
GPU的优势
为什么要用GPU呢,GPU相比CPU强在两点:
- much higher instruction throughput 吞吐量很大,一次性可以执行超多线程
- 牛逼的 memory bandwidth
GPU和CPU之间的能力差异存在,因为它们是根据不同的目标设计的。
CPU旨在以尽可能快的速度执行一系列操作(称为线程),并且可以同时执行几十个这些线程,但GPU旨在以并行方式执行数千个线程(通过分摊较慢的单线程性能来实现更大吞吐量)。
GPU专门用于高度并行计算,因此设计时更多的晶体管被用于数据处理而不是数据缓存和流控制。可以理解为CPU有几十员大将,而GPU则有几千名将士。
看下图的差异:
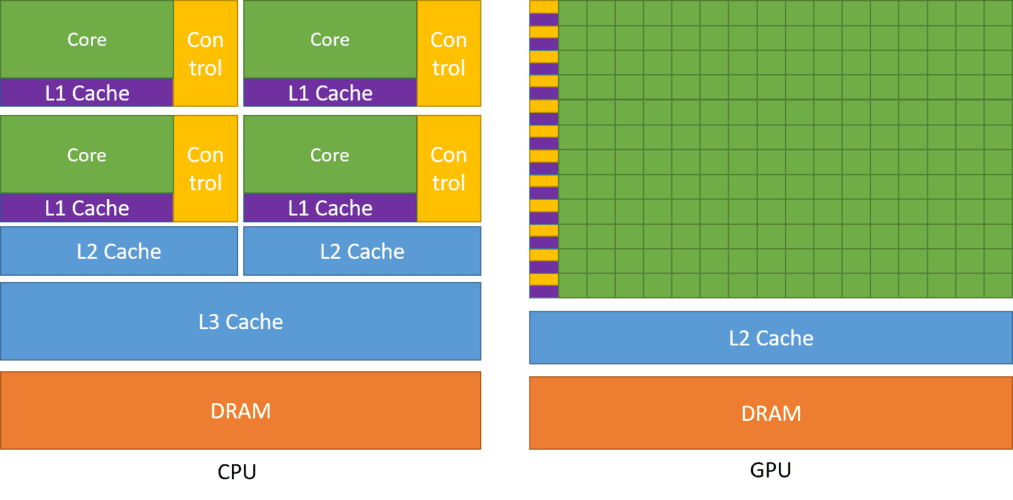

将更多的晶体管用于数据处理,例如浮点运算,对于高度并行计算是有益的;GPU可以通过计算来隐藏内存访问延迟,而不是依赖大型数据缓存和复杂的流控制来避免长时间的内存访问延迟,这个要注意。
隐藏延迟怎么解释呢?
- 当GPU的某些线程等待数据从内存中读取时,GPU可以运行其他线程来执行计算任务,从而“隐藏”了内存访问的延迟。这是通过GPU的高度并行性和多线程能力实现的。
- 传统的CPU为了减少从主内存访问数据的延迟,会依赖于大的数据缓存。这些缓存可以快速地提供数据给CPU,从而避免了频繁地从慢速的主内存中读取数据。
- 为了进一步优化性能,CPU还采用了复杂的流控制机制,如分支预测、乱序执行等,以确保CPU的执行单元始终忙碌。大的数据缓存和复杂的流控制机制都需要大量的晶体管。晶体管数量多意味着更大的芯片面积、更高的功耗和更高的成本。通过并行计算来隐藏内存访问延迟,而不是依赖于大的数据缓存和复杂的流控制机制。这使得GPU在处理大量并行计算任务时,如图形渲染或某些科学计算,能够表现得更加出色。
一般来说,一个应用程序会有顺序部分和并行部分(就像打仗必须有大将也必须有士兵),因此系统设计了一种GPU和CPU混合使用以最大化整体性能。具有高度并行性的应用程序可以利用GPU的大规模并行特性实现比CPU更高的性能。
CUDA
CUDA是一个可以支持并行的编程模型,支持很多语言,目前最多的就是和C++结合起来,当然也可以和python,比如pycuda 。
CUDA配备了一个软件环境,允许开发人员使用C++作为高级编程语言。正如图所示,还支持其他语言、应用程序编程接口或基于指令的方法,如FORTRAN、DirectCompute、OpenACC。
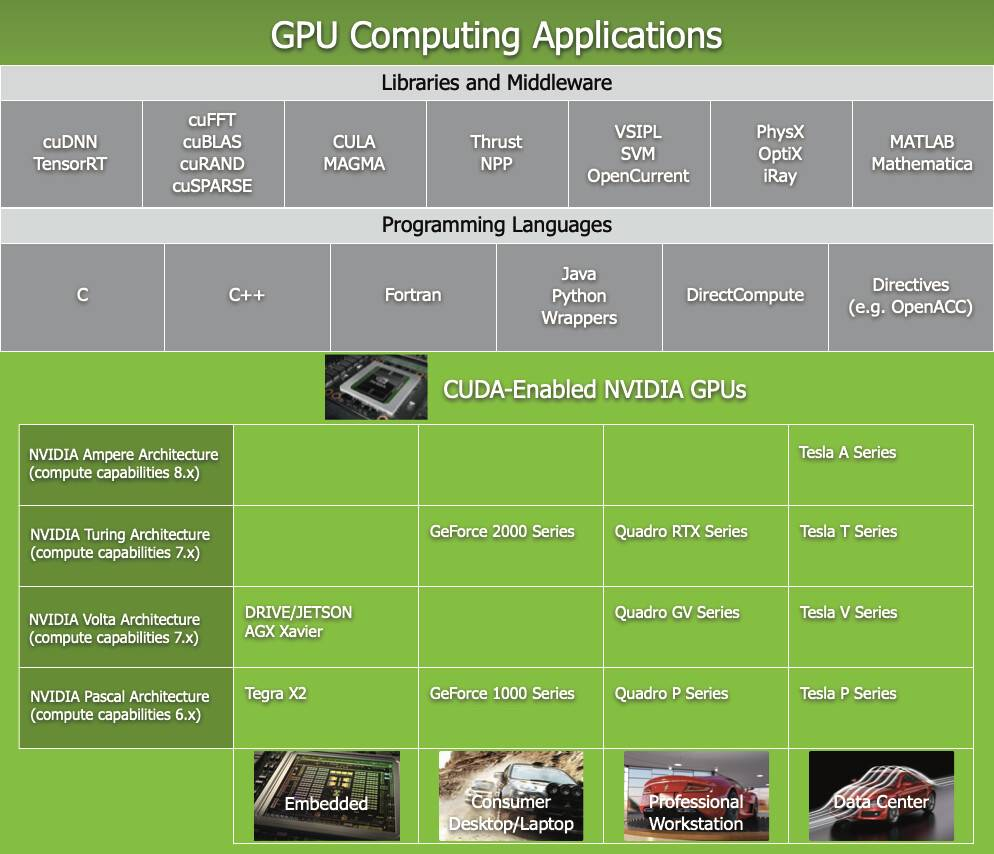
CUDA并行编程模型设计,旨在克服你使用它的难度(设计的让你更好更容易使用),同时对熟悉标准编程语言(如C)的程序员保持低学习曲线(如果你会c++,那么学cuda会快很多)。
它的核心是三个关键抽象—— a hierarchy of thread groups, shared memories, and barrier synchronization ——作为最小化语言扩展(在C++基础语法上稍微增加点语法)简单地暴露给程序员。
这些抽象提供了细粒度的数据并行性和线程并行性,它们嵌套在粗粒度的数据并行性和任务并行性之内。它们指导程序员将问题划分为可以由线程块独立并行解决的粗粒度子问题,并将每个子问题进一步划分为可以由块内的所有线程合作并行解决的更细粒度的部分。
上述说白了意思就是我们可以利用cuda的特性,合理安排我们要执行的任务,划分子任务啥的,让这些线程可以更好的执行我们的算法
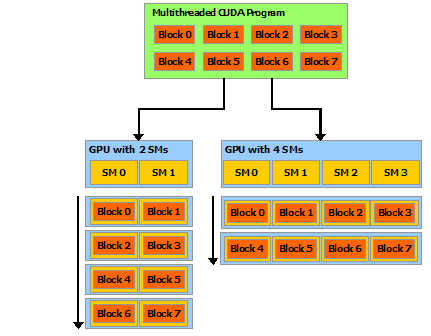
这种分解保留了语言的表达性,允许线程在解决每个子问题时进行合作,同时实现了自动可扩展性。实际上,每个线程块都可以在GPU内的任何可用的多处理器上按任何顺序调度,无论是并行还是顺序,因此一个编译后的CUDA程序可以在任何数量的多处理器上执行,如图所示,只有运行时系统需要知道物理多处理器的数量。也就是你写的一份cuda代码可以在不同GPU跑(不过想要极致性能的话,还是需要对特定GPU进行调优)。
下图,运行时系统需要知道当前的显卡有多少个SM,然后按照情况分配。
这种可扩展的编程模型允许GPU架构通过简单地扩展多处理器和内存分区的数量来覆盖广泛的市场范围:从高性能的爱好者级GeForce GPU和专业的Quadro和Tesla计算产品,到各种价格低廉的主流GeForce GPU(请参见CUDA-Enabled GPUs以获取所有支持CUDA的GPU的列表)。
GPU是由很多流处理器(SMs)构成的( see Hardware Implementation for more details)。一个多线程程序被分成执行彼此独立的线程块分发给各个SM,因此具有更多处理器的GPU将比具有较少处理器的GPU跑的更快。再通俗点,就是3080跑的比3060快,因为3080的sm比3060多
CUDA编程模型
接下来介绍了CUDA编程模型背后的主要概念,以概述它们在C++中的显现方式。
在编程接口中提供了对CUDA C++的详细描述。
Kernel
CUDA C++通过允许程序员定义称为kernel的C ++函数来扩展C ++,当调用时,这些kernel将由N个不同的CUDA线程并行执行N次,而不像常规C ++函数一样只执行一次。
使用__global__声明说明符定义kernel,并且对于给定kernel调用执行该kernel的CUDA线程数是使用新的<<<…>>>execution配置语法指定的(请参见C ++语言扩展)。执行kernel的每个线程都被赋予一个唯一的线程ID,在内核中可以通过内置变量进行访问。
作为示例,以下示例代码使用built-in变量threadIdx将大小为N的两个向量A和B相加,并将结果存储到向量C中:
// Kernel definition
__global__ void VecAdd(float* A, float* B, float* C)
{
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
int main()
{
...
// Kernel invocation with N threads
VecAdd<<<1, N>>>(A, B, C);
...
}这里,执行VecAdd()的N个线程中,每个都执行一次pair-wise addition.
线程 thread 层级
为了方便起见,threadIdx是一个三元素向量,以便使用一维、二维或三维线程索引来标识线程,形成称为线程块的一维、二维或三维线程块,类似于下面的定义:
dim3 threadIdx, blockDim, blockIdx;
struct __attribute__((device_builtin)) dim3
{
unsigned int x, y, z;
};这样的话,在这些场景下,比如vector, matrix, or volume的数据格式,使用这种三元素向量操作就很方便了。一个线程的索引和其线程 ID 之间有直接关系:对于一维块,它们是相同的;对于大小为 (Dx, Dy) 的二维块,索引为 (x, y) 的线程的 ID 是 (x + y Dx);对于大小为 (Dx, Dy, Dz) 的三位块,索引为 (x, y, z) 的线程的 ID 是(x + y Dx + z Dx Dy)。
例如,以下代码将两个大小为 NxN 的矩阵 A 和 B 相加,并将结果存储到矩阵 C 中:
// Kernel definition
__global__ void MatAdd(float A[N][N], float B[N][N],
float C[N][N])
{
int i = threadIdx.x;
int j = threadIdx.y;
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
...
// Kernel invocation with one block of N * N * 1 threads
int numBlocks = 1;
dim3 threadsPerBlock(N, N);
MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);
...
}
每个block的线程数是有限制的,因为一个block中的所有线程都应该驻留在同一个streaming多处理器核心上,并且必须共享该核心的有限内存资源(如何更好的分配资源是提升性能的一个考虑点)。在当前GPU上,一个线程块最多可以包含1024个线程。
但是,一个内核可以由多个形状相同的线程块执行,因此总线程数等于每个block中的线程数乘以block数。
如下图所示,block被组织成一维、二维或三维网格。网格中的线程块数量通常由正在处理的数据大小决定,这通常超过系统中处理器数量(一般超过的话,就会分批送进去,一个跑完换另一个跑)。这是因为GPU是为大规模并行处理设计的,它可以同时处理大量的线程。即使实际的物理处理器数量有限,GPU也可以通过在不同的线程块和线程之间切换来实现高效率。这种设计方法使得GPU能够高效地处理大量数据,即使这些数据远远超过了实际的处理器数量。
这种组织方式提供了灵活性,允许程序员根据处理的数据或问题的性质来选择最合适的布局。例如,处理图像时可能会选择二维网格,因为图像本身就是二维的。

<<<…>>>语法中指定的每个块内线程数和每个网格内块数可以是int或dim3类型。二维块或网格可以像上面的示例一样指定。
网格中的每个块都可以通过内核中可访问的一维、二维或三维唯一索引(通过内置blockIdx变量)进行标识。线程块的尺寸可通过内核中的内置blockDim变量进行访问。
将前面的MatAdd()示例扩展到处理多个块,代码如下所示。
// Kernel definition
__global__ void MatAdd(float A[N][N], float B[N][N],
float C[N][N])
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
if (i < N && j < N)
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
...
// Kernel invocation
dim3 threadsPerBlock(16, 16);
dim3 numBlocks(N / threadsPerBlock.x, N / threadsPerBlock.y);
MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);
...
}
一个16×16(256个线程)的线程块大小,在这种情况下虽然是任意选择,但是通常都会选择这样的大小。与之前一样,网格被创建为具有足够数量的块以便每个矩阵元素拥有一个线程。为了简单起见,本例假设每个维度中网格中的线程数可以被该维度中每个块中的线程数整除,尽管不必如此。
要求线程块能够独立执行:它们必须能够以任何顺序、并行或串行地执行。这种独立性要求允许将线程块按任意顺序跨越任意数量的核心进行调度,使程序员能够编写随着核心数量扩展而扩展的代码。
由于线程块可以独立地、在任何核心上、按任何顺序执行,程序员可以编写代码,该代码可以随核心数量的增加而自动扩展。这意味着,如果今天的GPU有16个核心,而明天的GPU有32个核心,相同的代码可以在新的GPU上运行得更快,因为它可以利用更多的核心来并行处理数据。
在一个块内部,通过共享数据和同步它们的执行来协作处理各自任务。更准确地说,在内核函数中可以通过调用__syncthreads() 内置函数来指定同步点;__syncthreads() 作为屏障,在所有线程等待之后才允许其中任何一个继续执行。除了 __syncthreads() 外, the Cooperative Groups API 还提供了丰富多彩的thread-synchronization primitives。
为了有效地协作,共享内存应该是靠近每个处理器核心的低延迟内存(类似于 L1 缓存),而 __syncthreads()开销不大。
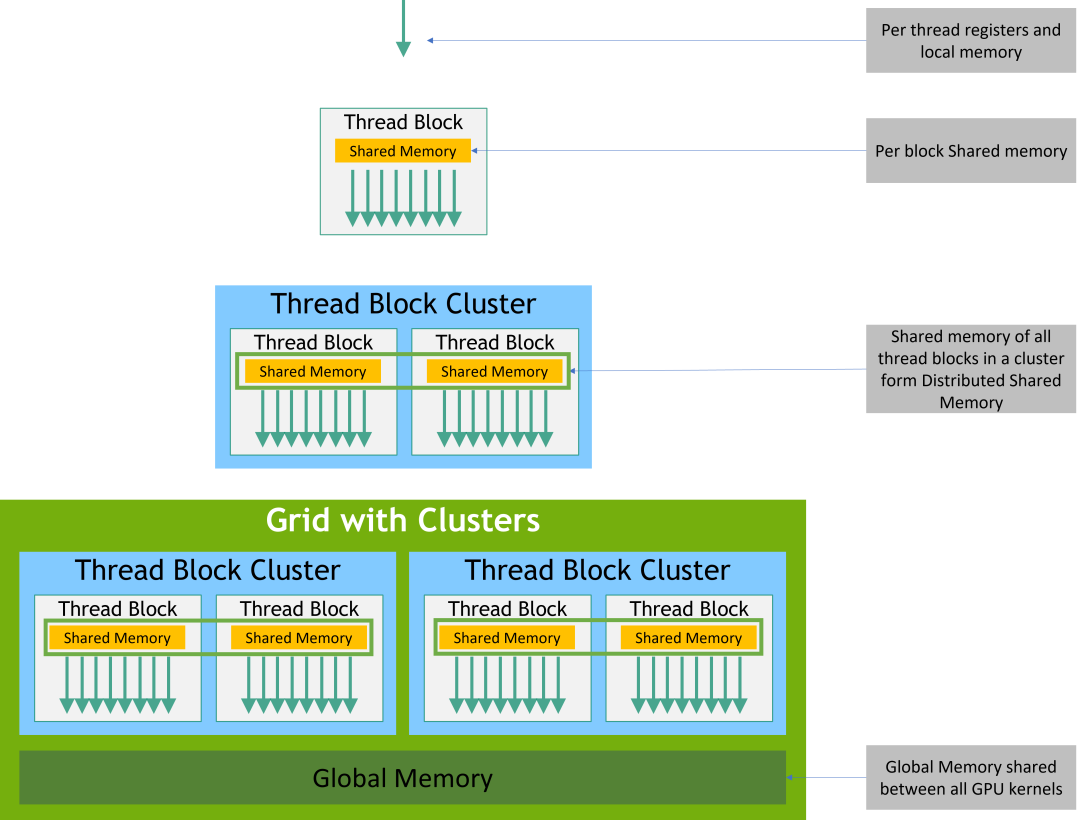
内存层级
CUDA线程在执行过程中可以从多个内存空间访问数据,如下图。每个线程都有private local memory。每个线程块都有 shared memory,对于该块中的所有线程可见,并且与该块具有相同的生命周期。Thread blocks in a thread block cluster可以在彼此的共享内存上执行读取、写入和原子操作。所有线程都可以访问相同的全局内存。
还有两个额外的只读内存空间可供所有线程访问:常量和纹理内存空间。全局、常量和纹理内存空间针对不同类型的memory 使用进行了优化。Texture memory 还提供了不同寻址模式以及某些特定数据格式 的数据filtering功能。
全局、常量以及纹理显在一个kernel启动的时候是一直存在的。
异构编程
如下图,CUDA编程模型假设CUDA线程在一个物理独立的设备上执行,该设备作为运行C++程序的主机的协处理器。例如,当内核在GPU上执行,而C++程序的其余部分在CPU上执行时,就是这种情况。
CUDA编程模型还假设主机和设备都在DRAM中维护自己独立的内存空间,分别称为主机内存和设备内存。因此,程序通过调用CUDA运行时(在编程接口中描述)来管理对内核可见的全局、常量和纹理内存空间。这包括设备内存的分配和释放以及主机和设备内存之间的数据传输。
统一内存提供了托管内存来连接主机和设备内存空间。所有系统中的CPU和GPU都可以访问托管内存,它作为一个具有共同地址空间的单一、连贯的内存映像。这种能力使设备内存能够超额订阅,并且通过消除显式在主机和设备上镜像数据的需要,可以极大地简化移植应用程序的任务。请参阅统一内存编程以了解统一内存的介绍。
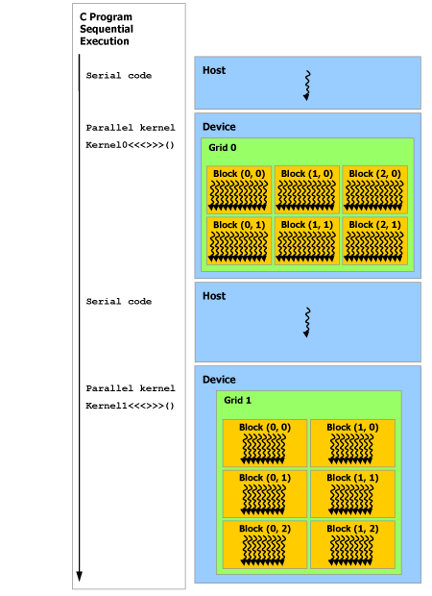
需要注意,在host上代码是串行运行,而device上是并行
异步SIMT编程模型
在CUDA编程模型中,线程是进行计算或内存操作的最低抽象级别。从基于NVIDIA Ampere GPU架构的设备开始,CUDA编程模型通过异步编程模型提供了对内存操作的加速。异步编程模型定义了与CUDA线程相关的异步操作行为。
异步编程模型定义了用于同步CUDA线程之间的异步屏障行为。该模型还解释和定义了如何使用cuda::memcpy_async在GPU上进行计算时异步移动全局内存中的数据。
异步操作
异步操作被定义为由CUDA线程启动并异步执行的操作,就像由另一个线程执行一样。在良好形式的程序中,一个或多个CUDA线程与异步操作同步。启动异步操作的CUDA线程不需要是同步线程之一。
这样的异步线程(类似于线程)始终与启动异步操作的CUDA线程相关联。异步操作使用同步对象来同步完成该操作。这种同步对象可以由用户显式管理(例如cuda::memcpy_async),也可以在库内隐式管理(例如cooperative_groups::memcpy_async)。
同步对象可以是cuda::barrier或cuda::pipeline。这些对象在《使用cuda::pipeline进行异步屏障和异步数据复制》中有详细解释。这些同 步对象可用于不同的线程范围 。范围定义了可能使用同步对象与异步操作同步的线程集合 。下表定义了CUDA C++ 中可用的线程范围及其可与每个范围进行同步的线程 。
| Thread Scope | Description |
|---|---|
cuda::thread_scope::thread_scope_thread | Only the CUDA thread which initiated asynchronous operations synchronizes. |
cuda::thread_scope::thread_scope_block | All or any CUDA threads within the same thread block as the initiating thread synchronizes. |
cuda::thread_scope::thread_scope_device | All or any CUDA threads in the same GPU device as the initiating thread synchronizes. |
cuda::thread_scope::thread_scope_system | All or any CUDA or CPU threads in the same system as the initiating thread synchronizes. |
These thread scopes are implemented as extensions to standard C++ in the CUDA Standard C++ library.
计算能力(Compute Capability)
设备的计算能力由版本号表示,有时也称为“SM版本”。此版本号标识GPU硬件支持的功能,并在运行时由应用程序用于确定当前GPU上可用的硬件特性和/或指令。
计算能力包括主要修订号X和次要修订号Y,并以X.Y表示。
具有相同主要修订号的设备具有相同的核心架构。基于NVIDIA Hopper GPU架构的设备主要修订号为9,基于NVIDIA Ampere GPU架构的设备主要修订号为8,基于Volta架构的设备主要修订号为7,基于Pascal架构的设备主要修订号为6,基于Maxwell架构的设备主要修订号为5,基 于 Kepler架构的设备主 要修订号为3。
次要修改编号对应着核心体系结构中递增改进,可能包括新功能。
turing是计算能力7.5设备使用的体系结构,并且是基于Volta体系结构进行增量更新。
不同的计算能力对数据类型的支持也不一样。
特定GPU的计算能力版本不应与CUDA版本混淆(例如,CUDA 7.5、CUDA 8、CUDA 9),后者是CUDA软件平台的版本。CUDA平台由应用程序开发人员使用,以创建可在许多代GPU架构上运行的应用程序,包括尚未发明的未来GPU架构。虽然新版CUDA平台通常通过支持该体系结构的计算能力版本来添加对新GPU体系结构的本机支持,但新版CUDA平台通常还包括独立于硬件生成的软件功能。
声明:文中观点不代表本站立场。本文传送门:https://eyangzhen.com/314787.html



