
起因:
由于生产K8S集群需要踢出一个已存在的节点后重新加入,在清理node节点环境的过程中,误将需要在node节点上执行的删除cni0虚拟网卡的操作在master节点上执行了。由于资源问题,我们的master节点也部署了很多的业务pod。这个操作导致master节点上非hostnetwork的pod的网络通信全部中断。很多业务受到了影响,告警也很及时。
误操作命令:
ip link del cni0紧急修复:
为了尽快恢复业务,我直接将master节点强制排水了。将节点上的pod驱逐到了其它节点上,使得业务尽快得以恢复。
kubectl drain master01 --ignore-daemonsets --delete-emptydir-data// 注意排水后,观察pod重调度部署情况。确认所有pod正常启动恢复业务!后续:
业务是恢复了,但是master节点上的pod网络还是不通的。我想到了两种恢复手段。第一,直接将节点踢出集群,然后重新加入。第二,尝试手工恢复cni0虚拟网卡,将pod网络接回来。第一种简单粗暴些,考虑到重新加入集群执行的脚本中,因为迭代过的原因,可能有些参数或者内核参数变更过。为了避免出现修改影响到master组件。我倾向于尝试第二种方式。
要将pod网络接回来,就要了解K8S flannel组件的通信原理和连接方式。需要理解pod虚拟veth pair对是如何工作的?这里主要涉及flannel的工作原理,网络名称空间的基本机制和操作。
首先,flannel(vxlan模式)的工作原理如下:
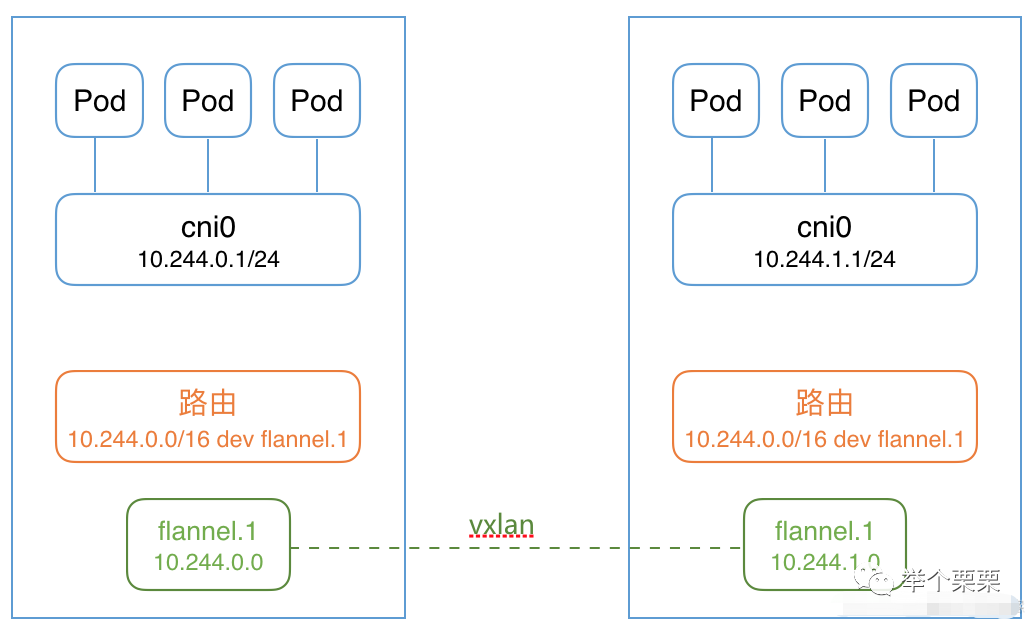

如下是pod进出网络流量大致流程:
- pod中产生数据,根据pod的路由信息,将数据发送到cni0;
- cni0 根据node节点的路由表,将数据发送到隧道设备flannel.1;
- flannel.1查看数据包的目的ip,从flanneld获得对端隧道设备的必要信息,封装数据包;
- flannel.1将数据包发送到对端设备。对端节点的网卡接收到数据包,发现数据包为overlay数据包,解开外层封装,并发送内层封装到flannel.1设备;
- 数据达到node节点的flannel.1设备查看数据包,根据路由表匹配,将数据发送给cni0设备;
- cni0匹配路由表,发送数据给网桥上对应的端口。
从通信过程可以知道,pod的网络需要连接到cni0网桥,而cni0和flannel.1网桥之间是没有连接的,通过node节点的路由表来实现转发通信的。所以,这里只需要将node节点所有的pod的网络虚拟对(veth pair)找到,然后将其中一端连接到重新创建的cni0虚拟网桥应该就可以了。变成了如下两个问题:
第一:如何创建cni0网桥并配置正确对应的参数?
由于flannel使用的是vxlan模式,所以创建cni0网桥的时候需要注意mtu值的设置。如下,创建cni0网桥:
// 创建cni0设备,指定类型为网桥# ip link add cni0 type bridge# ip link set dev cni0 up// 为cni0设置ip地址,这个地址是pod的网关地址,需要和flannel.1对应网段# ifconfig cni0 172.28.0.1/25// 为cni0设置mtu为1450# ifconfig cni0 mtu 1450 up
// 查看创建情况# ifconfig cni0cni0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450 inet 172.28.0.1 netmask 255.255.255.128 broadcast 172.28.0.127 ether 0e:5e:b9:62:0d:60 txqueuelen 1000 (Ethernet) RX packets 487334 bytes 149990594 (149.9 MB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 629306 bytes 925100055 (925.1 MB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0// 此时查看路由表,也已经有了去往本机pod网段的cni0信息# route -n | grep cni0172.28.0.0 0.0.0.0 255.255.255.128 U 0 0 0 cni0第二:如何准确找出每个pod的对应的veth pair虚拟对,是否和名称空间有关系?
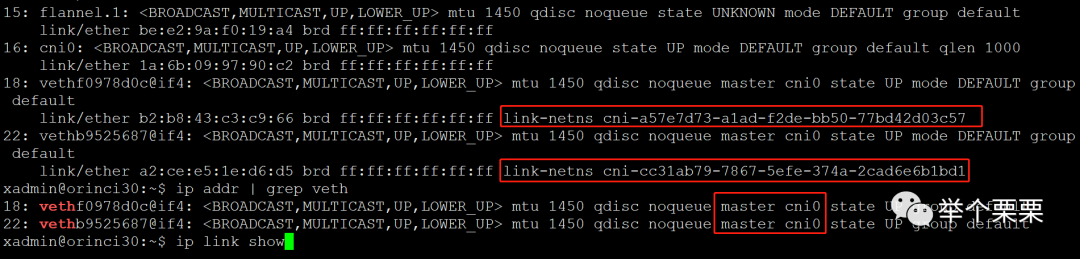
在一台只有两个pod的节点上查看虚拟网卡的情况,发现在node主机上可以看到两个veth前缀的虚拟网卡,它们的另一端在pod中,并且pod的netns也可以通过show命令看到。值得注意的是,在node节点同网络名称空间下的vethf0978d0c和vethb9525687的连接设置master为cni0。所以,找到所有的veth前缀的虚拟网卡,并将其挂载到cni0上即可。
// 这里通过一个简单的脚本批量将veth的虚拟网卡挂载到cni0网桥上for veth in $(ip addr | grep veth | grep -v master | awk -F'[@|:]' '{print $2}' | sed 's/ //g')do ip link set dev $veth master cni0done通过以上两步操作后,失联的pod已经可以ping通,并和其它节点的pod正常通信了。测试新建删除pod都是正常的。
至此,手工恢复cni0算是完成了。如果还有下次 ip link del cni0的操作,可以不做节点排水操作。通过这个方式以最快,影响最小的方式恢复pod网络通信。这里也暴露了一个问题,那就是master节点的操作规范问题,对于生产环境,我们应该尽可能避免直接登录到master节点上进行操作,应该在其它管理机上授权k8s权限去操作。然后master节点尽量和业务分开独立部署,以保证master节点的稳定性。
声明:文中观点不代表本站立场。本文传送门:https://eyangzhen.com/18991.html



