
im2col是什么?
Rearrange image blocks into columns,即将图像转换为列,是干嘛的呢?这是深度学习卷积操作前最重要的一步。我们将图像转换为列之后,就可以和卷积核进行矩阵相乘了。
im2col就是最基本的底层实现,不论Pytorch还是TensorRT都使用到了这个思想。我们也可以利用这个思想去实现不同的卷积操作,例如DCN,也就是我们常见的可变形卷积(deformable convolution)。在量化理论推导的时候也会用到这个思想,总之就是很重要啦,老潘之后会发一些量化的东西,这篇就算是铺垫吧~


本文就按照caffe中卷积的过程来说吧,大家也知道caffe中卷积采用的也是im2col和sgemm的方式。这样可以将卷积操作转换为矩阵运算,从而并行化通过GPU来加速,可以这样说,模型想要快,就必须提升im2col和sgemm的速度。

开始讲吧~
需要注意,caffe中的数据是行优先(row-major)存储的。我们平常处理的图像和卷积核,在内存中一般也都是连续的,这点需要注意。
来个卷积操作,参数如下:
- 输入图像batch input_num = 1
- 输入通道 input_channel = 1
- 输入图像高 input_h = 4;
- 输入图像宽 input_w = 4;
- 卷积核高 kernel_h = 3;
- 卷积核宽 kernel_w = 3;
- 步长 stride = 1;
- pad = 0;
卷积操作后,输出图像的计算公式如下,我们这里暂时不考虑padding:
- output_h = (input_h-kernel_h) / stride + 1;
- output_w = (input_w-kernel_w) / stride + 1;
首先将输入图像的像素点按照“卷积区域”,挨个排列起来:
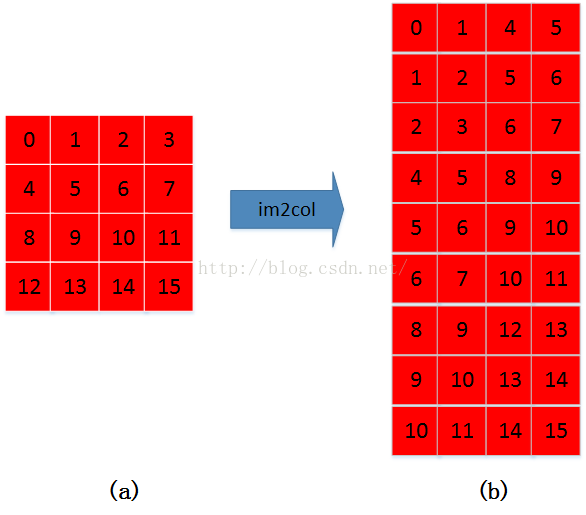
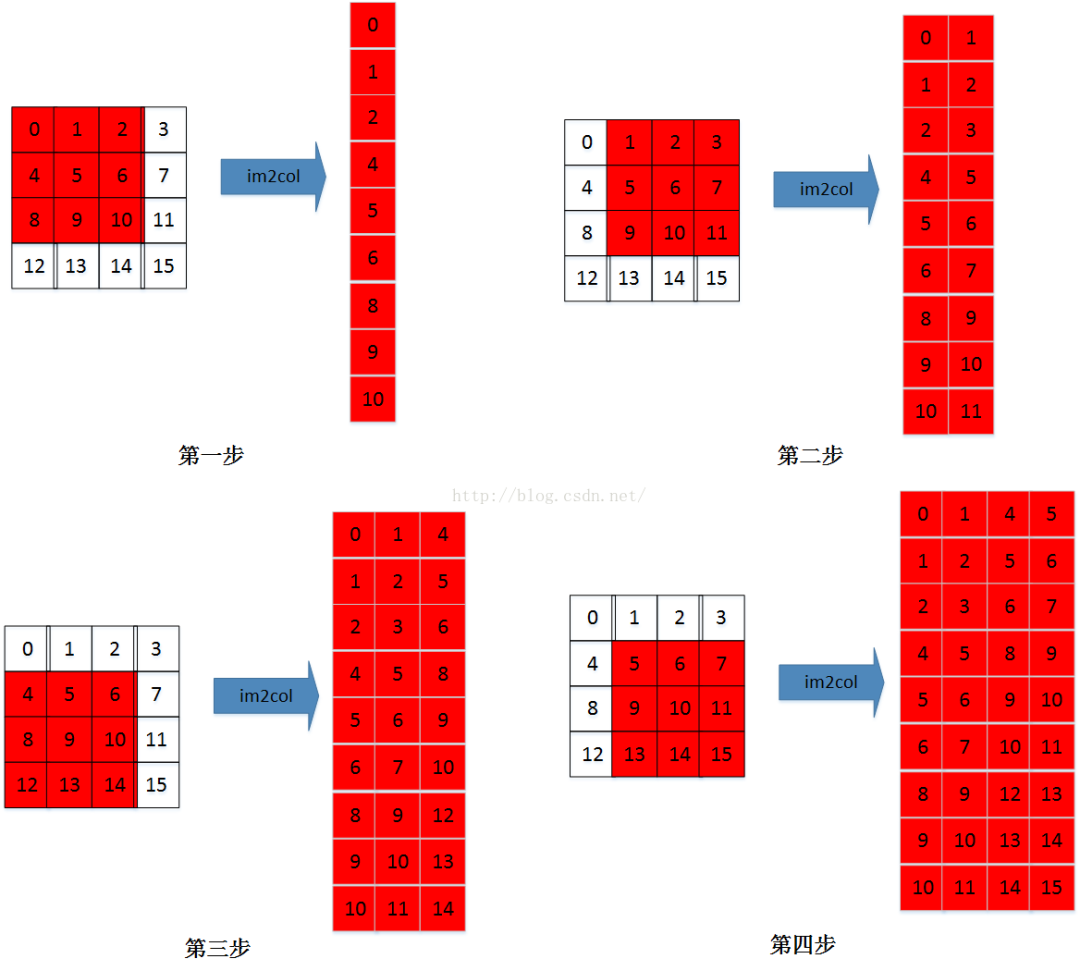
详细描述下过程,图a按照从左到右、从上到下的过程,将图a中kernel大小为3*3的矩阵按行拉平成右图b中的一列。具体过程如下图所示:
这样就把输入图像按照卷积核大小变成了矩阵的形式!
但是我们平常的图像有可能是彩色图,假设有三个通道(R、G、B)图像通道 input_channel=3。图像在内存中的存储是连续的,首先是第一通道的数据,然后再第二通道的数据,最后第三通道的数据:
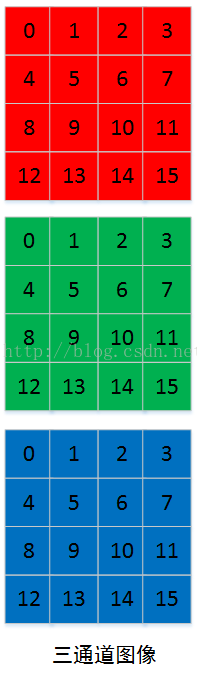
多通道的im2col的过程,是首先im2col第一通道,然后在im2col第二通道,最后im2col第三通道。需要注意各通道im2col的数据在内存中也是连续存储的,全部弄好后拼成这样的矩阵!

图像的每个通道对应一个kernel通道,如下图,为了方便这里kernel的值都是1,有三个通道的kernel:
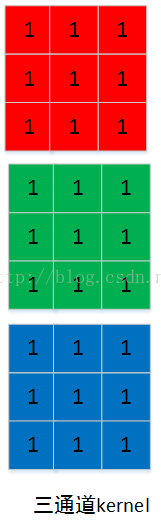
kernel的通道数据在内存中也是连续存储的。
同样将卷积核打平成矩阵的形式:

接下来就是矩阵乘法了,也就是所谓的sgemm。
矩阵乘法可以直接使用CUDA中的cublas库,常用的也就是3个参数,M是左边矩阵的行数,这里的kernal是一行,因此M=1;而N表示输出矩阵的列,也就是输出图像一共多少个像素点;K表示左边输入矩阵的列,右边输入矩阵的行;
- M=1
- N=output_h * output_w
- K=input_channels * kernel_h * kernel_w
如下图所示:
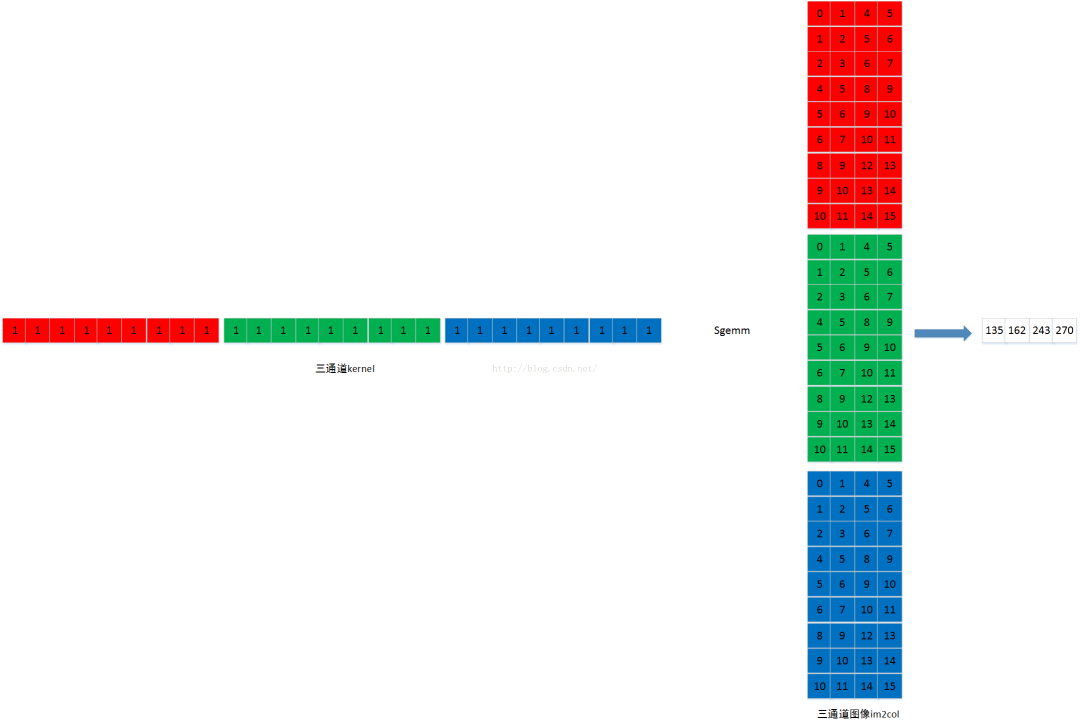
因为图像数据是连续存储,因此输出图像也可以如下图所示 output_h * output_w = 2*2:

如果我们输出的Tensor是多通道的,也就是说输入图像是(1,3,224,224),输出是(1,3,112,112),那么参数变化为这样:
- M=output_channels ,
- N=output_h * output_w
- K=input_channels * kernel_h * kernel_w
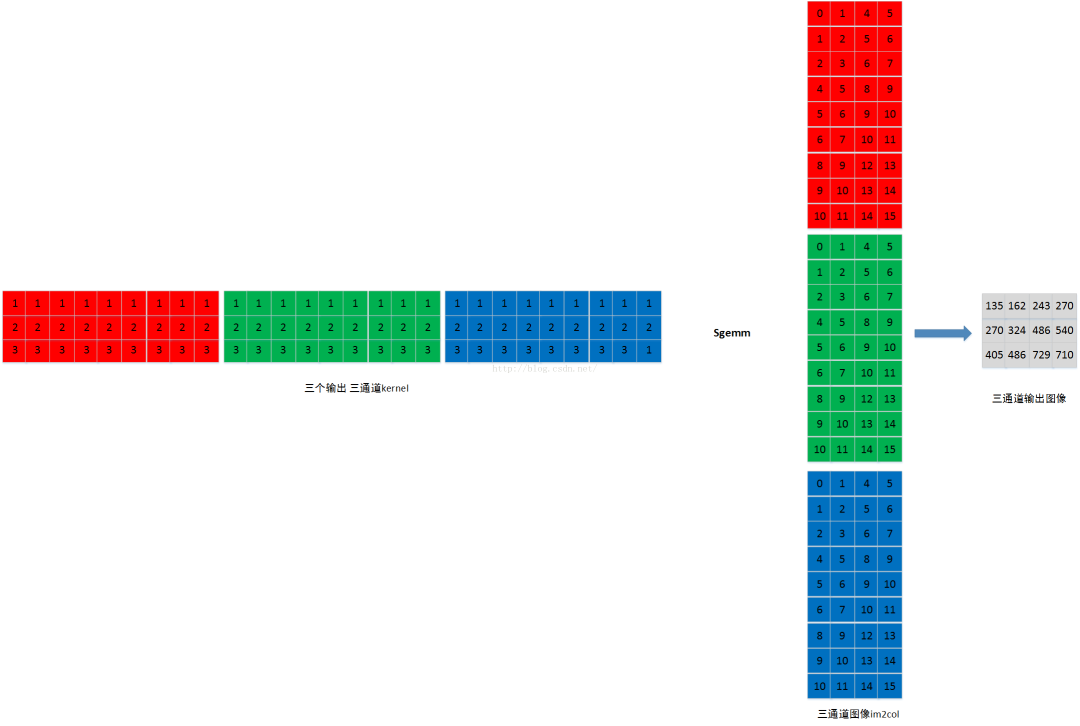
同样,多个输出通道图像的数据是连续存储,因此输出图像也可以如下图所示 output_channels*output_h * output_w = 3*2*2 :


过程图采集于网络
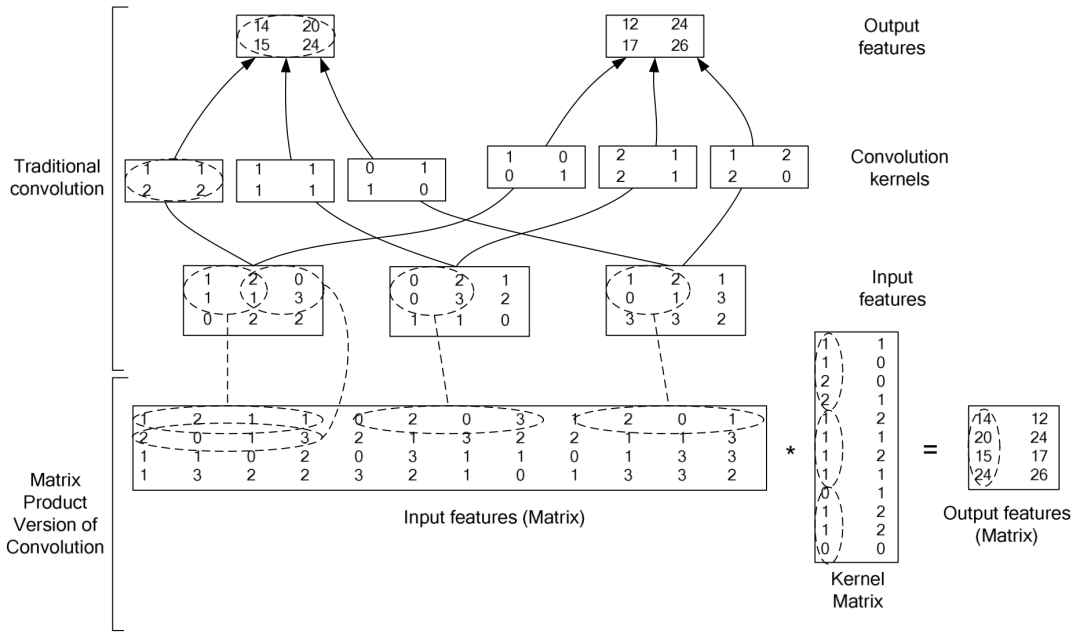
最后附一个完整的过程,以下这个图来自《High Performance Convolutional Neural Networks for Document Processing》这篇论文,探讨的更为详细,感兴趣的回复“025”获取~
声明:文中观点不代表本站立场。本文传送门:https://eyangzhen.com/202687.html



