
这几天好几位同学私信咨询了我很多关于性能测试的问题,特别是性能指标的理解,比如:“QPS和TPS有什么区别,该如何在实际工作中理解这些指标的含义”?
通过日常观察和交流,我发现部分测试同学对于技术指标的理解还是有些差异,归根结底的原因是知识面的广度较为缺乏,或者说对运维监控相关的知识了解不足。
这篇文章,从性能测试的角度出发,聊聊常见的一些监控技术指标以及相关的工具和作用。
不同视角性能
说起性能测试关注的指标,可能很多同学会说tps、rt、99rt、cpu/memery使用率等等。当然这些指标是我们日常工作中经常遇到和会关注的,但实际上在性能测试过程中,要根据不同的业务场景、技术架构以及问题表现来关注分析不同的指标。而不是只关注自己看到的指标,填充到表格里提交一份所谓的压测报告就完事的。
下面的表格,我列举了在考虑系统性能时,不同角色关注的一些常见的监控指标,仅供参考。
| 不同视角 | 关注指标 |
| 性能测试同学 | TPS/ART/99RT/Error% |
| 研发工程师 | QPS/99RT/YGC/FGC/OOM |
| 运维工程师 | CPU%/Memory%/Net Work/Disk IO |
| 数据库工程师 | 锁/索引/慢SQL/命中率 |
上表中所列出的指标,仅代表日常工作和压测时比较关注的通用指标,但在实际的项目和场景中,需要根据具体情况去监控分析更多的指标,切记不要生搬硬套。
看完下面的监控分层和指标含义,大家应该就可以理解我上面这句话了。
理解监控分层
下面是一个常见的微服务架构的简易模型:
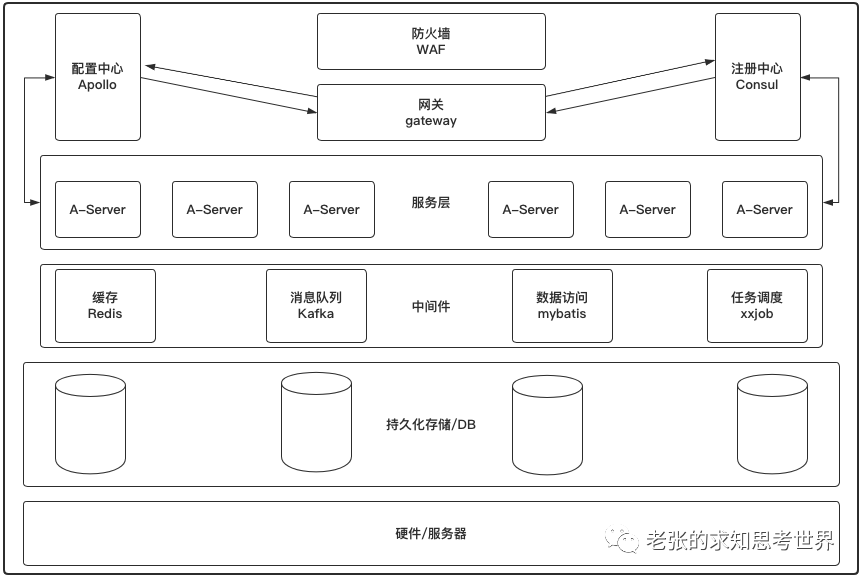

软件系统为用户提供服务,其背后是由多个软硬件组合支撑的,缺一不可。
如上图所示,软件系统的复杂性导致了当它出现性能问题时,影响性能的因素可能是其中任意一个组件。因此在性能测试中,要关注不同层级的指标。下表是不同层级我们需要关注的一些监控指标:
| 监控分层 | 常见关注指标 |
| 网络 | 带宽是否足够、是否有丢包延迟 |
| 网关 | 负载均衡 |
| 服务层 | TPS/ART/99RT/Error%/Load/异常/垃圾回收/通信协议 |
| 中间件 | 超时/线程池/缓存命中/消费速率&消息积压/批处理 |
| 持久化存储 | 锁/索引/慢SQL/命中率 |
| 硬件服务器 | CPU%/Memory%/Net Work/Disk IO |
| 操作系统 | Swap/内核参数/文件句柄/IO调度 |
你看,其实影响性能的因素很多,不同层级要关注的指标也各有不同。
很多性能测试同学在工作中往往太过于关注服务层的技术指标,其实所谓的TPS/ART/99RT只是反映了服务在当前的负载下的性能表现,这是结果。但是为什么是这个数值?哪些因素影响了它的性能表现?如何优化性能?就需要从不同维度去分析定位,这才是性能测试中真正的价值所在。
常见监控工具
聊完了不同视角的性能指标和监控分层后,来看看有哪些常见的监控工具。如下表:
| 工具名称 | 工具作用 | 类似工具 |
| grafana | 可视化监控面板,可自由定制 | kibana |
| exporters | 数据采集工具,兼容多种操作系统 | telegraf |
| promethous | 时序数据库,存储exporters采集的数据 | influxdb |
| skywalking | 链路追踪,请求调用链耗时/状态展示 | cat/pinpoint |
| mysqlreport | mysql全局监控工具 | pt-query-digest |
| jvisualvm | Java代码分析工具,JVM自带 | arthas/google-perftools |
上面提到的工具,像grafana+exporters+permethous,是目前使用范围最广的监控工具组合,它可以覆盖上面第二部分提到的绝大部分维度的数据采集和存储以及展示。
当然,像链路追踪、代码分析工具及针对特定技术组件(如mysql)的监控分析工具,是否在团队内使用要看具体情况。选择合适的工具在合适的场景,灵活解决问题即可。
上面提到了监控分层和不同层级的监控工具,在实际的落地过程中,还需要考虑其他问题,如监控工具落地的难易程度,落地成本,接入工具对性能的影响等,都是需要考虑的点。
想了解更多关于监控体系搭建的内容,请关注今晚直播:
最后回答一下文章开头提到的问题:如果对某些监控指标理解有误,建议系统的了解一下监控分层和不同的技术指标是在什么背景和场景下出现的。而不是用自己的已知认知模型去强行理解不了解的认知领域。
声明:文中观点不代表本站立场。本文传送门:https://eyangzhen.com/387061.html
