
PLY是一种电脑文件格式,全名为多边形档案(Polygon File Format)或 斯坦福三角形档案(Stanford Triangle Format)。 该格式主要用以储存立体扫描结果的三维数值,透过多边形片面的集合描述三维物体,与其他格式相较之下这是较为简单的方法。它可以储存的资讯包含颜色、透明度、表面法向量、材质座标与资料可信度,并能对多边形的正反两面设定不同的属性。
在档案内容的储存上PLY有两种版本,分别是纯文字(ASCII)版本与二元码(binary)版本,其差异在储存时是否以ASCII编码表示元素信息。
文件格式
(本文并未提供完整的格式描述,以下仅介绍PLY的基本概念与格式)
每个PLY档都包含档头(header),用以设定网格模型的“元素”与“属性”,以及在档头下方接着一连串的元素“数值信息”。一般而言,网格模型的“元素”就是顶点(vertices)、面(faces),另外还可能包含有边(edges)、深度图样本(samples of range maps)与三角带(triangle strips)等元素。无论是纯文字与二元码的PLY档,档头资讯都是以ASCII编码编写,接续其后的数值资料才有编码之分。PLY档案以此行:
开头作为PLY格式的识别。接着第二行是版本资讯,目前有三种写法:
format ascii 1.0
format binary_little_endian 1.0
format binary_big_endian 1.0
其中ascii, binary_little_endian, binary_big_endian是档案储存的编码方式,而1.0是遵循的标准版本(现阶段仅有PLY 1.0版)。在档头中可使用’comment’作为一行的开头以编写注解,例如:
comment This is a comment!
描述元素及属性,必须使用’element’及’property’的关键字,一般的格式为element下方接着属性列表,例如:
element <element name> <number in file>
property <data_type> <property name 1>
property <data_type> <property name 2>
property <data_type> <property name 3>
‘property’不仅定义了资料的型态,其出现顺序亦定义了资料的顺序。内定的资料形态有两种写法:一种是char uchar short ushort int uint float double,另外一种是具有位元长度的int8 uint8 int16 uint16 int32 uint32 float32 float64。 例如,描述一个包含12个顶点的物体,每个顶点使用3个单精度浮点数 (x,y,z)代表点的座标,使用3个unsigned char代表顶点颜色,颜色顺序为 (B, G, R),则档头的写法为:
element vertex 12
property float x
property float y
property float z
property uchar blue
property uchar green
property uchar red
其中vertex是内定的元素类型,接续的6行property描述构成vertex元素的数值字段顺序代表的意义,及其资料形态。
另一个常使用的元素是面。由于一个面是由3个以上的顶点所组成,因此使用一个“顶点列表”即可描述一个面, PLY格式使用一个特殊关键字’property list’定义之。 例如,一个具有10个面的物体,其PLY档头可能包含:
element face 10
property list uchar int vertex_indices
‘property list’表示该元素face的特性是由一行的顶点列表来描述。列表开头以uchar型态的数值表示列表的项目数,后面接着资料型态为int的顶点索引值(vertex_indices),顶点索引值从0开始。
最后,标头必须以此行结尾:end_header
档头后接着的是元素资料(端点座标、拓朴连结等)。在ASCII格式中各个端点与面的资讯都是以独立的一行描述,而二元编码格式则连续储存这些资料,加载时须以’element’定义的元素数目以及’property’中设定的资料形态计算各笔字段的长度。
范例
一个典型的PLY档案结构分成三部分
档头(从ply开始到end_header)
顶点列表
面元素列表
头文件如下:

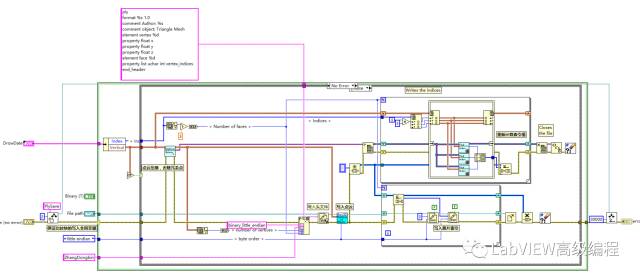
 写入PLY代码如下图所示:
写入PLY代码如下图所示:
首先写入头文件,再写入点云顶点、最后写入面片索引值,值得注意的地方是为减小文件的大小需要删除重复点(无损压缩)删除重复顶点后,原来的索引顺序改变,需要重新计算三角面片顶点的索引值,这里就用都前面《LabVIEW_删除重复项》讲到的,快速删除海量重复点及快速搜索数据的方法,当然为了加快处理速度,将重新计算索引值与写入文件做成异步处理,文件压缩与写入开并行,进一步加快处理速度。
声明:文中观点不代表本站立场。本文传送门:https://eyangzhen.com/314162.html



