
1.6 深度学习不仅适用于图像分类
近年来,深度学习在图像分类方面的有效性已被广泛讨论,甚至在识别CT扫描中的恶性肿瘤等复杂任务上取得了超人的成果。但深度学习的功能远不止于此,我们将在此一一展示。
例如,我们来谈谈对自动驾驶汽车至关重要的一点:定位中的物体。如果自动驾驶汽车不知道行人在哪里,那么它就不知道如何避开行人!创建一个能够识别图像中每个像素内容的模型叫做分割。以下是我们如何使用 fastai 训练分割模型,使用的是视频中的语义对象类别论文中的 CamVid 数据集子集: A High-Definition Ground Truth Database(高清地面实况数据库)”:
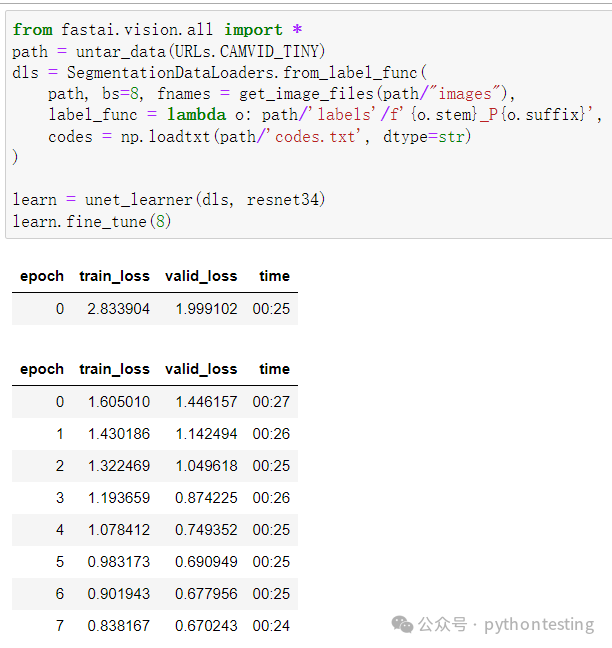

我们甚至不打算逐行查看这段代码,因为它与我们之前的示例几乎完全相同!(我们将在第15章深入探讨分割模型,以及本章简要介绍的所有其他模型,还有更多其他模型)。
我们可以通过让模型对图像的每个像素进行颜色编码来直观地了解它完成任务的情况。正如您所看到的,它几乎完美地对每个物体的每个像素进行了分类。例如,请注意所有的汽车都叠加了相同的颜色,而所有的树木都叠加了相同的颜色(在每对图像中,左边的图像是地面实况标签,右边的图像是模型的预测结果):
learn.show_results(max_n=6, figsize=(7,8))
自然语言处理(NLP natural language processing)是深度学习在过去几年中取得巨大进步的另一个领域。计算机现在可以生成文本、自动从一种语言翻译成另一种语言、分析评论、标注句子中的单词等等。以下是训练一个模型所需的全部代码,该模型能比五年前的任何模型更好地对电影评论进行情感分类:
该模型使用的是安德鲁-马斯等人(Andrew Maas et al)所著的《情感分析中的单词向量学习》(Learning Word Vectors for Sentiment Analysis)中的 IMDb Large Movie Review 数据集:
from fastai.text.all import *
dls = TextDataLoaders.from_folder(untar_data(URLs.IMDB), valid=’test’)
learn = text_classifier_learner(dls, AWD_LSTM, drop_mult=0.5, metrics=accuracy)
learn.fine_tune(4, 1e-2)
learn.predict(“I really liked that movie!”)
执行结果 (‘pos’, tensor(1), tensor([0.0041, 0.9959]))
在这里,我们可以看到模型认为评论是正面的。结果的第二部分是”pos”在数据词汇表中的索引,最后一部分是归属于每个类别的概率(”pos”为 99.6%,”neg “为 0.4%)。
现在轮到你了!写一篇你自己的迷你影评,或者从网上复制一篇,然后你就可以看到这个模型是怎么想的了。
在命令模式下,键入两次 “0 “将重启内核(为笔记本提供动力的引擎)。这将清除你的状态,让你的笔记本就像刚刚开始使用一样。从单元格菜单中选择 “运行上方所有单元格”,运行你所在位置上方的所有单元格。我们发现这在开发 fastai 库时非常有用。
如果你对 fastai 方法有任何疑问,应使用 doc 函数,并将方法名称传给它:
doc(learn.predict)
这时会弹出一个窗口,里面有一行简短的解释。点击 “在文档中显示 “链接,你将看到完整的文档,其中包含所有细节和大量示例。此外,fastai 的大多数方法都只有寥寥几行,因此你可以点击 “源代码 “链接,查看幕后的具体操作。
下面我们来看看不那么性感,但在商业上可能更有用的东西:从简单的表格数据建立模型。
事实证明,这看起来也非常相似。下面是训练一个模型所需的代码,该模型将根据一个人的社会经济背景来预测他是否是高收入者:
from fastai.tabular.all import *
path = untar_data(URLs.ADULT_SAMPLE)
dls = TabularDataLoaders.from_csv(path/’adult.csv’, path=path, y_names=”salary”,
cat_names = [‘workclass’, ‘education’, ‘marital-status’, ‘occupation’,
‘relationship’, ‘race’],
cont_names = [‘age’, ‘fnlwgt’, ‘education-num’],
procs = [Categorify, FillMissing, Normalize])
learn = tabular_learner(dls, metrics=accuracy)
如您所见,我们必须告诉 fastai 哪些列是分类列(包含离散选择集之一的值,如职业),哪些列是连续列(包含代表数量的数字,如年龄)。
这个任务没有预训练模型可用(一般来说,预训练模型并不广泛用于任何表格建模任务,尽管有些组织已经创建了预训练模型供内部使用),因此我们在这种情况下不使用 fine_tune。相反,我们使用 fit_one_cycle,这是最常用的从头开始训练 fastai 模型的方法(即不使用迁移学习):
该模型使用的是罗恩-科哈维(Ron Kohavi)撰写的论文《提高奈维-贝叶斯分类器的准确性:决策树混合》(Scaling Up the Accuracy of Naive-Bayes Classifiers: a Decision-Tree Hybrid)中的成人数据集,其中包含一些有关个人的人口统计数据(如教育程度、婚姻状况、种族、性别以及年收入是否超过 5 万美元)。该模型的准确率超过 80%,训练时间约为 30 秒。
让我们再看一个。推荐系统非常重要,尤其是在电子商务领域。亚马逊和 Netflix 等公司都在努力向用户推荐他们可能喜欢的产品或电影。下面是如何使用 MovieLens 数据集训练一个模型,根据用户以前的观看习惯预测他们可能喜欢的电影:
from fastai.collab import *
path = untar_data(URLs.ML_SAMPLE)
dls = CollabDataLoaders.from_csv(path/’ratings.csv’)
learn = collab_learner(dls, y_range=(0.5,5.5))
learn.fine_tune(10)
这个模型预测的电影评分从 0.5 到 5.0,平均误差在 0.6 左右。由于我们预测的是一个连续的数字,而不是一个类别,因此我们必须使用 y_range 参数告诉 fastai 目标值的范围。
虽然我们实际上并没有使用预训练模型(原因与我们没有使用表格模型相同),但这个例子表明,在这种情况下,fastai 还是允许我们使用 fine_tune(你将在第 5 章中了解它的工作原理和原因)。有时,最好尝试使用 fine_tune 和 fit_one_cycle,看看哪种方法最适合你的数据集。
我们可以使用之前看到的 show_results 调用来查看用户和电影 ID、实际评分和预测的一些示例:
为我们创建数据集以训练模型的人就是我们的英雄(往往不被重视)。一些最有用、最重要的数据集成为重要的学术基线–研究人员广泛研究并用于比较算法变化的数据集。其中有些数据集已经家喻户晓(至少在训练模型的家庭中是这样!),如 MNIST、CIFAR-10 和 ImageNet。
本书中使用的数据集之所以被选中,是因为它们提供了您可能会遇到的各类数据的绝佳示例,而且学术文献中也有很多使用这些数据集的模型结果示例,您可以将自己的工作与之进行比较。
本书中使用的大多数数据集都是创建者花费了大量心血才建立起来的。例如,在本书的后面部分,我们将向您展示如何创建一个可以在法语和英语之间进行翻译的模型。其中的关键输入是宾夕法尼亚大学的克里斯-卡利森-伯奇(Chris Callison-Burch)教授于 2009 年编写的法英平行文本语料库。该数据集包含 2000 多万个法语和英语句子对。他以一种非常巧妙的方式建立了这个数据集:通过抓取数百万个加拿大网页(这些网页通常使用多种语言),然后使用一套简单的启发式方法将法语内容的 URL 转换为指向相同英语内容的 URL。
在阅读本书中的数据集时,请思考这些数据集可能来自哪里,又是如何被整理出来的。然后想想你可以为自己的项目创建哪些有趣的数据集。(我们甚至很快就会带你一步步完成创建自己的图像数据集的过程)。
fast.ai 花费了大量时间创建流行数据集的缩小版本,这些数据集专门用于支持快速原型设计和实验,并且更易于学习。在本书中,我们通常会先使用其中一个缩减版,然后再扩展到完整版(就像我们在本章中所做的!)。这就是世界顶级从业者的建模实践;他们使用数据子集进行大部分实验和原型设计,只有在充分了解他们需要做什么时才使用完整数据集。
我们训练的每个模型都显示了训练和验证损失。一个好的验证集是训练过程中最重要的部分之一。让我们来了解一下原因,并学习如何创建一个验证集。
参考资料
软件测试精品书籍文档下载持续更新 https://github.com/china-testing/python-testing-examples 请点赞,谢谢!
本文涉及的python测试开发库 谢谢点赞! https://github.com/china-testing/python_cn_resouce
python精品书籍下载 https://github.com/china-testing/python_cn_resouce/blob/main/python_good_books.md
Linux精品书籍下载 https://www.cnblogs.com/testing-/p/17438558.html
1.7验证集和测试集
正如我们已经讨论过的,模型的目标是对数据进行预测。但模型的训练过程从根本上说是愚蠢的。如果我们用所有数据训练一个模型,然后再用同样的数据对模型进行评估,我们就无法知道模型在未见过的数据上的表现如何。如果没有这个非常有价值的信息来指导我们训练模型,那么模型很有可能会变得擅长对这些数据进行预测,但在新数据上却表现不佳。
为了避免这种情况,我们的第一步是将数据集分成两组:训练集(模型在训练中使用)和验证集,也称为开发集(仅用于评估)。这样,我们就可以测试模型从训练数据中学到的经验是否能推广到新数据,即验证数据。
理解这种情况的一种方法是,从某种意义上说,我们不希望我们的模型通过 “作弊 “获得好结果。如果模型对某个数据项做出了准确的预测,那应该是因为它掌握了该数据项的特征,而不是因为模型是通过实际查看该特定数据项而形成的。
将验证数据拆分开来,意味着我们的模型在训练中从未见过该数据,因此完全不受其影响,这绝不是作弊。对不对?
其实未必。情况更为微妙。这是因为在现实场景中,我们很少通过训练一次参数就能建立一个模型。相反,我们可能会通过对网络架构、学习率、数据增强策略以及我们将在后续章节中讨论的其他因素的各种建模选择,探索一个模型的多个版本。其中很多选择都可以被称为超参数选择。这个词反映了它们是关于参数的参数,因为它们是支配权重参数含义的更高层次的选择。
问题在于,尽管普通训练过程在学习权重参数值时只关注训练数据的预测结果,但我们的情况并非如此。我们作为建模者,在决定探索新的超参数值时,是通过观察验证数据的预测值来评估模型的!因此,模型的后续版本是通过我们查看验证数据间接形成的。正如自动训练过程有可能过度拟合训练数据一样,我们也有可能通过人为试错和探索过度拟合验证数据。
解决这一难题的办法是引入另一个层次的高度保留数据:测试集。正如我们在训练过程中保留验证数据一样,我们甚至必须对自己保留测试集数据。测试集数据不能用来改进模型,而只能在我们工作的最后阶段用来评估模型。实际上,根据我们希望将数据从训练和建模过程中完全隐藏起来的程度,我们对数据的切割进行了分级:训练数据完全暴露,验证数据暴露较少,而测试数据则完全隐藏。这种层次结构与不同类型的建模和评估过程本身相似–使用反向传播的自动训练过程、在训练过程中尝试不同超参数的手动过程,以及对最终结果的评估。
测试集和验证集应该有足够多的数据,以确保您能很好地估计准确率。例如,如果您要创建一个猫咪检测器,您通常希望验证集中至少有 30 只猫咪。这意味着,如果你的数据集有数千个条目,使用默认的 20% 验证集大小可能会超出你的需要。另一方面,如果你有大量数据,使用其中一些数据进行验证可能不会有任何坏处。
拥有两层 “保留数据”–验证集和测试集,其中一层代表您实际上对自己隐藏的数据–可能看起来有点极端。但这往往是必要的,因为模型往往倾向于用最简单的方法(记忆)来做好预测,而我们作为容易犯错的人,往往倾向于自欺欺人,不知道我们的模型表现如何。测试集的约束有助于我们在智力上保持诚实。这并不意味着我们总是需要一个单独的测试集–如果你的数据很少,你可能只需要一个验证集,但一般来说,如果可能的话,最好使用一个测试集。
如果您打算聘请第三方代表您执行建模工作,那么同样的纪律也是至关重要的。第三方可能无法准确理解您的要求,或者他们的激励机制甚至会促使他们误解您的要求。一个好的测试集可以大大降低这些风险,并让您评估他们的工作是否解决了您的实际问题。
直截了当地说,如果您是组织中的高级决策者(或者您正在为高级决策者提供建议),最重要的启示就是:如果您确保自己真正理解测试和验证集是什么,以及它们为什么重要,那么您就能避免我们所见过的组织决定使用人工智能时最大的失败来源。例如,如果您正在考虑引入外部供应商或服务,请确保您持有一些供应商从未见过的测试数据。然后,您可以根据您的测试数据检查他们的模型,使用您根据实际情况选择的指标,并决定什么样的性能水平是足够的。(您最好也亲自尝试一下简单的基线,这样您就能知道一个真正简单的模型能达到什么样的效果。通常情况下,你的简单模型与外部 “专家 “的模型性能一样好!)。
1.7.1使用判断力定义测试集
为了很好地定义验证集(也可能是测试集),有时您需要做的不仅仅是随机抓取原始数据集的一部分。请记住:验证集和测试集的一个关键特性是,它们必须能够代表您将来会看到的新数据。这听起来像是不可能完成的任务!顾名思义,你还没见过这些数据。但你通常还是知道一些事情的。
看几个案例很有启发。其中许多案例来自 Kaggle 平台上的预测建模竞赛,很好地体现了您在实践中可能会遇到的问题和方法。
其中一个案例可能是你正在研究时间序列数据。对于时间序列来说,选择一个随机的数据子集太容易了(您可以查看您要预测的日期之前和之后的数据),而且不能代表大多数业务用例(您要使用历史数据建立一个模型供未来使用)。如果您的数据包含日期,并且您正在构建一个未来使用的模型,那么您需要选择一个包含最新日期的连续部分作为验证集(例如,最近两周或上个月的可用数据)。
假设您想将下图中的时间序列数据分成训练集和验证集。
下图的随机子集是一个糟糕的选择(太容易填补空白,而且不能反映生产中的需求)。
取而代之的是,使用早期数据作为训练集(后期数据作为验证集)。
例如,Kaggle 举办了一场预测厄瓜多尔连锁杂货店销售额的竞赛。Kaggle 的训练数据从 2013 年 1 月 1 日到 2017 年 8 月 15 日,测试数据从 2017 年 8 月 16 日到 2017 年 8 月 31 日。这样一来,竞赛组织者就确保了参赛者从其模型的角度出发,对未来的一段时间进行预测。这与量化对冲基金交易员根据过去的数据进行回溯测试,以检查其模型是否能预测未来一段时间的情况类似。
第二种常见情况是,您很容易预料到在生产中进行预测的数据可能与训练模型时使用的数据有质的不同。
在 Kaggle 分心驾驶竞赛中,自变量是驾驶汽车的司机的,因变量是发短信、吃东西或安全地注视前方等类别。如图所示,很多都是同一司机在不同位置的表现。如果你是一家保险公司,想利用这些数据建立一个模型,那么请注意,你最感兴趣的是模型在未见过的驾驶员身上的表现(因为你可能只有一小部分人的训练数据)。有鉴于此,比赛的测试数据由训练集中没有出现的人物组成。
如果您将上图中的一张放入训练集,另一张放入验证集,那么您的模型将很容易对验证集中的那张做出预测,因此它似乎比对新人的预测表现更好。另一个角度是,如果您在训练模型时使用了所有的人,那么您的模型可能会过度适应这些特定人的特殊性,而不仅仅是学习他们的状态(发短信、吃饭等)。
在Kaggle渔业竞赛中也有类似的情况,该竞赛的目的是识别渔船捕获的鱼的种类,以减少对濒危鱼种的非法捕捞。测试集包括训练数据中未出现的船只图像,因此在这种情况下,您希望验证集也包括训练集中未出现的船只。
有时,验证数据的差异可能并不明显。例如,对于使用卫星图像的问题,您需要收集更多信息,了解训练集是否只包含特定的地理位置,还是来自地理上分散的数据。
现在,您已经了解了如何构建模型,可以决定下一步要研究什么了。
1.8选择自己的冒险时刻
如果你想进一步了解如何在实践中使用深度学习模型,包括如何识别和修复错误、创建一个真正可用的网络应用程序,以及避免你的模型对你的组织或社会造成意想不到的伤害,那么请继续阅读接下来的两章。如果你想开始学习深度学习的基础知识,请跳至第 4 章。(你小时候读过《选择你自己的冒险》这本书吗?嗯,这有点像……只不过深度学习的内容比那套书要多得多)。
你需要阅读所有这些章节,才能在书中取得进一步的进展,但阅读顺序完全取决于你自己。它们并不相互依赖。如果你跳读到第 4 章,我们会在最后提醒你在继续学习之前,回来阅读你跳过的章节。
声明:文中观点不代表本站立场。本文传送门:https://eyangzhen.com/416819.html
