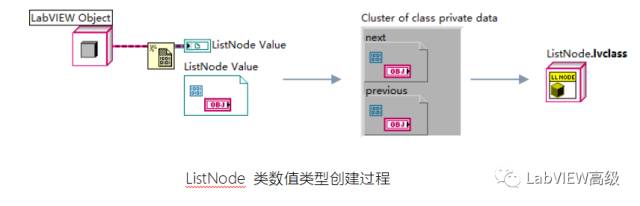
文本编程语言中的链表数据结构离不开引用(或指针),节点之间是通过 引用来相互关联的。LabVIEW可以为数据创建引用,因此也可以方便的实现与文本语言中功能相同的数据结构。双向链表中每个节点都会记录上一个节点和下一个节点的位置。因此,在双向链表中,可以从一个节点直接跳转到它的上一个或下一个节点上去,也就是正向 或反向遍历整个链表。可以直观的想到,使用LvClass实现这样的节点,只要为这个节点创建一个类ListNode,并且这个类有两个成员变量,它们的 类型都是ListNode的引用,分别用于指向前一个和后一个节点就可以了(数值类型采用LabVIEW语言最高的父类LabVIEW Object,所有的自定义数据类型都是其子类):
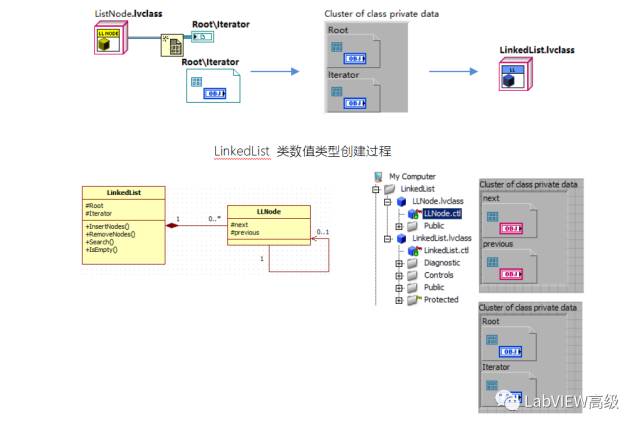
ListNode类是针对链表节点的,双向链表本身也需要做成一个类:LinkedList类,这个类中封装有链表的属性和方法。比如它需要一个指向链表表头的引用,需要有为链表添加删除数据的方法,为遍历链表中的数据,还需要有一个迭代器,表头和迭代器数据类型都是ListNode类的数值引用。
插入链表
插在最前面
首先读出首节点,判断是否有效,无效说明插入的节点是首节点,更新链表类的首节点值。
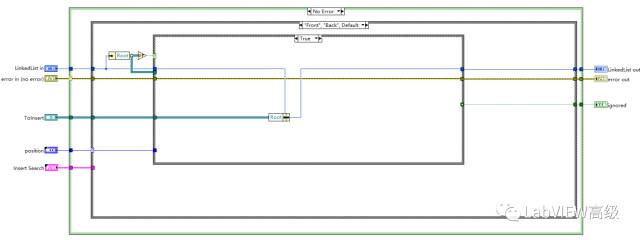
若有效,说明存在首节点,则根据插入的方向来增加新节点,在前面插入新节点,需要更新链表结构的首节点。在后面插入,首节点保持不变。
在后面插入新节点方法
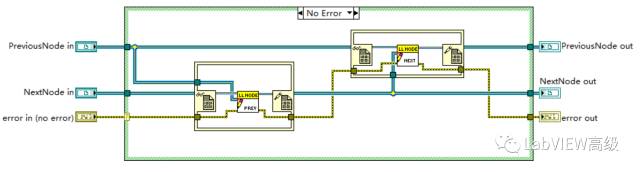
首先找到最后一节点引用,更新节点数值

更新节点方法
将PreviousNode在NextNode中设置为PreviousNode;NextNode在PreviousNode中设置为NextNode。
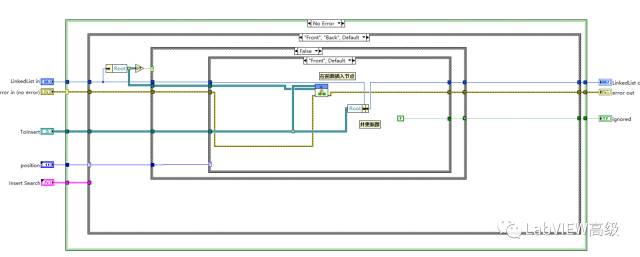
在前面插入新节点方法
原来的跟节点变为NextNode节点更新,链表首节点更新为插入的节点。
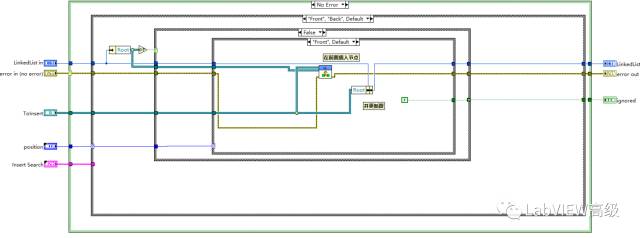
删除首节点
删除首节点,读出出首节点的Next,(清空首节点的Next节点,没有previousNode)定位到A节点,将A节点的PreviousNode设为空,完成首节点删除。
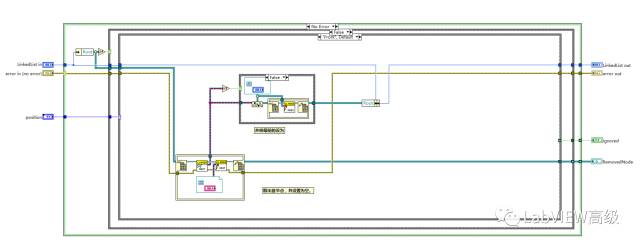
删除最后节点
删除C节点,读出Previous,也就是定位到B节点,(并清空),有因为Next本身就为空,在B节点中清空Next节点。
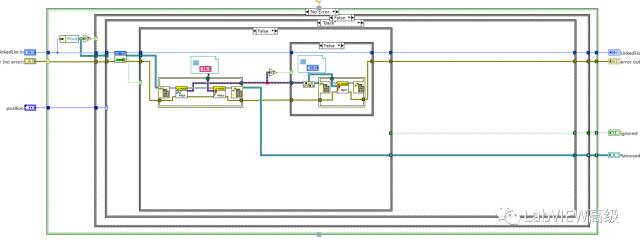
在任意位置插入数据
我们给ListNode创建子类SortedNode,带有位置信息。根据要插入的位置,遍历链表根据每个节点的位置信息,定位到节点。然后在来前插或者后插操作。
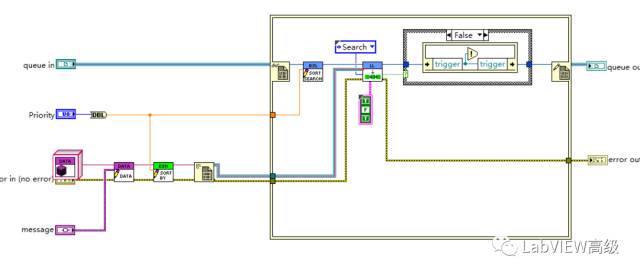
删除任意位置数据
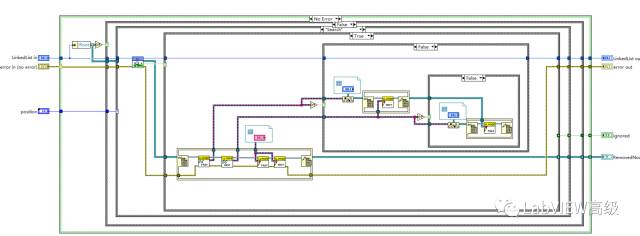
要删除B节点,定位B节点位置,删除B节点Pre和Next节点,并连接A与C。
声明:文中观点不代表本站立场。本文传送门:https://eyangzhen.com/314125.html
