
本章包括
- 剖析代码以发现速度和内存瓶颈
- 更有效地利用现有的Python数据结构
- 了解Python分配典型数据结构的内存成本
- 使用懒编程技术处理大量数据
有很多工具和库可以帮助我们编写更高效的Python。但是,在我们深入研究提高性能的所有外部选项之前,让我们先仔细看看如何编写在计算和IO性能方面都更高效的纯 Python代码。事实上,许多Python性能问题(当然不是全部)都可以通过更加注意Python的限制和能力来解决。
为了展示Python自身用于提高性能的工具,让我们将它们用于一个假设但现实的问题。假设您是一名数据工程师,负责准备对全球气候数据进行分析。这些数据将基于美国国家海洋和大气管理局(NOAA;http://mng.bz/ydge )的综合地表数据库。您的时间很紧,而且只能使用大部分标准Python。此外,由于预算限制,购买更强的处理能力也是不可能的。数据将在一个月后开始到达,您计划利用数据到达前的时间来提高代码性能。因此,您的任务就是找到需要优化的地方并提高其性能。
您要做的第一件事就是对现有的代码进行剖析,以便摄取数据。你知道现有的代码速度很慢,但在尝试优化之前,你需要找到瓶颈的经验证据。剖析之所以重要,是因为它能让您以严谨、系统的方式搜索代码中的瓶颈。最常见的替代方法–猜测,在这里尤其无效,因为许多减速点可能很不直观。
我们将了解纯Python提供了哪些开箱即用的功能来帮助我们开发性能更高的代码。首先,我们将使用几种剖析工具对代码进行剖析,以发现问题所在。然后,我们将重点关注Python的基本数据结构:列表、集合和字典。我们的目标是提高这些数据结构的效率,并以最佳方式为它们分配内存,以获得最佳性能。最后,我们将了解现代Python懒编程技术如何帮助我们提高数据管道的性能。
本章将主要讨论在没有外部库的情况下优化Python,但我们仍将使用一些外部工具来帮助我们优化性能和访问数据。我们将使用Snakeviz来可视化Python剖析的输出,并使用line_profiler来逐行剖析代码。最后,我们将使用requests库从互联网下载数据。
2.1对具有IO和计算工作负载的应用程序进行剖析
我们的第一个目标是从气象站下载数据,并获取该气象站某一年的最低温度。NOAA 网站上的数据有 CSV 文件,每个年份一个,然后每个站点一个。例如,文https://www.ncei.noaa.gov/data/global-hourly/access/2021/01494099999.csv 包含01494099999气象站2021年的所有条目。其中包括温度和气压等条目,每天可能会记录多次。
让我们开发一个脚本,下载一组站点在某一年份间隔内的数据。下载相关数据后,我们将得到每个站点的最低气温。
2.1.1 下载数据并计算最低气温
我们的脚本将有一个简单的命令行界面,通过该界面传递站点列表和感兴趣的年份间隔。
执行:
# 获取站点01044099999和02293099999 2021年的数据
$ python load.py 01044099999,02293099999 2021-2021
{'01044099999': -10.0, '02293099999': -27.6}
源码
import collections
import csv
import sys
import requests
stations = sys.argv[1].split(",") #站点用逗号分割
years = [int(year) for year in sys.argv[2].split("-")] #年份用区间表示
start_year = years[0]
end_year = years[1]
TEMPLATE_URL = "https://www.ncei.noaa.gov/data/global-hourly/access/{year}/{station}.csv"
TEMPLATE_FILE = "station_{station}_{year}.csv"
def download_data(station, year):
my_url = TEMPLATE_URL.format(station=station, year=year)
req = requests.get(my_url)
if req.status_code != 200:
return # not found
w = open(TEMPLATE_FILE.format(station=station, year=year), "wt")
w.write(req.text)
w.close()
def download_all_data(stations, start_year, end_year):
for station in stations:
for year in range(start_year, end_year + 1):
download_data(station, year)
# 用pandas更佳
def get_file_temperatures(file_name):
with open(file_name, "rt") as f:
reader = csv.reader(f)
header = next(reader)
for row in reader:
station = row[header.index("STATION")]
tmp = row[header.index("TMP")]
temperature, status = tmp.split(",")
if status != "1":
continue
temperature = int(temperature) / 10
yield temperature
def get_all_temperatures(stations, start_year, end_year):
temperatures = collections.defaultdict(list)
for station in stations:
for year in range(start_year, end_year + 1):
for temperature in get_file_temperatures(TEMPLATE_FILE.format(station=station, year=year)):
temperatures[station].append(temperature)
return temperatures
def get_min_temperatures(all_temperatures):
return {station: min(temperatures) for station, temperatures in all_temperatures.items()}
download_all_data(stations, start_year, end_year)
all_temperatures = get_all_temperatures(stations, start_year, end_year)
min_temperatures = get_min_temperatures(all_temperatures)
print(min_temperatures)现在,真正的乐趣开始了。我们的目标是在许多年里不断从许多站点下载大量数据。为了处理如此大量的数据,我们希望尽可能提高代码的效率。提高代码效率的第一步是有条理地全面剖析代码,找出拖慢代码运行的瓶颈。为此,我们将使用Python内置的剖析机制。
2.1.2 Python 内置剖析模块
我们要确保代码尽可能高效,首先要做的就是找到代码中存在的瓶颈。我们首先要做的就是对代码进行剖析,检查每个函数的耗时。为此,我们通过cProfile模块运行代码。请确保不要使用profile模块,因为它的速度要慢很多;只有当您自己开发剖析工具时,它才有用。
我们需要的是按累计时间排序的配置文件统计数据。使用该模块的最简单方法是在模块调用中将我们的脚本传递给profiler,如下所示:
$ python -m cProfile -s cumulative load.py 01044099999,02293099999 2021-2021 > profile.txt
$ cat profile.txt
{'01044099999': -10.0, '02293099999': -27.6}
387321 function calls (381489 primitive calls) in 16.216 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
174/1 0.000 0.000 16.216 16.216 {built-in method builtins.exec}
1 0.000 0.000 16.216 16.216 load.py:1(<module>)
1 0.000 0.000 16.013 16.013 load.py:25(download_all_data)
2 0.001 0.000 16.013 8.006 load.py:15(download_data)
2 0.000 0.000 15.973 7.986 api.py:62(get)
2 0.000 0.000 15.973 7.986 api.py:14(request)
2 0.000 0.000 15.972 7.986 sessions.py:500(request)
[...]
1 0.000 0.000 0.000 0.000 socks.py:78(SOCKS5AuthError)
在许多情况下I/O有可能在所需时间方面占据主导地位。在我们的例子中,既有网络I/O(从NOAA获取数据),也有磁盘I/O(将数据写入磁盘)。由于网络成本取决于沿途的许多连接点,因此即使在不同的运行中,网络成本也会有很大差异。由于网络成本通常是最大的时间损失,因此我们要尽量减少网络成本。
2.1.3 使用本地缓存减少网络使用量
为了减少网络通信,让我们在首次下载文件时保存一份副本,以备将来使用。我们将建立一个本地数据缓存。除了函数download_all_data外,我们将使用与前面相同的代码:
def download_all_data(stations, start_year, end_year):
for station in stations:
for year in range(start_year, end_year + 1):
if not os.path.exists(TEMPLATE_FILE.format(station=station, year=year)):
download_data(station, year)
执行结果:
$ python -m cProfile -s cumulative load_cache.py 01044099999,02293099999 2021-2021 > profile_cache.txt
$ head profile_cache.txt
{'01044099999': -10.0, '02293099999': -27.6}
316570 function calls (310825 primitive calls) in 0.187 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
172/1 0.000 0.000 0.187 0.187 {built-in method builtins.exec}
1 0.000 0.000 0.187 0.187 load_cache.py:1(<module>)
16 0.000 0.000 0.169 0.011 __init__.py:1(<module>)
1 0.007 0.007 0.103 0.103 load_cache.py:51(get_all_temperatures)虽然运行时间缩短了一个数量级,但IO仍然耗时最长。现在,不是网络问题,而是磁盘访问问题。这主要是由于计算量过低造成的。
缓存管理也可能存在问题,而且是常见错误的根源。在我们的示例中,文件从未随时间发生变化,但缓存的许多用例中,源文件可能会发生变化。在这种情况下,缓存管理代码需要认识到这个问题。我们将在本书的其他部分再次讨论缓存问题。
2.2 剖析代码以检测性能瓶颈
在这里,我们将研究CPU耗时最长的代码。我们将使用NOAA数据库中的所有站点计算它们之间的距离,这是一个复杂度为n2的问题。
由于我们要比较所有站点之间的距离,因此复杂度为 n2。
前面的代码需要很长时间才能运行。同时也会占用大量内存。如果您有内存问题,请限制要处理的站点数量。现在,让我们使用 Python 的剖析基础结构来看看大部分时间都花在哪里了。
2.2.1 可视化剖析信息
我们再次查找延迟执行的代码片段。但为了更好地检查跟踪,我们将使用外部可视化工具SnakeViz(https://jiffyclub.github.io/snakeviz/)。
# pip install snakeviz
$ python -m cProfile -o distance_cache.prof distance_cache.py
注意Python提供了pstats模块来分析写入磁盘的跟踪信息。您可以执行 python -m pstats distance_cache.prof,这将启动一个命令行界面来分析我们脚本的代价。有关该模块的更多信息,请参阅 Python 文档或第 5 章的剖析部分。
为了分析这些信息,我们将使用网络可视化工具SnakeViz。您只需执行snakeviz distance_cache.prof。这将启动一个交互式浏览器窗口(图 2.1 显示了一个截图)。
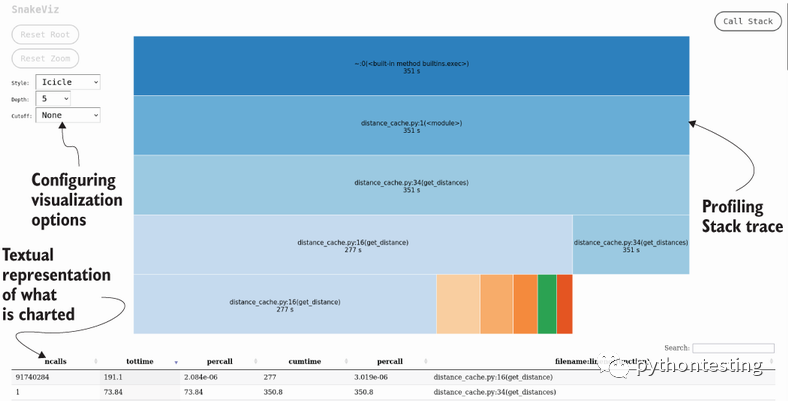

2.2 行剖析
我们将使用https://github.com/pyutils/line_profiler上。使用行剖析器非常简单:只需在 get_distance 中添加注解即可:
@profile
def get_distance(p1, p2):这是因为我们将使用line_profiler软件包中的便捷脚本kernprof来:
kernprof -l lprofile_distance_cache.py行剖析器所需的工具会大大降低代码的运行速度,慢上几个数量级。如果中断运行,仍会有跟踪记录。剖析器运行结束后,可以使用以下命令查看结果:
$ python -m line_profiler lprofile_distance_cache.py.lprof
Timer unit: 1e-06 s
Total time: 19.194 s
File: lprofile_distance_cache.py
Function: get_distance at line 16
Line # Hits Time Per Hit % Time Line Contents
==============================================================
16 @profile
17 def get_distance(p1, p2):
18 6285284 1038835.3 0.2 5.4 lat1, lon1 = p1
19 6285284 942398.6 0.1 4.9 lat2, lon2 = p2
20
21 6285284 1425843.5 0.2 7.4 lat_dist = math.radians(lat2 - lat1)
22 6285284 1342482.5 0.2 7.0 lon_dist = math.radians(lon2 - lon1)
23 6285284 611137.0 0.1 3.2 a = (
24 6285284 2646991.4 0.4 13.8 math.sin(lat_dist / 2) * math.sin(lat_dist / 2) +
25 12570568 3500465.6 0.3 18.2 math.cos(math.radians(lat1)) * math.cos(math.radians(lat2)) *
26 12570568 2468080.8 0.2 12.9 math.sin(lon_dist / 2) * math.sin(lon_dist / 2)
27 )
28 6285284 2877574.5 0.5 15.0 c = 2 * math.atan2(math.sqrt(a), math.sqrt(1 - a))
29 6285284 725911.4 0.1 3.8 earth_radius = 6371
30 6285284 950183.7 0.2 5.0 dist = earth_radius * c
31
32 6285284 664096.4 0.1 3.5 return dist
参考资料
- 软件测试精品书籍文档下载持续更新 https://github.com/china-testing/python-testing-examples 请点赞,谢谢!
- 本文涉及的python测试开发库 谢谢点赞! https://github.com/china-testing/python_cn_resouce
- python精品书籍下载 https://github.com/china-testing/python_cn_resouce/blob/main/python_good_books.md
- Linux精品书籍下载 https://www.cnblogs.com/testing-/p/17438558.html
2.2.3 Profiling小结
正如我们所看到的,作为第一种方法,内置剖析器总体上是一个很大的帮助;它也比行剖析快得多。但是行剖析的信息量要大得多,这主要是因为内置剖析不提供函数内部的细分。相反,Python的剖析只提供每个函数的累计值,并显示花费在子调用上的时间。在特定情况下,可以知道一个子调用是否属于另一个函数,但一般来说,这是不可能的。剖析的总体策略需要考虑到所有这些因素。
我们在这里使用的策略是一种普遍合理的方法:首先,尝试内置的cProfile,因为它速度快,而且能提供一些高级信息。如果这还不够,可以使用行剖析,它的信息量更大,但速度也更慢。请记住,在这里我们主要关注的是找到瓶颈;后面的章节将提供优化代码的方法。有时,仅仅改变现有解决方案的部分内容是不够的,还需要进行总体架构重构;我们也会在适当的时候讨论这个问题。
timeit可能是新手最常用的代码剖析方法,你可以在互联网上找到大量使用 timeit 模块的示例。使用timeit模块最简单的方法是使用IPython或Jupyter Notebook,因为这些系统能让timeit非常精简。例如,在IPython中,只需将%timeit魔法添加到你想要剖析的内容中即可:
In [1]: %timeit list(range(1000000))
18.5 ms ± 37.2 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
In [2]: %timeit range(1000000)
82.1 ns ± 0.721 ns per loop (mean ± std. dev. of 7 runs, 10,000,000 loops each)这将为您提供正在剖析的函数的多次运行时间。这个魔法将决定运行多少次并报告基本统计信息。在前面的代码段中,你可以看到range(1000000)和list(range(1000000))的区别。在这个具体案例中,timeit显示,range的懒惰版本比急切版本快两个数量级。
你可以在timeit模块的文档中找到更多细节,但在大多数情况下,使用IPython的%timeit功能就足够了。我们鼓励你使用IPython及其魔法,但在本书的其他大部分内容中,我们将使用标准解释器。有关%timeit魔法的更多信息,请访问:https://ipython.readthedocs.io/en/stable/interactive/magics.html。
声明:文中观点不代表本站立场。本文传送门:https://eyangzhen.com/276800.html
