
这篇文章纯介绍VictoriaMetrics(以下简称:VM)在K8S上以Operator的方式部署并介绍几个我们在用的优化参数。其它的介绍和对比网上很多就不说了,安装配置提供一个参考。
一、架构
如下图所示,是我们现在的VM监控系统的结构:
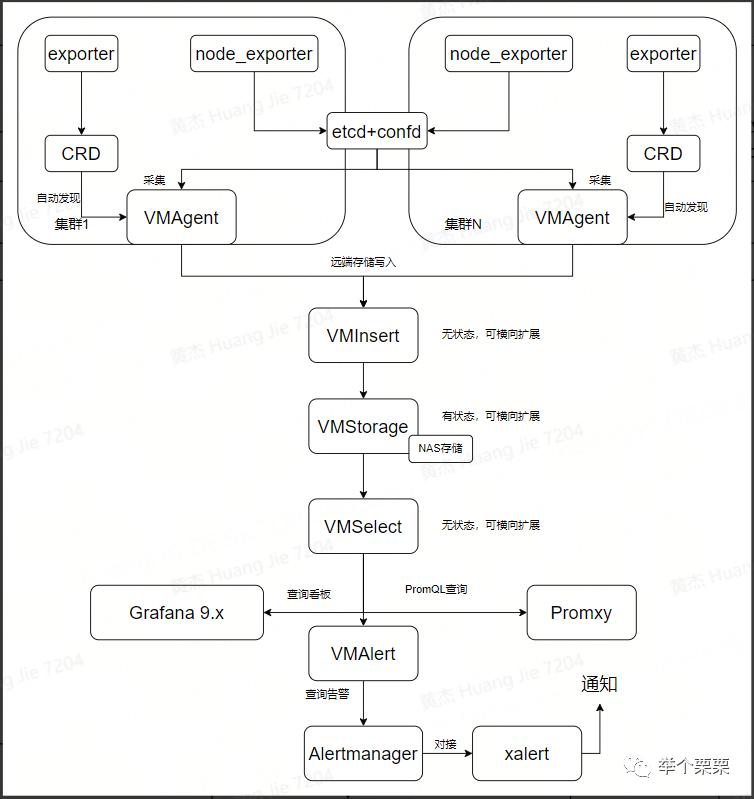

二、部署 – (使用Victoria Metrics Opetator管理VM集群)
vm-operator 定义了如下一些 CRD:
VMCluster:定义 VM 集群VMAgent:定义 vmagent 实例。支持不可靠远端存储,数据恢复方面相比 Prometheus 的 Wal ,VM 通过可配置 -remoteWrite.tmpDataPath 参数在远程存储不可用时将数据写入到磁盘,在远程存储恢复后,再将写入磁盘的指标发送到远程存储,在大规模指标采集场景下,该方式更友好。VMServiceScrape:定义从 Service 支持的 Pod 中抓取指标配置VMPodScrape:定义从 Pod 中抓取指标配置VMRule:定义报警和记录规则VMProbe:使用 blackbox exporter 为目标定义探测配置
此外该 Operator 默认还可以识别 prometheus-operator 中的ServiceMonitor、PodMonitor、PrometheusRule 和 Probe 对象,还允许你使用 CRD 对象来管理 Kubernetes 集群内的 VM 应用。vm-operator 提供了 Helm Charts 包,所以可以使用 Helm 来进行一键安装:
➜ helm repo add vm https://victoriametrics.github.io/helm-charts/➜ helm repo update➜ helm fetch vm/victoria-metrics-operator➜ helm show values vm/victoria-metrics-operator > values.yaml// 根据自己的需要定制 values 值:➜ helm upgrade --install victoria-metrics-operator vm/victoria-metrics-operator -f values.yaml -n monitoring --create-namespace➜ helm -n monitoring lsvictoria-metrics-operator monitoring 1 2023-05-07 19:11:36.551930525 +0800 HKT deployed victoria-metrics-operator-0.17.0 0.30.0这样vm-operator就部署好了,就可以通过crd创建vm集群了。
1. 安装vmcluster
# cat vmcluster.yaml apiVersion: operator.victoriametrics.com/v1beta1kind: VMClustermetadata: name: vmcluster namespace: monitoringspec: replicationFactor: 1 retentionPeriod: "6" imagePullSecrets: - name: "bigdata-sre-registry" vmstorage: image: pullPolicy: IfNotPresent repository: xxx.xxx/victoriametrics tag: vmstorage-v1.89.1 extraArgs: search.maxConcurrentRequests: "200" search.maxQueueDuration: 30s search.maxUniqueTimeseries: "3000000" resources: limits: cpu: 4 memory: 32Gi requests: cpu: 2 memory: 8Gi replicaCount: 6 storage: volumeClaimTemplate: spec: accessModes: - ReadWriteOnce resources: requests: storage: 1000G storageClassName: alicloud-nas-vm-monitoring storageDataPath: /vm-data vmselect: image: pullPolicy: IfNotPresent repository: xxx.xxx/victoriametrics tag: vmselect-v1.89.1 extraArgs: search.maxConcurrentRequests: "200" search.maxMemoryPerQuery: 1GB search.maxQueryDuration: 5m search.maxQueueDuration: 30s search.logSlowQueryDuration: 2m search.maxUniqueTimeseries: "3000000" resources: limits: cpu: 8 memory: 16Gi requests: cpu: 2 memory: 4Gi replicaCount: 4 cacheMountPath: /cache storage: volumeClaimTemplate: spec: storageClassName: alicloud-nas-vm-monitoring accessModes: - ReadWriteOnce resources: requests: storage: 5G vminsert: image: pullPolicy: IfNotPresent repository: xxx.xxx/victoriametrics tag: vminsert-v1.89.1 extraArgs: maxLabelsPerTimeseries: "150" resources: limits: cpu: 4 memory: 8Gi requests: cpu: 2 memory: 4Gi replicaCount: 4我这里使用了阿里云的NAS作为存储,所以还需要额外创建NAS的sc,如果使用本地存储则不需要。然后apply后vm集群就创建好了。
2. 安装vmagent
# cat additional-scrape-configs.yaml // 额外配置采集项apiVersion: v1kind: Secretmetadata: name: additional-scrape-configs namespace: monitoringstringData: prometheus-additional.yaml: |# cat vmagent.yaml apiVersion: operator.victoriametrics.com/v1beta1kind: VMAgentmetadata: name: vmagent namespace: monitoringspec: serviceScrapeNamespaceSelector: {} podScrapeNamespaceSelector: {} podScrapeSelector: {} serviceScrapeSelector: {} nodeScrapeSelector: {} nodeScrapeNamespaceSelector: {} staticScrapeSelector: {} staticScrapeNamespaceSelector: {} probeNamespaceSelector: {} replicaCount: 1 imagePullSecrets: - name: "bigdata-sre-registry" image: pullPolicy: IfNotPresent repository: xxx.xxx/victoriametrics tag: vmagent-v1.89.1 resources: limits: cpu: 4 memory: 8G requests: cpu: 2 memory: 4G inlineScrapeConfig: | - job_name: node_exporter honor_labels: false scrape_interval: 1m scrape_timeout: 1m file_sd_configs: - files: - /targets/confd/data/apply/node_exporter.yaml relabel_configs: - source_labels: ['account'] target_label: 'account' metric_relabel_configs: - source_labels: [__name__] separator: ; regex: (node_filesystem_files|node_filesystem_files_free|node_memory_SwapFree_bytes|node_memory_SwapTotal_bytes|node_memory_Inactive_bytes|node_memory_Active_bytes|node_memory_Committed_AS_bytes|node_memory_CommitLimit_bytes|node_memory_Inactive_file_bytes|node_memory_Inactive_anon_bytes|node_memory_Active_file_bytes|node_memory_Active_anon_bytes|node_memory_Writeback_bytes|node_memory_WritebackTmp_bytes|node_memory_Dirty_bytes|node_memory_Mapped_bytes|node_memory_Shmem_bytes|node_memory_ShmemHugePages_bytes|node_memory_SUnreclaim_bytes|node_memory_SReclaimable_bytes|node_memory_VmallocChunk_bytes|node_memory_VmallocTotal_bytes|node_memory_VmallocUsed_bytes|node_memory_Bounce_bytes|node_memory_AnonHugePages_bytes|node_memory_AnonPages_bytes|node_memory_KernelStack_bytes|node_memory_Percpu_bytes|node_memory_HugePages_Free|node_memory_HugePages_Rsvd|node_memory_HugePages_Surp|node_memory_HugePages_Total|node_memory_Hugepagesize_bytes|node_memory_DirectMap1G_bytes|node_memory_DirectMap2M_bytes|node_memory_DirectMap4k_bytes|node_memory_Unevictable_bytes|node_memory_Mlocked_bytes|node_memory_NFS_Unstable_bytes|node_vmstat_pswpin|node_vmstat_pswpout|node_vmstat_oom_kill|node_timex_loop_time_constant|node_timex_tick_seconds|node_timex_tai_offset_seconds|node_procs_blocked|node_procs_running|node_processes_state|node_forks_total|process_virtual_memory_bytes|process_resident_memory_max_bytes|process_virtual_memory_bytes|process_virtual_memory_max_bytes|node_processes_pids|node_processes_max_processes|node_schedstat_running_seconds_total|node_schedstat_waiting_seconds_total|node_processes_threads|node_processes_max_threads|node_interrupts_total|node_schedstat_timeslices_total|node_entropy_available_bits|process_max_fds|process_open_fds|node_systemd_socket_accepted_connections_total|node_systemd_units|node_disk_reads_merged_total|node_disk_writes_merged_total|node_disk_discards_completed_total|node_disk_discards_merged_total|node_network_receive_compressed_total|node_network_transmit_compressed_total|node_network_receive_multicast_total|node_network_receive_fifo_total|node_network_transmit_fifo_total|node_network_receive_frame_total|node_network_transmit_carrier_total|node_network_transmit_colls_total|node_arp_entries|node_network_mtu_bytes|node_network_speed_bytes|node_network_transmit_queue_length|node_softnet_processed_total|node_softnet_dropped_total|node_softnet_times_squeezed_total|node_network_up|node_network_carrier|node_sockstat_UDPLITE_inuse|node_sockstat_UDP_inuse|node_sockstat_UDP_mem|node_sockstat_FRAG_inuse|node_sockstat_RAW_inuse|node_sockstat_TCP_mem_bytes|node_sockstat_UDP_mem_bytes|node_sockstat_FRAG_memory|node_netstat_IpExt_InOctets|node_netstat_Ip_Forwarding|node_netstat_Icmp_InMsgs|node_netstat_Icmp_OutMsgs|node_netstat_Icmp_InErrors|node_netstat_Udp_InDatagrams|node_netstat_Udp_OutDatagrams|node_netstat_Udp_InErrors|node_netstat_Udp_NoPorts|node_netstat_UdpLite_InErrors|node_netstat_Udp_RcvbufErrors|node_netstat_Udp_SndbufErrors|node_netstat_Tcp_InSegs|node_netstat_Tcp_OutSegs|node_netstat_TcpExt_ListenOverflows|node_netstat_TcpExt_ListenDrops|node_netstat_TcpExt_TCPSynRetrans|node_netstat_Tcp_RetransSegs|node_netstat_Tcp_InErrs|node_netstat_Tcp_OutRsts|node_netstat_TcpExt_SyncookiesFailed|node_netstat_TcpExt_SyncookiesRecv|node_netstat_TcpExt_SyncookiesSent|node_scrape_collector_duration_seconds|node_scrape_collector_success|node_textfile_scrape_error|node_sockstat_sockets_used|up|node_filesystem_readonly|node_network_receive_errs_total|node_network_transmit_errs_total|node_timex_offset_seconds|node_timex_sync_status|node_network_up|node_filesystem_usage|node_filesystem_size|node_filesystem_free|node_uname_info|go_gc_duration_seconds|go_goroutines|process_resident_memory_bytes|process_cpu_seconds_total|node_cpu_seconds_total|machine_memory_bytes|machine_cpu_cores|node_boot_time_seconds|node_memory_MemAvailable_bytes|node_memory_MemTotal_bytes|node_memory_MemFree_bytes|node_memory_Buffers_bytes|node_memory_Cached_bytes|node_filefd_allocated|node_filesystem_avail_bytes|node_filesystem_size_bytes|node_filesystem_free_bytes|node_load15|node_load1|node_load5|node_disk_io_time_seconds_total|node_disk_read_time_seconds_total|node_disk_write_time_seconds_total|node_disk_reads_completed_total|node_disk_writes_completed_total|node_disk_io_now|node_disk_read_bytes_total|node_disk_written_bytes_total|node_disk_io_time_weighted_seconds_total|node_network_receive_bytes_total|node_network_transmit_bytes_total|node_netstat_Tcp_CurrEstab|node_sockstat_TCP_tw|node_netstat_Tcp_ActiveOpens|node_netstat_Tcp_PassiveOpens|node_sockstat_TCP_alloc|node_sockstat_TCP_inuse|node_exporter_build_info|http_request_duration_microseconds|http_response_size_bytes|http_requests_total|http_request_size_bytes|rest_client_requests_total|node_nf_conntrack_entries|node_nf_conntrack_entries_limit|node_processes_pids|node_processes_max_processes|node_network_receive_packets_total|node_network_transmit_packets_total|node_network_receive_drop_total|node_network_transmit_drop_total|node_context_switches_total|node_intr_total|node_vmstat_pgmajfault|node_vmstat_pgfault|node_vmstat_pgpgin|node_vmstat_pgpgout) replacement: $1 action: keep - job_name: kubelet bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token metrics_path: /metrics scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt insecure_skip_verify: true kubernetes_sd_configs: - role: node relabel_configs: - action: labelmap regex: __meta_kubernetes_node_label_(.+) - source_labels: - __metrics_path__ target_label: metrics_path - job_name: cadvisor bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token metrics_path: /metrics/cadvisor scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt insecure_skip_verify: true kubernetes_sd_configs: - role: node relabel_configs: - action: labelmap regex: __meta_kubernetes_node_label_(.+) - replacement: /metrics/cadvisor target_label: __metrics_path__ - replacement: kubelet target_label: job - source_labels: - __metrics_path__ target_label: metrics_path additionalScrapeConfigs: name: additional-scrape-configs key: prometheus-additional.yaml remoteWrite: - url: "http://vminsert-vmcluster.monitoring.svc.cluster.local:8480/insert/0/prometheus/api/v1/write" remoteWriteSettings: label: {"cloud": "aliyun", "dc": "wulanchabu", "cluster": "wulan-prod"} maxDiskUsagePerURL: 1073741824 tmpDataPath: "/tmp/vmagent-remotewrite-data" extraArgs: promscrape.maxScrapeSize: "1677721600" volumeMounts: - mountPath: /targets name: confd-nas-pvc volumes: - name: confd-nas-pvc persistentVolumeClaim: claimName: confd-nas-pvc如上,我是预先设置了几个必要的固定的采集job。
3. 安装vmalert
# cat vmalert-config.yamlapiVersion: v1kind: ConfigMapmetadata: name: vmalert-config namespace: monitoringdata: records.yaml: | groups: - name: k8s.rules rules: - expr: |- max by (cluster, namespace, workload, pod) ( label_replace( label_replace( kube_pod_owner{job="kube-state-metrics", owner_kind="ReplicaSet"}, "replicaset", "$1", "owner_name", "(.*)" ) * on(replicaset, namespace) group_left(owner_name) topk by(replicaset, namespace) ( 1, max by (replicaset, namespace, owner_name) ( kube_replicaset_owner{job="kube-state-metrics"} ) ), "workload", "$1", "owner_name", "(.*)" ) ) labels: workload_type: deployment record: namespace_workload_pod:kube_pod_owner:relabel - expr: |- sum by (cluster, namespace, pod, container) ( irate(container_cpu_usage_seconds_total{job="kubelet", metrics_path="/metrics/cadvisor", image!=""}[5m]) ) * on (cluster, namespace, pod) group_left(node) topk by (cluster, namespace, pod) ( 1, max by(cluster, namespace, pod, node) (kube_pod_info{node!=""}) ) record: node_namespace_pod_container:container_cpu_usage_seconds_total:sum_irate - expr: |- kube_pod_container_resource_requests{resource="cpu",job="kube-state-metrics"} * on (namespace, pod, cluster) group_left() max by (namespace, pod, cluster) ( (kube_pod_status_phase{phase=~"Pending|Running"} == 1) ) record: cluster:namespace:pod_cpu:active:kube_pod_container_resource_requests - expr: |- kube_pod_container_resource_limits{resource="cpu",job="kube-state-metrics"} * on (namespace, pod, cluster) group_left() max by (namespace, pod, cluster) ( (kube_pod_status_phase{phase=~"Pending|Running"} == 1) ) record: cluster:namespace:pod_cpu:active:kube_pod_container_resource_limits - expr: |- kube_pod_container_resource_requests{resource="memory",job="kube-state-metrics"} * on (namespace, pod, cluster) group_left() max by (namespace, pod, cluster) ( (kube_pod_status_phase{phase=~"Pending|Running"} == 1) ) record: cluster:namespace:pod_memory:active:kube_pod_container_resource_requests - expr: |- kube_pod_container_resource_limits{resource="memory",job="kube-state-metrics"} * on (namespace, pod, cluster) group_left() max by (namespace, pod, cluster) ( (kube_pod_status_phase{phase=~"Pending|Running"} == 1) ) record: cluster:namespace:pod_memory:active:kube_pod_container_resource_limits # cat VMAlert.yaml apiVersion: operator.victoriametrics.com/v1beta1kind: VMAlertmetadata: name: vmalert namespace: monitoringspec: replicaCount: 1 imagePullSecrets: - name: "bigdata-sre-registry" image: pullPolicy: IfNotPresent repository: xxx.xxx/victoriametrics tag: vmalert-v1.89.1 extraArgs: remoteWrite.maxQueueSize: "1000000" external.url: "http://vmalert.xxx.com" resources: limits: cpu: 1 memory: 4Gi requests: cpu: 500m memory: 2Gi datasource: url: "http://vmselect-vmcluster.monitoring.svc.cluster.local:8481/select/0/prometheus" notifier: url: "http://vmalertmanager-alertmanager.monitoring.svc.cluster.local:9093" remoteWrite: url: "http://vminsert-vmcluster.monitoring.svc.cluster.local:8480/insert/0/prometheus" remoteRead: url: "http://vmselect-vmcluster.monitoring.svc.cluster.local:8481/select/0/prometheus" evaluationInterval: "15s" port: "8080" rulePath: - /etc/vm/configs/vmalert-config/*.yaml configMaps: - vmalert-config ruleSelector: matchLabels: project: vmalert-sre部署好了之后就可以通过servicemonitor或者VMServiceScrape这两个CRD来配置采集job。如:
# cat vmservicescrape.yaml apiVersion: operator.victoriametrics.com/v1beta1kind: VMServiceScrapemetadata: name: debezium namespace: monitoringspec: endpoints: - interval: 30s path: /metrics port: metrics honorLabels: true namespaceSelector: matchNames: - warehouse-debezium-env-mongo-tms-prod selector: matchLabels: app: cp-kafka-connect# cat airflow-exporter.yamlapiVersion: monitoring.coreos.com/v1kind: ServiceMonitormetadata: labels: app: rancher-monitoring-airflow-metrics-exporter release: kube-prometheus-stack name: airflow-metrics-exporter namespace: monitoringspec: endpoints: - interval: 30s path: /admin/metrics/ port: airflow-ui namespaceSelector: matchNames: - airflow selector: matchLabels: component: webserver然后就可以在vmagent的ui页面查看到job状态了:
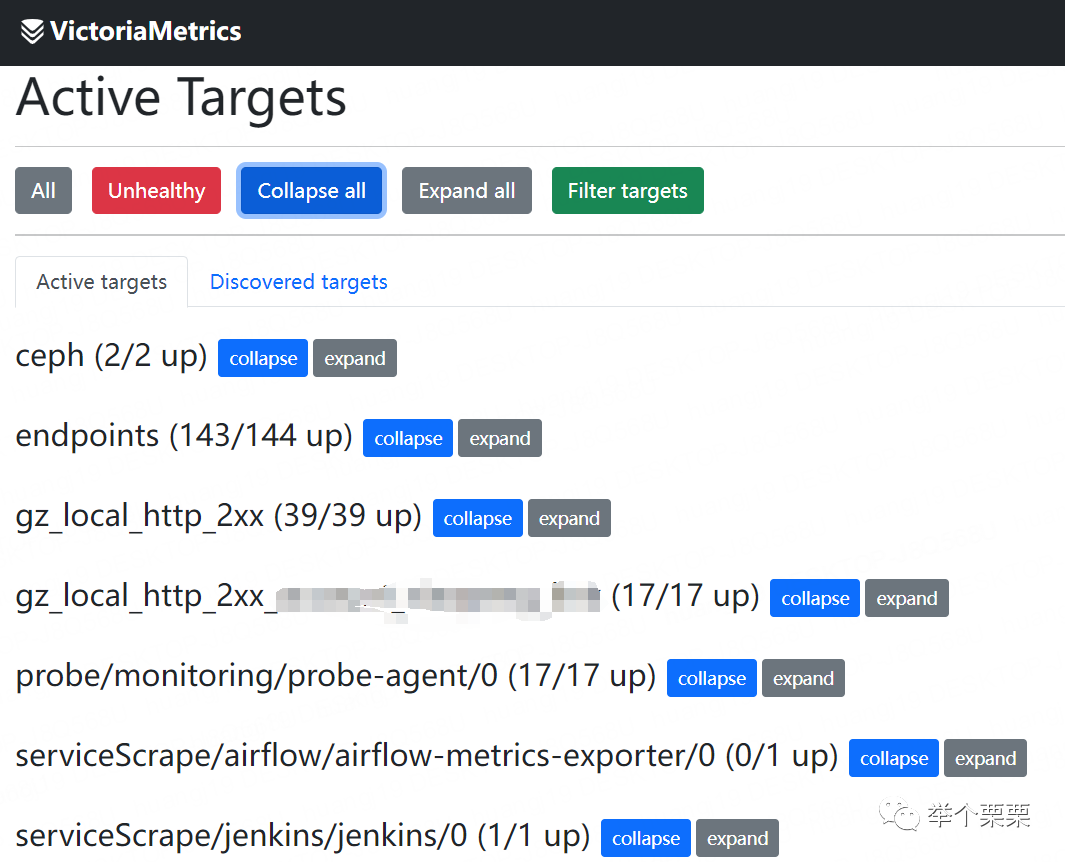
4. 安装alertmanager
# cat VMAlertmanagerSecrets.yamlapiVersion: v1kind: Secretmetadata: name: alertmanager-config namespace: monitoringstringData: alertmanager.yaml: | global: # resolve_timeout: 5m
route: group_by: ['alertname'] group_wait: 20s group_interval: 5m repeat_interval: 6h # A default receiver receiver: 'adc_sre_alert' # The child route trees routes: - receiver: 'p0-alertgroup.webhook' match_re: vmalertgroup: "^(sre)-.*" level: P0 continue: true
- receiver: 'p1-alertgroup.webhook' match_re: vmalertgroup: "^(sre)-.*" level: P1 continue: true
receivers: - name: 'sre-p0-alertgroup.webhook' webhook_configs: - url: 'http://vmalert-center.monitoring.svc.cluster.local:8080/prometheusalert?type=fs&tpl=vm-alert-tmpl&fsurl=https://open.feishu.cn/open-apis/bot/v2/hook/xxxxxxx' send_resolved: true
- name: 'sre-p1-alertgroup.webhook' webhook_configs: - url: 'http://vmalert-center.monitoring.svc.cluster.local:8080/prometheusalert?type=fs&tpl=vm-alert-tmpl&fsurl=https://open.feishu.cn/open-apis/bot/v2/hook/xxxxxxx' send_resolved: true
- name: 'adc_sre_alert' webhook_configs: - url: 'http://vmalert-center.monitoring.svc.cluster.local:8080/prometheusalert?type=fs&tpl=feishu-linux-alert&fsurl=https://open.feishu.cn/open-apis/bot/v2/hook/xxxxxxx'
# cat VMAlertmanager.yamlapiVersion: operator.victoriametrics.com/v1beta1kind: VMAlertmanagermetadata: name: alertmanager namespace: monitoringspec: configSecret: alertmanager-config replicaCount: 1 containers: - args: - --config.file=/etc/alertmanager/config/alertmanager.yaml - --storage.path=/alertmanager/data - --web.listen-address=:9093 - --web.external-url=http://alertmanager.xxxxxx.com - --log.level=debug image: prom/alertmanager:v0.24.0 imagePullPolicy: IfNotPresent name: alertmanager resources: limits: cpu: "2" memory: 2G requests: cpu: 500m memory: 500M volumeMounts: - mountPath: /etc/localtime name: tz-config dnsPolicy: ClusterFirst volumes: - hostPath: path: /usr/share/zoneinfo/Asia/Shanghai type: "" name: tz-config storage: volumeClaimTemplate: spec: storageClassName: alicloud-nas-vm-monitoring accessModes: - ReadWriteOnce resources: requests: storage: 10G5. 部署vmproxy查询工具:
# cat vm-promxy.yaml apiVersion: v1kind: ConfigMapmetadata: name: promxy-config namespace: monitoringdata: config.yaml: | promxy: server_groups: - static_configs: - targets: [vmselect-vmcluster:8481] path_prefix: /select/0/prometheus remote_read: false anti_affinity: 10s query_params: nocache: 1 ignore_error: false http_client: tls_config: insecure_skip_verify: true---apiVersion: apps/v1kind: Deploymentmetadata: name: promxy namespace: monitoringspec: selector: matchLabels: app: promxy template: metadata: labels: app: promxy spec: containers: - args: - "--config=/etc/promxy/config.yaml" - "--web.enable-lifecycle" - "--log-level=trace" env: - name: ROLE value: "1" command: - "/bin/promxy" image: quay.io/jacksontj/promxy:v0.0.78 imagePullPolicy: Always name: promxy ports: - containerPort: 8082 name: web volumeMounts: - mountPath: "/etc/promxy/" name: promxy-config readOnly: true - args: # container to reload configs on configmap change - "--volume-dir=/etc/promxy" - "--webhook-url=http://localhost:8082/-/reload" image: jimmidyson/configmap-reload:v0.1 name: promxy-server-configmap-reload volumeMounts: - mountPath: "/etc/promxy/" name: promxy-config readOnly: true volumes: - configMap: name: promxy-config name: promxy-config---apiVersion: v1kind: Servicemetadata: name: promxy namespace: monitoringspec: type: ClusterIP ports: - port: 8082 selector: app: promxypromxy的查询页面和prometheus,thanos-query没有什么区别。显示都是prometheus。
这样,整套VM集群就部署好了:
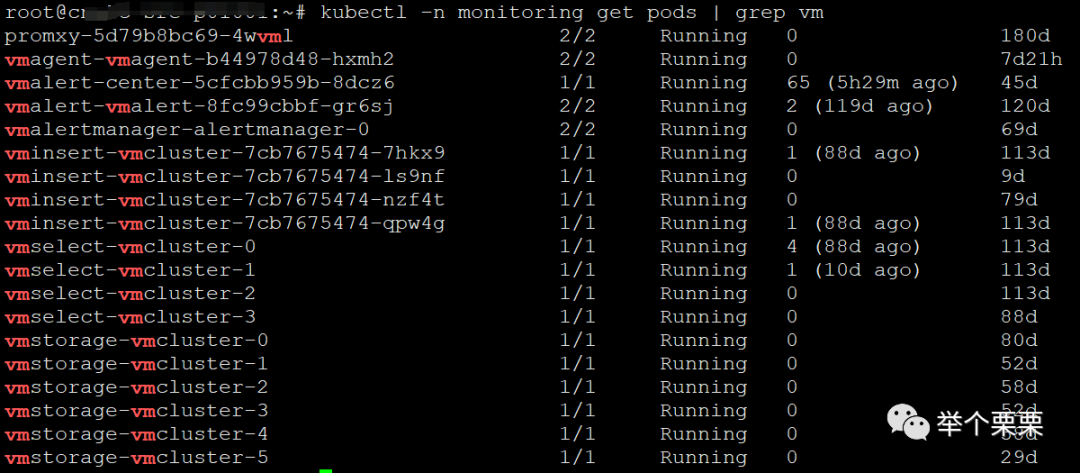
需要说明一下的是,vm-cluster和vmagent中的extraArgs和remoteWriteSettings参数调优参数,按需调优。一般部署好采集遇到问题基本上调整这几个参数都可以解决了。具体含义参考官网文档即可。也可以默认使用我这里设置的参数。
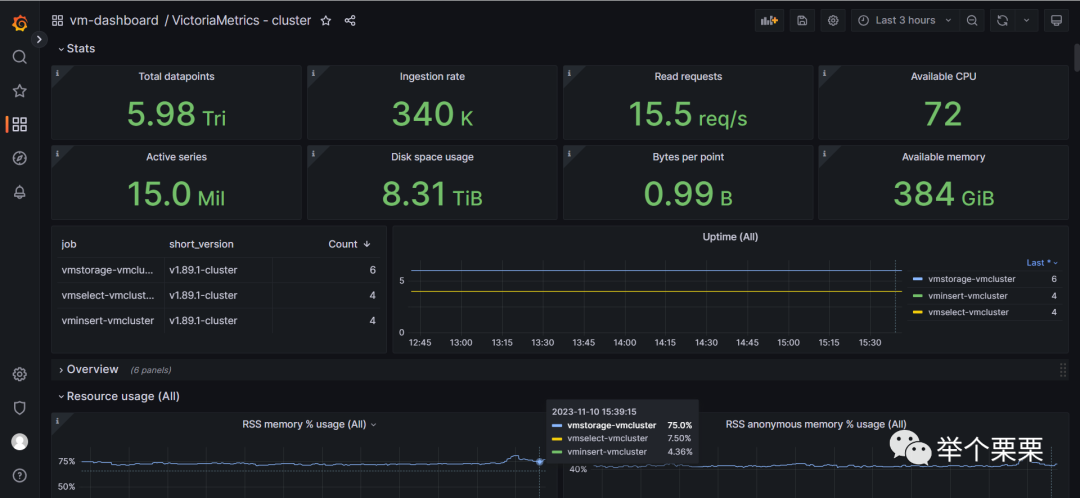
最后附上一个我们目前集群的监控状态:
声明:文中观点不代表本站立场。本文传送门:https://eyangzhen.com/373415.html



