
2 进程管理
在本章中,我们将强调专门用于进程控制和资源访问管理的基本操作系统机制。 我们也将利用这个机会向您展示如何使用一些C++功能。
一旦我们将程序及其相应的进程作为系统实体进行研究,我们将讨论进程在其生命周期中经历的状态。您将学习如何生成新的进程和线程。您还将看到此类活动的根本问题。稍后我们将在看一些示例的同时慢慢介绍多线程代码。通过这样做,您将有机会学习一些与异步执行相关的POSIX 和C++技术的基础知识。
无论您的C++经验如何,本章都将帮助您了解在系统级别可能最终陷入的一些陷阱。您可以利用您对各种语言功能的了解来增强执行控制和流程可预测性。
在本章中,我们将讨论以下主要主题:
- 进程的本质
- 进程状态和一些调度机制
- 进程创建的更多信息
- C++中线程操作的系统调用
2.1 拆解流程创建
进程是程序的运行实例,包含其各自的元数据、占用的内存、打开的文件等。它是操作系统中的主要作业执行器。 编程的总体目标是将一种类型的数据转换为另一种类型的数据或计数。我们通过编程语言所做的就是向硬件提供指令。通常我们告诉CPU做什么,包括在内存的不同部分移动数据。换句话说计算机必须计算,我们必须告诉它如何计算。这种理解至关重要,并且独立于所使用的编程语言或操作系统。
至此,我们回到了系统编程和理解系统行为的主题。让我们立即声明,进程创建和执行既不简单也不快速。进程切换也不是。它很少通过肉眼观察到,但如果您必须设计一个高度可扩展的系统,或者对系统执行过程中的事件有严格的时间表,那么您迟早需要处理交互分析。同样,这就是计算机的工作原理,当您进行资源优化时,这些知识非常有用。
进程最初只是一个程序,它通常存储在非易失性存储器(NVM)上。根据系统的不同,这可能是硬盘、SSD、ROM、EEPROM、闪存等。 我们提到这些设备是因为它们具有不同的物理特性,例如速度、存储空间、写访问和碎片。 对于系统的耐用性来说,每因素都是重要因素,但在本章中,我们主要关心的是速度。
程序就像所有其他操作系统资源一样,是一个文件。 C++程序是一个可执行目标文件,其中包含必须提供给 CPU 的代码(例如指令)。 该文件是编译的结果。 编译器是另一个将C++代码转换为机器指令的程序。了解我们的系统支持哪些指令至关重要。操作系统和编译器是集成标准、库、语言功能等的先决条件,编译后的目标文件很可能不会在与我们的系统不完全匹配的另一个系统上运行。 此外,在另一个系统上或通过另一个编译器编译的相同代码很可能具有不同的可执行目标文件大小。 大小越大,将程序从 NVM 加载到主存(使用最多的是随机存取存储器(RAM)的时间就越长。 为了分析代码的速度并针对给定系统尽可能地优化它,我们将查看一个关于我们的数据或输入的完整路径的通用图。
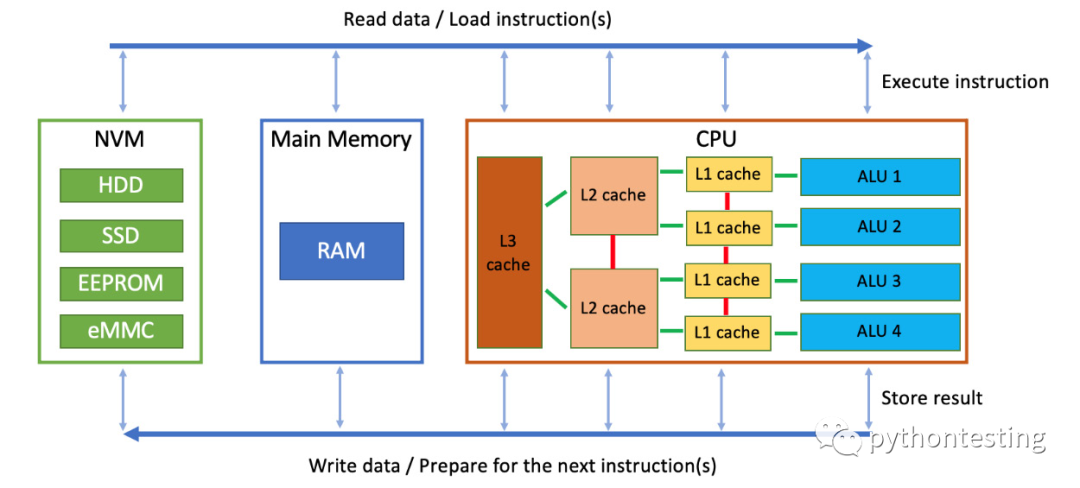

此处提供了通用的CPU概述,因为不同的架构将具有不同的布局。L1和L2缓存是静态RAM (SRAM) 元件,因此速度极快,但价格昂贵。 因此,我们必须保持它们很小。我们还保持它们很小,以实现较小的CPU延迟。二级缓存具有更大的容量,可以在算术逻辑单元 (ALU) 之间创建共享空间 – 一个常见的例子是单个内核中的两个硬件线程,其中二级缓存扮演共享内存的角色。L3缓存并不总是存在,但它通常基于动态RAM (DRAM)元素。 它比L1和L2缓存慢,但允许CPU多一级缓存,只是为了加速目的。 一个例子是指示CPU猜测并从RAM预取数据,从而节省RAM到CPU负载的时间。 现代C++功能可以大量使用这种机制,从而显着加快进程执行速度。
此外,根据其角色,可以识别三种类型的高速缓存:指令高速缓存、数据高速缓存和转换后备缓冲区 (TLB Translation Lookaside Buffer)。 前两个是不言自明的,而TLB与CPU缓存没有直接关系——它是一个单独的单元。 它用于数据和指令的地址,但它的作用是加速虚拟到物理地址的转换,我们将在本章后面讨论。
RAM是经常使用的,并且主要涉及双倍数据速率同步动态RAM(DDR SDRAM)存储器电路。这是非常重要的一点,因为不同的DDR总线配置具有不同的速度。而且无论速度如何,它仍然不如CPU内部传输快。即使CPU负载100%,DDR也很少得到充分利用,从而成为我们的第一个重大瓶颈。正如第一章中提到的NVM比DDR慢得多,这是它的第二个重要瓶颈。 我们鼓励您分析您的系统并查看速度差异。
程序的大小很重要。 优化执行程序指令或加载数据的事件序列的过程是一个永久且持续的平衡行为。 在考虑代码优化之前,您必须了解系统的硬件和操作系统!
如果我们有个程序可以在某个屏幕上可视化某些数据,那么对于台式电脑用户来说,如果它在1秒或10秒后出现,这可能不是问题。 但如果这是飞机上的飞行员,那么在严格的时间窗口内显示数据就是一项安全合规功能。
2.1.1 内存段
内存段也称为内存布局或内存部分。 这些只是内存区域,不应被误认为是分段内存架构。 一些专家更喜欢在讨论编译时操作和运行时布局时使用部分。 选择你喜欢的任何内容,只要它描述的是同一件事。 主要的段是文本(或代码)、数据、BSS、堆栈和堆,其中BSS代表由符号开始的块或块起始符号。 让我们仔细看看:
- 文本:这是将在机器上执行的代码。 它是在编译时创建的。 当它到达运行时时,它是进程的只读部分。 当前的机器指令可以在那里找到,并且根据编译器的不同,您也可以在那里找到const变量。
- 数据:该段也在编译时创建,由初始化的全局数据、静态数据或全局数据和静态数据组成。 当您不想依赖运行时分配时,它用于初步分配的存储。
- BSS:与数据段相反,BSS不在目标文件中分配空间 – 它仅在程序进入运行时标记所需的存储空间。 它由未初始化的全局数据、静态数据或全局数据和静态数据组成。该段是在编译时创建的。 理论上,根据语言标准,其数据被视为初始化为0,但实际上在进程启动期间由操作系统的程序加载器设置为0。
- 堆栈:程序堆栈是代表正在运行的程序例程的内存段 – 它保存其局部变量并跟踪被调用函数返回时从何处继续。 它在运行时构建并遵循后进先出 (LIFO) 策略。 我们希望保持它小而快。
- 堆:这是另一个运行时创建的段,用于动态内存分配。 对于许多嵌入式系统来说,它被认为是禁止的,但我们将在本书后面进一步探讨它。 有有趣的课程需要学习,并且并不总是可以避免它。
上图中,您可以观察到两个进程正在运行相同的可执行文件并在运行时加载到主内存。 我们可以看到,对于Linux,文本段仅复制一次,因为两个进程的文本段应该是相同的。 堆丢失了,因为我们现在不关注它。 正如你所看到的,堆栈并不是无穷无尽的。 当然,它的大小取决于许多因素,但我们猜测您在实践中已经见过几次堆栈溢出消息。 这是一个令人不愉快的运行时事件,因为程序流程被不礼貌地破坏,并且有可能在系统级别引起问题:
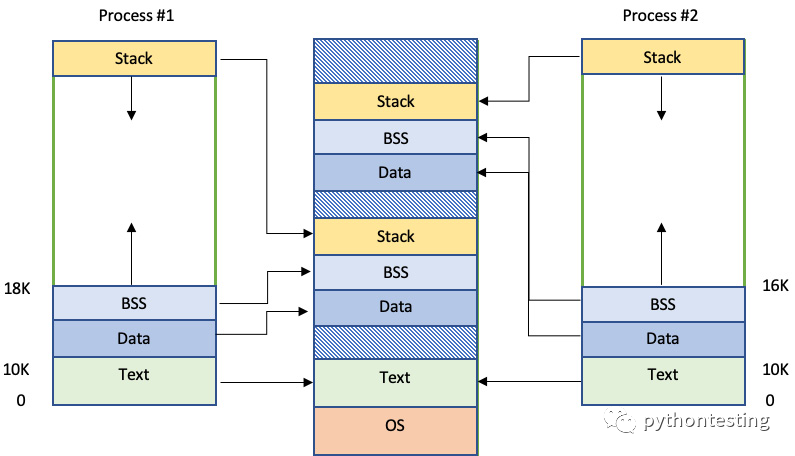
上图顶部的主内存代表虚拟地址空间,操作系统在其中使用称为页表的数据结构将进程的内存布局映射到物理内存地址。 它是概括操作系统管理内存资源方式的一项重要技术。 这样,我们就不必考虑设备的具体特征或接口。 从抽象的层面来看,这很像我们在第1章中访问文件的方式。我们将在本章后面回到这个讨论。
我们使用下面的代码示例来进行分析:
void test_func(){}
int main(){
test_func(); return 0;
}这是一个非常简单的程序,在入口点之后立即调用一个函数。 这里没有什么特别的。 让我们在不进行任何优化的情况下为C++20编译它:
$ g++ mem_layout_example.cpp -std=c++2a -O0 -o test生成的二进制对象称为test。 我们通过size命令来分析一下:
$ size test
text data bss dec hex filename
2040 640 8 2688 a80 test总体大小为2,688字节,其中2,040字节为指令,640字节为数据,8字节为BSS。 正如您所看到的,我们没有任何全局或静态数据,但是648字节仍然存在。 编译器仍在执行其工作,因此那里有一些分配的符号,我们可以在需要时进一步分析:
$ readelf -s test
Symbol table '.dynsym' contains 6 entries:
Num: Value Size Type Bind Vis Ndx Name
0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND
1: 0000000000000000 0 FUNC GLOBAL DEFAULT UND _[...]@GLIBC_2.34 (2)
2: 0000000000000000 0 NOTYPE WEAK DEFAULT UND _ITM_deregisterT[...]
3: 0000000000000000 0 NOTYPE WEAK DEFAULT UND __gmon_start__
4: 0000000000000000 0 NOTYPE WEAK DEFAULT UND _ITM_registerTMC[...]
5: 0000000000000000 0 FUNC WEAK DEFAULT UND [...]@GLIBC_2.2.5 (3)
Symbol table '.symtab' contains 36 entries:
Num: Value Size Type Bind Vis Ndx Name
0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND
1: 0000000000000000 0 FILE LOCAL DEFAULT ABS Scrt1.o
...编辑代码:
#include <cstdint>
void test_func(){
static uint32_t test_var;
}
int main(){
test_func(); return 0;
}
未初始化的静态变量必定会导致BSS增长:
$ size test
text data bss dec hex filename
2040 640 16 2696 a88 test所以,BSS更大了, 不是4个字节,而是8个字节。让我们仔细检查新变量的大小:
$ nm -S test | grep test_var
0000000000004018 0000000000000004 b _ZZ9test_funcvE8test_var一切都很好 – 正如预期的那样,无符号32位整数占4个字节,但编译器在那里放置了一些额外的符号。 我们还可以看到它位于BSS部分,由符号前面的字母b表示。 现在,我们再次更改代码:
#include <cstdint>
void test_func(){
static uint32_t test_var=10;
}
int main(){
test_func(); return 0;
}
我们已经初始化了变量。 现在,我们期望它位于数据段中:
$ size test
text data bss dec hex filename
2040 644 4 2688 a80 test
$ nm -S test | grep test_var
0000000000004010 0000000000000004 d _ZZ9test_funcvE8test_var正如预期的那样,数据段已经扩大了4个字节,我们的变量就在那里(参见符号前面的字母 d)。 您还可以看到编译器已将BSS使用量缩减至 4个字节,并且总体目标文件大小更小 – 仅2688 个字节。
让我们做最后的改变:
#include <cstdint>
void test_func(){
const static uint32_t test_var=10;
}
int main(){
test_func(); return 0;
}
由于const在程序执行期间无法更改,因此必须将其标记为只读。 为此,可以将其放入文本段中。 请注意,这取决于系统实现。 让我们来看看:
$ size test
text data bss dec hex filename
2044 640 8 2692 a84 test
$ nm -S test | grep test_var
0000000000002004 0000000000000004 r _ZZ9test_funcvE8test_var正确的! 我们可以看到符号前面有字母r,并且文本大小是2044,而不是之前的2040。 编译器再次生成了8字节的 BSS,这看起来很有趣,但我们可以接受它。 如果我们从定义中删除static ,大小会发生什么变化? 我们鼓励您尝试一下。
您可能已经认识到较大的编译时部分通常意味着更大的可执行文件。 更大的可执行文件意味着程序启动的时间更长,因为将数据从NVM复制到主内存比将数据从主内存复制到CPU缓存要慢得多。 当我们稍后讨论上下文切换时,我们将回到这个讨论。 如果我们想保持启动速度快,那么我们应该考虑较小的编译时部分,但较大的运行时部分。这是一种平衡行为,通常由软件架构师或具有良好系统概述和知识的人来完成。 必须考虑NVM读/写速度、DDR配置、系统启动、正常工作和关闭期间的CPU和RAM负载、活动进程数量等先决条件。
我们将在本书后面再次讨论这个主题。 现在,让我们重点关注内存段在新进程创建方面的含义。 它们的含义将在本章后面讨论。
2.2 进程状态和一些调度机制
进程和线程被视为Linux调度程序中的任务。 它们的状态是通用的,它们的理解对于正确的程序规划非常重要。 任务在等待资源时可能必须等待甚至停止。 我们也可以通过同步机制来影响这种行为,例如信号量和互斥体。糟糕的任务状态管理可能会导致不可预测性和整体系统性能下降,这在大型系统中是显而易见的。
现在尝试简化代码的目标——它需要指示 CPU 执行操作并修改数据。 我们的任务是考虑正确的指令是什么,以便我们可以节省重新安排时间或通过阻塞资源什么也不做。 让我们看看我们的流程可能处于哪些状态:
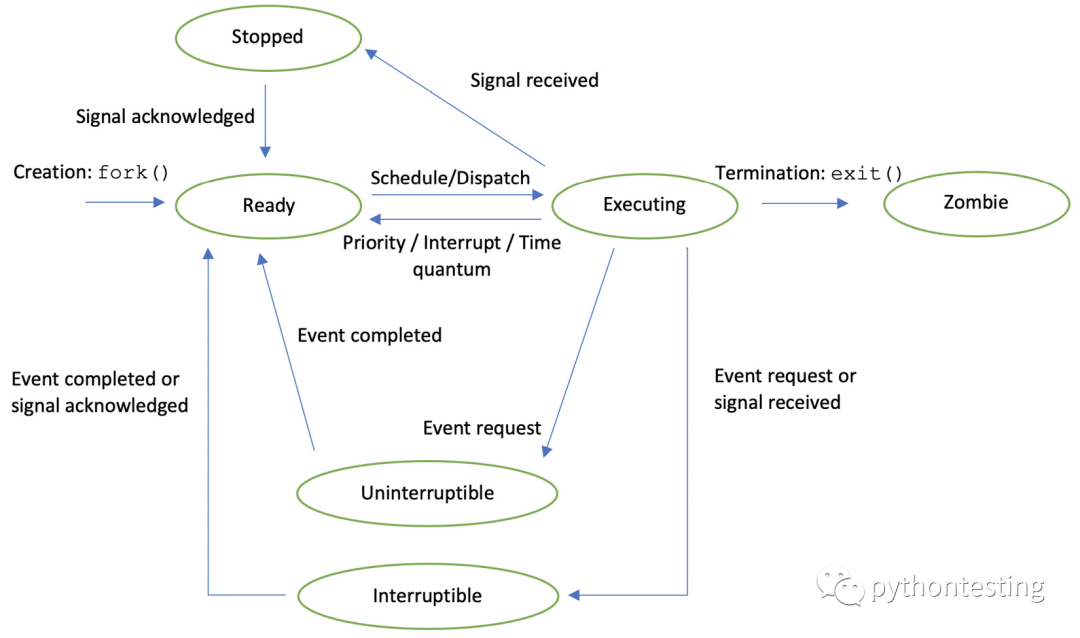
- 执行(R——正在运行和可运行 Running):为进程的指令提供处理器(核心或线程)——任务正在运行。 调度算法可能会强制它执行。 然后,任务变得可运行,并被添加到可运行队列中,等待轮到它们。 两种状态是不同的,但都表示为正在执行的进程。
- 睡眠(D – 不可中断,S – 可中断 Sleep)
- 已停止 (T):您是否曾经使用 Ctrl + Z 来停止进程? 这是将进程置于停止状态的信号,但根据信号请求,它可能会被忽略,并且进程将继续。 或者,可以停止该过程,直到收到再次继续继续的信号为止。
- 僵尸(Z Zombie):我们在第一章中看到了这种状态——进程已终止,但它在操作系统的任务向量中仍然可见。
使用top命令,您将在进程信息列的顶行看到字母S:ps命令的STAT列将为您提供当前状态:
2.2.1 调度机制
现代Linux发行版提供了许多调度机制。 它们的唯一目的是帮助操作系统决定接下来必须以优化的方式执行哪个任务。 应该是优先级最高的那个,还是完成速度最快的那个,还是两者的混合? 还有其他标准,因此不要错误地认为一个标准可以解决您的所有问题。 当处于R状态的进程多于系统上的可用处理器时,调度算法尤其重要。 为了管理此任务,操作系统有调度程序——每个操作系统都以某种形式实现的基本模块。 它通常是一个独立的内核进程,充当负载平衡器,这意味着它使计算机资源保持繁忙并为多个用户提供服务。 它可以配置为以小延迟、公平执行、最大吞吐量或最短等待时间为目标。 在实时操作系统中,它必须保证满足最后期限。 这些因素显然是相互冲突的,调度器必须通过适当的折衷来解决这些问题。 系统程序员可以根据用户的需求配置系统的偏好。 但这是怎么发生的呢?
2.2.2 高层次的调度
我们请求操作系统启动一个程序。 首先,我们必须从NVM加载它。 这调度级别考虑程序加载器的执行。 程序的目的地由操作系统提供给它。 文本和数据段被加载到主存储器中。 大多数现代操作系统将按需加载程序。 这使得进程启动速度更快,并且意味着在给定时刻仅提供当前所需的代码。BSS 数据也在那里分配和初始化。 然后,映射虚拟地址空间。 将创建携带指令的新进程,并初始化所需字段,例如进程 ID、用户 ID、组 ID 等。 程序计数器设置为程序的入口点,并且控制权传递给加载的代码。 由于NVM的硬件限制,这种开销在进程的生命周期中相当重要。 让我们看看程序到达RAM后会发生什么。
2.2.3 低层次的调度
这是试图提供最佳任务执行顺序的技术的集合。 尽管我们在本书中没有过多提及“调度”这个术语,但请确保我们所做的每次操作都会导致任务状态切换,这意味着我们会导致调度程序采取行动。 这样的操作称为上下文切换。 切换也需要时间,因为调度算法可能需要重新排序任务队列,并且必须将新启动的任务指令从 RAM 复制到 CPU 缓存。
多个正在运行的任务,无论是否并行,都可能导致时间花在重新安排而不是过程执行上。 这是另一种取决于系统程序员设计的平衡行为。
以下是基本概述:就绪/阻塞任务队列
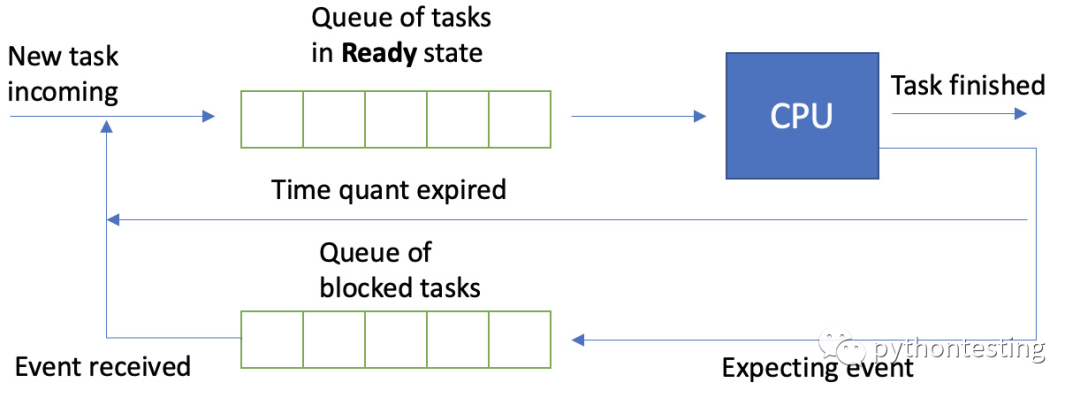
该算法必须从队列中选择一个任务并将其放置以执行。 在系统级别,基本层次结构为(从最高优先级到最低优先级)调度程序 -> 块设备 -> 文件管理 -> 字符设备 -> 用户进程。
根据队列的数据结构实现和调度程序的配置,我们可以执行不同的算法。 这里是其中的一些:
- 先来先服务(FCFS – First-come-first-serve):现在很少使用这种方式,因为较长的任务可能会阻碍系统的性能,并且重要的进程可能永远不会被执行。
- 最短作业优先(SJF Shortest job first):这提供了比 FCFS 更短的等待时间,但可能永远不会调用更长的任务。 它缺乏可预测性。
- 最高优先级优先(HPF Highest priority first):这里,任务具有优先级,最高的任务将被执行。 但是谁来设置优先级值以及谁来决定传入进程是否会导致重新调度? Kleinrock 规则就是这样一种规则,其中优先级线性增加,而任务保留在队列中。 根据运行停留比,执行不同的订单 – FCFS、Last-CFS、SJF 等。 关于此问题的一篇有趣的文章可以在这里找到:https://dl.acm.org/doi/10.1145/322261.322266。
- 循环(Round-robin):这是一种无资源匮乏的抢占式算法,其中每个任务均等地获得一个时间片。 任务按循环顺序执行。 他们每个人都有一个CPU时隙,等于时间片。 当它到期时,任务被推到队列的后面。 正如您可能已经推断出的那样,队列的长度和量子值(通常在 10 到 300 毫秒之间)非常重要。 保持公平性的另一种技术是在现代操作系统调度程序中丰富该算法。
- 完全公平调度(CFS Completely fair scheduling):这是目前Linux的调度机制。 它根据系统状态应用上述算法的组合:
$ chrt -m
SCHED_OTHER min/max priority : 0/0
SCHED_FIFO min/max priority : 1/99
SCHED_RR min/max priority : 1/99
SCHED_BATCH min/max priority : 0/0
SCHED_IDLE min/max priority : 0/0
SCHED_DEADLINE min/max priority : 0/0这种方法很复杂,值得单独写一本书。
我们在这里关心的是以下内容:
- 优先级(Priority):它的值是实际的任务优先级,用于调度。0到99之间的值专用于实时进程,而100到139之间的值用于用户进程。
- Nice:它的值在用户空间级别有意义,并在运行时调整进程的优先级。 root 用户可以将其设置为 -20 到 +19,简单用户可以将其设置为 0 到 +19,其中较高的Nice值意味着较低的优先级。默认值为0。
它们的依赖性是,对于用户进程,优先级=nice+20;对于实时进程,优先级=-1-real_time_priority。 优先级值越高,调度优先级越低。 我们无法更改进程的基本优先级,但我们可以使用不同的好值来启动它。 让我们以新的优先级调用 ps :
$ sudo nice -5 ps
[sudo] password for andrew:
PID TTY TIME CMD
105743 pts/0 00:00:00 sudo
105744 pts/0 00:00:00 ps
# 可以使用renice命令和pid来更改进程运行时的优先级
$ sudo renice -n -10 -p 17063
17063 (process ID) old priority 0, new priority -10
要启动实时进程或设置和检索pid的实时属性,必须使用 chrt 命令。 例如,我们用它来启动一个优先级为99的实时进程:
$ sudo chrt --rr 99 ./test我们鼓励您查看其他算法,例如反馈、自适应分区调度 (APS Adaptive Partition Scheduling)、最短剩余时间 (SRT Shortest Remaining Time) 和下一步最高响应比率 (HRRN Highest Response Ratio Next)。
调度算法的主题很广泛,不仅涉及操作系统任务的执行,还涉及其他领域,例如网络数据管理。 我们无法在这里详细介绍它的全部内容,但重要的是说明如何最初处理它并了解系统的优势。 也就是说,让我们继续看看流程管理。
2.3 了解有关流程创建的更多信息
系统编程的常见做法是遵循严格的流程创建和执行时间表。程序员使用守护进程(例如 systemd 和其他内部开发的解决方案)或启动脚本。 我们也可以使用终端,但这主要是在我们修复系统状态并恢复它或测试给定功能时使用。从我们的代码启动进程的另一种方法是通过系统调用。 您可能知道其中一些,例如 fork() 和 vfork()。
2.3.1 介绍fork()
fork_example.cpp
#include <iostream>
#include <stdlib.h>
#include <unistd.h>
using namespace std;
void process_creator() {
if (fork() == 0) {
cout << "Child process id: " << getpid() << endl;
exit(EXIT_SUCCESS);
}
else {
cout << "Parent process id: " << getpid() << endl;
}
}
int main() {
process_creator();
return 0;
}是的,我们知道您之前可能见过类似的示例,并且很清楚应该给出什么作为输出 – fork() [1] 启动一个新进程,并且打印出两个 pid 值:
$ g++ fork_example.cpp -std=c++2a -O0 -o fork_example
$ ./fork_example
Parent process id: 120297
Child process id: 120298在Parent中,fork()会返回新创建进程的ID; 这样,父母就可以了解其孩子。 在 Child 中,将返回 0。 这种机制对于进程管理很重要,因为 fork() 创建了调用进程的副本。 理论上,编译时段(文本、数据和 BSS)是在主内存中重新创建的。 新的堆栈开始从程序的同一入口点展开,但它在 fork 调用时分支。 然后,父级遵循一条逻辑路径,子级遵循另一条逻辑路径。 每个都使用自己的数据、BSS 和堆。
您可能认为大型编译时段和堆栈会因重复而导致不必要的内存使用,尤其是当我们不更改它们时。 你是对的! 幸运的是,我们使用的是虚拟地址空间。 这允许操作系统对内存进行额外的管理和抽象。 在上一节中,我们讨论了具有相同文本段的进程将共享一个副本,因为它是只读的。 Linux 采用了一项优化,数据和 BSS 将通过其单个实例共享。 如果没有任何进程更新它们,则复制将推迟到第一次写入。 无论是谁执行此操作,都会启动副本创建并使用它。 这种技术称为写时复制。 因此,进程创建的唯一损失是子进程元数据和父进程页表的时间和内存。 不过,请确保您的代码不会无休止地 fork(),因为这会导致所谓的 fork 炸弹,从而导致拒绝系统服务和资源匮乏。
2.3.2 exec and clone()
exec函数调用并不是真正的系统调用,而是一组具有execXX() 模式的系统调用。 每个进程都有特定的角色,但最重要的是,它们通过其文件系统路径(称为路径名)创建一个新进程。 调用者进程的内存段被完全替换并初始化。 让我们为上一节中的 fork 示例调用二进制可执行文件,并将其命令行参数设置为 NULL。 此代码与前面的示例类似,但进行了一些更改:
exec_example.cpp
#include <iostream>
#include <unistd.h>
using namespace std;
void process_creator() {
if (execvp("./fork_example", NULL) == -1)
cout << "Process creation failed!" << endl;
else
cout << "Process called!" << endl;
}
int main() {
process_creator();
return 0;
}结果如下:
$ g++ exec_example.cpp -std=c++2a -O0 -o exec_example
$ ./exec_example
Parent process id: 135283
Child process id: 135284与 exec 类似,clone() 是真正的 clone() 系统调用的包装函数。 它创建一个新进程,例如 fork(),但允许您精确管理新进程的方式
进程被实例化。 一些示例包括虚拟地址空间共享、信号句柄、文件描述符等。 如前所述,vfork() 是clone() 的特殊变体。 我们鼓励您花一些时间看一些示例,尽管我们相信大多数时候 fork() 和 execXX() 就足够了。
如您所见,我们为给定示例选择了 execv() 函数 {1}。我们还可以使用其他函数:execl()、execle()、execip()、execve() 和 execvp()。 遵循 execXX() 模式,我们需要符合给定的要求:
- e 要求函数使用指向系统环境变量的指针数组,这些变量将传递给新创建的进程。
- l 要求将命令行参数存储在临时数组中并将它们传递给函数调用。 这只是为了方便处理数组的大小。
- p 需要将路径的环境变量(在 Unix 中视为 PATH)传递给新加载的进程。
- v 在本书前面使用过——它需要向函数调用提供命令行参数,但它们作为指针数组传递。 在我们的示例中,为了简单起见,我们将其设置为 NULL。
int execl(const char* path, const char* arg, …)
int execlp(const char* file, const char* arg, …)
int execle(const char* path, const char* arg, …, char*
const envp[])
int execv(const char* path, const char* argv[])
int execvp(const char* file, const char* argv[])
int execvpe(const char* file, const char* argv[], char
*const envp[])简而言之,当涉及到我们如何创建新流程时,它们的实现是相同的。 是否使用它们的选择严格取决于您的需求和软件设计。
让我们看一个简单的例子:假设我们有一个通过命令行终端 shell 启动的进程系统命令。
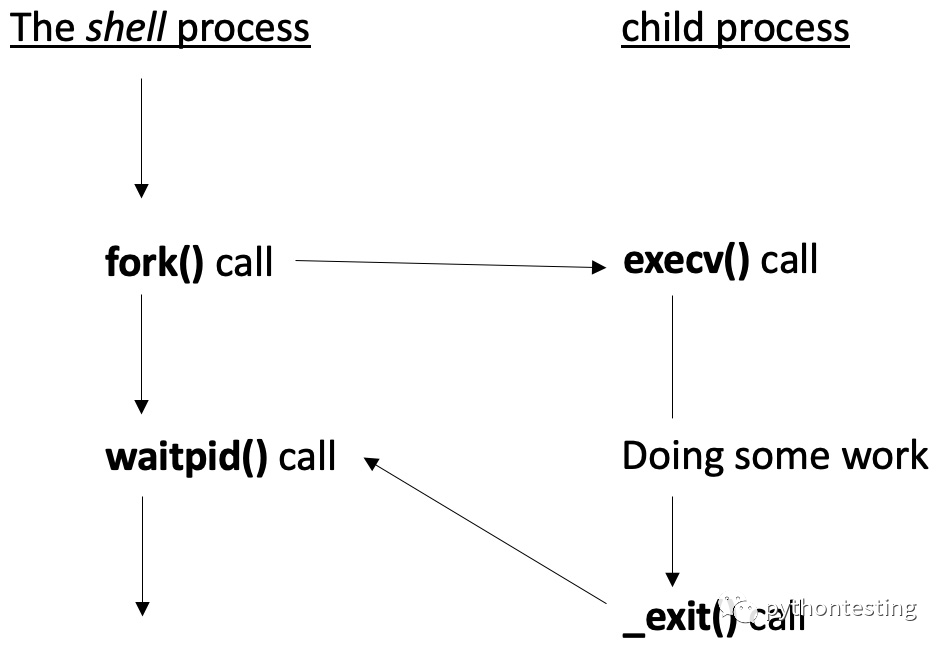
我们用这个图来强调Linux中进程之间父子关系的不可见系统调用。 在后台,shell 向 exec() 提供可执行文件的路径名。 内核取得控制权并转到应用程序的入口点,在该入口点调用 main()。 可执行文件完成其工作,当 main() 返回时,进程结束。 结束例程是特定于实现的,但您可以通过 exit() 和 _exit() 系统调用以受控方式自行触发它。 与此同时,外壳处于等待状态。 现在,我们将介绍如何终止进程。
2.3.3 终止进程
通常,exit() 被视为在 _exit() 之上实现的库函数。 它做了一些额外的工作,例如缓冲区清理和关闭流。 在 main() 中使用 return 可以被认为等同于调用 exit()。 _exit() 将通过释放数据和堆栈段、销毁内核对象(共享内存、信号量等)、关闭文件并通知父进程其状态更改(将触发 SIGCHLD 信号)来处理进程终止。 )。 它们的接口如下:
• void _exit(int status)
• void exit(int status)
abort() 将以类似的方式导致进程终止,但会触发 SIGABRT 信号。
2.3.4 阻塞调用进程
使用 wait()、waitid() 或 waitpid() 系统调用将导致调用进程被阻塞,直到它收到信号或其子进程之一更改其状态:它被终止、被信号停止,或者 它通过信号恢复。 我们使用wait()来指示系统释放与child相关的资源; 否则,它就会变成僵尸,如前一章所述。 这三种方法几乎相同,但后两种方法符合 POSIX,并且可以对受监控的子进程提供更精确的控制。 三个接口如下:
waitpid_example.cpp
#include <iostream>
#include <stdlib.h>
#include <sys/wait.h>
#include <unistd.h>
using namespace std;
void process_creator() {
pid_t pids[2] = {0};
if ((pids[0] = fork()) == 0) {
cout << "Child process id: " << getpid() << endl;
exit(EXIT_SUCCESS);
}
if ((pids[1] = fork()) == 0) {
cout << "Child process id: " << getpid() << endl;
exit(EXIT_FAILURE);
}
int status = 0;
waitpid(pids[0], &status, 0);
if (WIFEXITED(status))
cout << "Child " << pids[0]
<< " terminated with: "
<< status << endl;
waitpid(pids[1], &status, 0);
if (WIFEXITED(status))
cout << "Child " << pids[1]
<< " terminated with: "
<< status << endl;
}
int main() {
process_creator();
return 0;
}这次执行的结果如下:
$ g++ waitpid_example.cpp -std=c++2a -O0 -o waitpid_example
$ ./waitpid_example
Child process id: 149875
Child process id: 149876
Child 149875 terminated with: 0
Child 149876 terminated with: 256
如您所见,我们正在创建两个子进程,并将其中一个设置为成功退出,另一个设置为失败([1] 和 [2])。 我们将父级设置为等待其退出状态([1] 和 [5])。 当子进程退出时,如前所述,通过信号相应地通知父进程,并打印出退出状态([4]和[6])。
另外,idtype和waitid()系统调用使我们不仅可以等待某个进程,还可以等待一组进程。 其状态参数提供有关实际状态更新的详细信息。
waitid() 系统调用有各种选项,通过它,您可以实时监控生成的进程。 参考:https://linux.die.net/man/2/waitid。
重要的一点是,对于我们之前讨论过的 POSIX 和 Linux 的线程管理策略,默认情况下,一个线程将等待同一线程组中其他线程的子线程。 也就是说,我们将在下一节中讨论一些线程管理。
参考资料
- 软件测试精品书籍文档下载持续更新 https://github.com/china-testing/python-testing-examples 请点赞,谢谢!
- 本文涉及的python测试开发库 谢谢点赞! https://github.com/china-testing/python_cn_resouce
- python精品书籍下载 https://github.com/china-testing/python_cn_resouce/blob/main/python_good_books.md
- Linux精品书籍下载 https://www.cnblogs.com/testing-/p/17438558.html
2.4 C++中线程操作的系统调用
我们使用线程来并行执行单独的过程。 它们只存在于进程的范围内,并且它们的创建开销比线程的大,因此我们认为它们是轻量级的,尽管它们有自己的堆栈和task_struct。 它们几乎是自给自足的,只不过它们依赖于父进程而存在。 该过程也称为主线程。 由它创建的所有其他人都需要加入它才能启动。 您可以在系统上同时创建数千个线程,但它们不会并行运行。 您只能运行 n 个并行任务,其中 n 是系统并发 ALU 的数量(有时,这些是硬件的并发线程)。 其他的将根据操作系统的任务调度机制进行调度。 让我们看一下 POSIX 线程接口的最简单的示例:
pthread_t new_thread;
pthread_create(&new_thread, <attributes>,
<procedure to execute>,
<procedure arguments>);
pthread_join(new_thread, NULL);当然,我们还可以使用其他系统调用来进一步管理 POSIX 线程,例如退出线程、接收被调用过程的返回值、从主线程分离等等。 我们看一下C++的线程实现:
std::thread new_thread(<procedure to execute>);
new.join();这看起来更简单,但它提供了与 POSIX 线程相同的操作。 为了与语言保持一致,我们建议您使用C++线程对象。 现在,让我们看看这些任务是如何执行的。
2.4.1 连接和分离线程
无论您是通过 POSIX 系统调用还是 C++ 连接线程,都需要此操作来通过给定线程执行例程并等待其终止。 但需要注意的是,在 Linux 上,pthread_join() 的线程对象必须是可连接的,而 C++ 线程对象默认情况下是不可连接的。 单独连接线程是一个很好的做法,因为同时连接它们会导致未定义的行为。 它的工作方式与 wait() 系统调用相同,只是它涉及线程而不是进程。
与进程可以作为守护进程运行一样,线程也可以通过分离(POSIX 中的 pthread_detach() 或 C++ 中的 thread::detach())成为守护进程。 我们将在下面的示例中看到这一点,但我们还将分析线程的可连接设置:
#include <iostream>
#include <chrono>
#include <thread>
using namespace std;
using namespace std::chrono;
void detached_routine() {
cout << "Starting detached_routine thread.n";
this_thread::sleep_for(seconds(2));
cout << "Exiting detached_routine thread.n";
}
void joined_routine() {
cout << "Starting joined_routine thread.n";
this_thread::sleep_for(seconds(2));
cout << "Exiting joined_routine thread.n";
}
void thread_creator() {
cout << "Starting thread_creator.n";
thread t1(detached_routine);
cout << "Before - Is the detached thread joinable: "
<< t1.joinable() << endl;
t1.detach();
cout << "After - Is the detached thread joinable: "
<< t1.joinable() << endl;
thread t2(joined_routine);
cout << "Before - Is the joined thread joinable: "
<< t2.joinable() << endl;
t2.join();
cout << "After - Is the joined thread joinable: "
<< t2.joinable() << endl;
this_thread::sleep_for(chrono::seconds(1));
cout << "Exiting thread_creator.n";
}
int main() {
thread_creator();
}各自的输出如下:
$ g++ thread_creation_example.cpp -std=c++2a -O0 -o thread_creation_example
$ ./thread_creation_example
Starting thread_creator.
Before - Is the detached thread joinable: 1
After - Is the detached thread joinable: 0
Before - Is the joined thread joinable: 1
Starting joined_routine thread.
Starting detached_routine thread.
Exiting joined_routine thread.
Exiting detached_routine thread.
After - Is the joined thread joinable: 0
Exiting thread_creator.
前面的例子相当简单——我们创建了两个线程对象:一个是从主线程句柄中分离(detached_routine()),而另一个(joined_thread())将在退出后加入主线程。 我们在创建时和设置它们工作后检查它们的可加入状态。 正如预期的那样,线程进入其例程后,在终止之前它们将不再可连接。
2.4.2 线程终止
Linux (POSIX) 提供了两种从线程内部以受控方式结束线程例程的方法:pthread_cancel() 和 pthread_exit()。 正如您可能从它们的名称中猜到的那样,第二个终止调用者线程,并且预计总是成功。 与进程 exit() 系统调用相反,在该系统调用的执行过程中,不会释放进程共享的资源,例如信号量、文件描述符、互斥体等,因此请确保在线程退出之前管理它们。 取消线程是一种更灵活的方法,但最终以 pthread_exit() 结束。 由于线程取消请求被发送到线程对象,因此它有机会执行取消清理并调用线程特定的数据析构函数。
由于 C++ 是系统调用接口之上的抽象,因此它使用线程对象的范围来管理其生命周期,并且做得很好。 当然,无论后面发生什么kground 是特定于实现的并且取决于系统和编译器。 我们还将在本书后面重新讨论这个主题,因此请利用这个机会熟悉这些界面。
2.5 小结
在本章中,我们介绍了进程或线程创建和操作期间发生的低级事件。 我们讨论了进程的内存布局及其意义。 您还了解了有关操作系统任务调度方式以及进程和线程状态更新期间后台发生的情况的一些重要要点。
声明:文中观点不代表本站立场。本文传送门:https://eyangzhen.com/386780.html



