
前段时间,知识星球里一位同学给我分享了他对消息队列的理解,并且用一个故事形象的表述了消息队列的作用。看完他的表述,我觉得用故事来描述技术组件作用的方式很有意思,也更容易让人理解。这篇文章,借用他的故事,为大家简单介绍一下消息队列。
消息队列的故事
假设现在有一本技术百科全书,我们将其称之为一个集群。如果你想看互联网IT技术方面的内容,首先你需要去翻看目录寻找它,这里的目录就是消息队列里的Topic(主题)。找到对应目录后,你想了解IT技术里面关于系统架构的内容,那只需要按照目录索引翻到对应的页码即可,这个页码就可以理解为Partition(分区)。这本百科全书的内容来自于作者,作者会不定时更新内容,这里可以将作者视为Producer(生产者)。而翻看阅读这些内容的你,就是Consumer(消费者)。和你类似的都喜欢看这方面内容的人群,就可以称之为Consumer Group(消费组)。如果书本太厚或者一时没有看完,我们的习惯是折一个页码作为标记,方便我们下次继续从这里开始阅读,这里的标记就是所谓的offset(偏移量),你可以将其视为对消息进行标记。不论是各种MQ还是Kafka,都是消息缓存的中间件,统称为消息队列,他们都有发布、存储和订阅消费消息的能力。好了,故事讲完了,这就是关于消息队列的借物理解方式,是不是很形象。下面的内容是关于消息队列这一中间件的详细介绍。
消息队列功能概述
消息队列(Message Queue,简称MQ)是指保存消息的一个容器,其本质是一个保存数据的队列。消息队列时分布式系统中重要的技术组件,主要解决应用解耦、异步消息、流量削峰等问题,实现高性能、高可用、可伸缩和最终一致性的系统架构。目前使用较多的消息队列有ActiveMQ、RabbitMQ、RocketMQ、Kafka等。

消息队列的应用场景
消息队列的特点就是利用高效可靠的消息传递机制,对软件系统中上下游应用服务间的数据交互进行解耦。它的主要应用场景有四种,分别是:应用解耦、异步处理、消息通讯和流量削峰填谷。
应用解耦
如下图所示,是一个典型的电商订单业务链路图: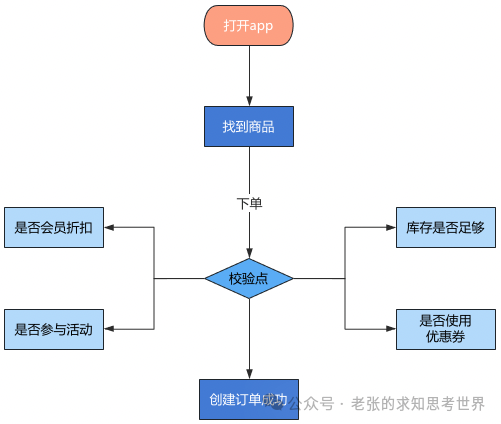 正常来说,用户想要购买一件商品,点击下单后,需要经过如上多个环节。且每个环节都要进行校验,比如库存是否足够,商品是否参与会员折扣,是否有优惠券等。只要其中一个强依赖的下游应用调用超时或者失败,那这笔订单就无法创建成功。采用消息队列之后,订单服务只需要将下单的消息发送到MQ中,然后下游各个服务从MQ中获取消息并执行对应的业务逻辑即可。这种异步方式降低了各应用服务之间的耦合程度,订单服务的开发同学只需要搞定自己负责部分的逻辑即可。且MQ本身就具备的高可用性可以保证数据不丢失,而且它还具备重试机制,即使请求超时依然可以尝试再次调用,以确保业务逻辑闭环。
正常来说,用户想要购买一件商品,点击下单后,需要经过如上多个环节。且每个环节都要进行校验,比如库存是否足够,商品是否参与会员折扣,是否有优惠券等。只要其中一个强依赖的下游应用调用超时或者失败,那这笔订单就无法创建成功。采用消息队列之后,订单服务只需要将下单的消息发送到MQ中,然后下游各个服务从MQ中获取消息并执行对应的业务逻辑即可。这种异步方式降低了各应用服务之间的耦合程度,订单服务的开发同学只需要搞定自己负责部分的逻辑即可。且MQ本身就具备的高可用性可以保证数据不丢失,而且它还具备重试机制,即使请求超时依然可以尝试再次调用,以确保业务逻辑闭环。
异步处理
异步处理和同步是相对的。所谓同步,就是发送方发起请求调用,接收方接收并进行处理然后返回数据给发送方,在没有得到结果之前,该请求调用不会返回。我们常见的方法调用大部分都是同步处理,比如SendMessage。但同步处理的方式相对来说效率太低,特别是对一个复杂且高并发的系统中,这种低下的效率是难以接受的。消息队列具有异步通信机制,可以使发送消息的应用组件不需要等待接收消息的组件处理完毕并返回数据,从而提高系统的响应速度和处理效率。比如最近天气很热,你朋友请你去享受足道服务,店里会提供泡脚、按摩,同时还有免费的水果零食和空调。如果是在自己家里,你需要打水,清洗水果,打开空调,购买零食,这样无疑效率很低。但去了足道店,你只需要刷卡付钱就可以直接享受这些服务,效率高的同时,用户体验也能提升很多。
流量削峰填谷
还是以电商业务为例,每次双11大促,对系统的性能和稳定性都是一大考验,很多公司的系统在面临这种高并发场景时都跪了。而消息队列的特性可以让它在面临高并发和大流量场景时,充当系统应用和数据库之间缓冲层,让瞬时的峰值流量较为平滑的传递到下游,避免系统被瞬时高并发请求打挂。 如上图所示,假设每秒有1W的下单请求,即10000并发,而订单服务当前的性能每秒最多处理4000个请求,即订单服务的TPS为4000。如果不对请求加以缓冲处理,那如此高的并发会很快把订单服务和下游的数据库搞崩。消息队列这个时候就可以派上用场:将用户下单请求都统一放进队列里,订单应用按照自己的性能慢慢处理这些请求,也给数据库喘口气的时间。这也是性能优化中很有意思的一个概念:用空间换时间。如上就是关于消息队列最基本的介绍和应用场景。下一篇文章,我会以Kafka为例,详细介绍消息队列的功能特性,大家敬请期待。
如上图所示,假设每秒有1W的下单请求,即10000并发,而订单服务当前的性能每秒最多处理4000个请求,即订单服务的TPS为4000。如果不对请求加以缓冲处理,那如此高的并发会很快把订单服务和下游的数据库搞崩。消息队列这个时候就可以派上用场:将用户下单请求都统一放进队列里,订单应用按照自己的性能慢慢处理这些请求,也给数据库喘口气的时间。这也是性能优化中很有意思的一个概念:用空间换时间。如上就是关于消息队列最基本的介绍和应用场景。下一篇文章,我会以Kafka为例,详细介绍消息队列的功能特性,大家敬请期待。
声明:文中观点不代表本站立场。本文传送门:https://eyangzhen.com/419002.html


