
本篇根据HOW CUDA PROGRAMMING WORKS的讲解,整理下如何更好地使用GPU的一些细节,主要有三点:
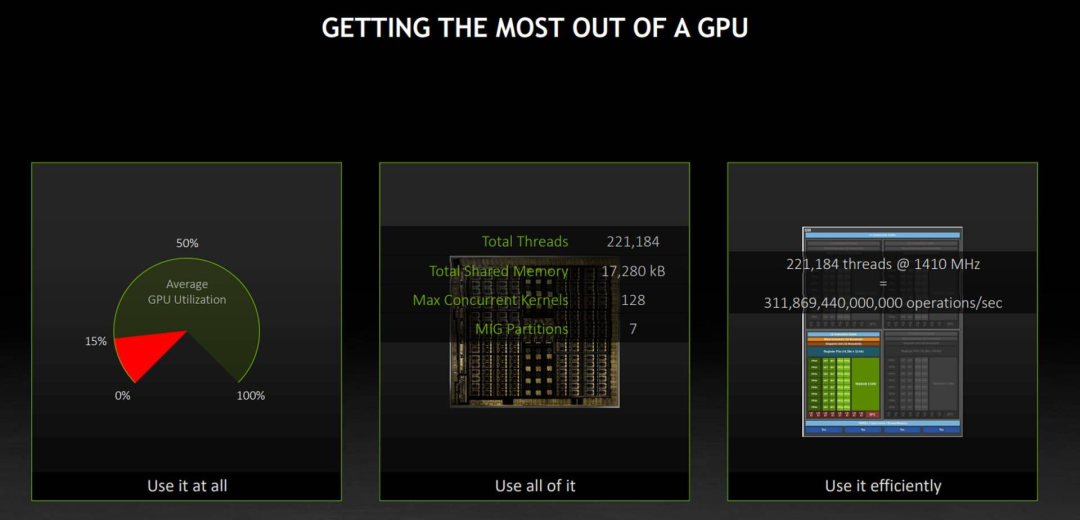
让GPU别闲着(Use it at all)
把GPU中所有资源都利用起来(Use all of it)
高效的利用资源(Use it efficiently)

充分利用GPU资源
在我们平常的项目中,除了优化 kernel 性能,能够快速拿到收益的是整体 pipeline 的优化。
我遇到大部分项目在优化性能的时候,kernel 优化一般都是最后一步,很多项目一开始可以先从整体 pipeline 上考虑,拿到可以拿到的性能收益,最后实在扣不出来再考虑优化 kernel。
让GPU别闲着
首先明确一点,GPU是异步的,一般cpu发完命令后(也就是launch了一个 kernel 之后)就没事了。发kernel指令这一步很快,理论上任务给了gpu之后cpu就能干自己的事儿了。
有异步就会有同步,依赖gpu处理结果的cpu线程需要同步操作来等待当前gpu处理完才能进行下一步,比如处理:
但是上述gpu利用率并不高(看右面的曲线),这里等gpu执行完的时候其实cpu啥也没干,gpu和cpu之前的数据拷贝需要时间,然后gpu处理完了cpu会做一些后续操作,最后才会处理下一个,再加上一些语言层面的 overhead,GPU的利用率就很低了。
其实我们可以把所有的任务一股脑扔给GPU,因为GPU是异步的,cpu把任务传递过去可以通过同步来获取gpu处理完的数据。传递过来的kernel任务会被GPU排入队列一个一个去执行,这个时候GPU的利用率就会高些,毕竟相对没有那么闲了:
这就是最基本的让GPU别闲下来的通用办法,尽量做到:
减少不必要的 CPU-GPU synchronization
在CPU-GPU之间拷贝数据时也可以执行Kernel
很多任务,能通过异步提升性能就尽量异步
将 GPU 中所有资源都利用起来
当我们拿到一张显卡或者说计算卡后,对算力敏感的人一般都会比较计较这个卡的计算资源,比如A100:
A100有108个SM(流处理单元),一共有221184个线程,每个SM都有自己的寄存器、共享显存,共享L2缓存等,我们要做的就是尽可能充分利用这些资源。如果我们某一时刻只用其中一个线程,然后一直调用(kernel一直跑),此时虽然用nvidia-smi命令查出来的GPU utilization是100%,但其实对着张显卡的使用量超级低。
比如这个单block单thread的kernel,理论上只会占用一个SM:
global void simple_kernel() {
while (true) {}
}
int main() {
simple_kernel<<<1, 1>>>();
cudaDeviceSynchronize();
}
但通过nvidia-smi指令得到的GPU Util是100%,这个是要注意的。
GPU如何工作
让我们先快速了解一下Cuda是如何将kernel算法分解成一块一块的,以便将它们分布到这些SM上的。
首先我们把数据分成大小相等的块,这样就可以并行独立地运行每个块。因为这些块是独立的,它们可以按任意顺序和任何时间安排。这样硬件就有尽可能大的自由度来高效地打包事物。每个块的一个保证就是它有一定数量的线程,并且它们都保证在同一个SM上同时运行。
接下来,我们要讨论的是如何使用这些 block 中的线程。每个 block 中有一个特定数量的线程,它们都被分配到同一个 SM 中。SM 中的线程会被分成一定数量的组,这些组被称为 warps。每个 warp 包含特定数量的线程(通常是 32 个),并且这些线程会在同一时钟周期内被执行。这就是为什么我们要使用大量线程的一个原因——保持 GPU 中的所有 SM 和线程都尽可能繁忙。
现在我们回到刚才说的用满。
当一个 SM 上运行的所有 block 都已经满了,就不会再有新的 block 被添加到该 SM 上,直到该 SM 上的线程开始完成它们的工作,空出一些空间。在CUDA中,每个流多处理器(SM)可以同时处理多个块,具体数量取决于块的大小,最多可以处理32个。GPU会持续调度块到各个SM上,直到所有块都被处理完毕。
这就是所谓的“occupancy”,它是一个重要的 GPU 性能指标。
我们先看一下如何编写代码来利用这些 GPU 资源。CUDA 提供了一种编程模型,称为 kernel 函数,它是在 GPU 上执行的代码。这些函数可以通过在主机上调用它们来启动 GPU 上的计算。kernel 函数的一个重要特点是,它可以被调用多次,每次使用不同的数据块。这种方式可以使得 GPU 尽可能高效地利用其并行计算资源。
为了使代码能够在 GPU 上运行,我们需要在主机代码中使用一些特殊的关键字和函数,以便让 CUDA 编译器将其转换为 GPU 可以执行的代码:
注意看相关的硬件资源和代码对应的地方,这个kernel计算多个点之间的距离来展示并行计算。程序中使用了共享内存和寄存器,共享内存允许块内的线程进行通信,而寄存器则为每个线程提供必要的工作空间。在GPU上,寄存器的用途与CPU不同,它们提供了大量立即可访问的数据空间,这对于执行复杂的数学运算尤其重要:
在GPU编程中,为每个线程分配大量寄存器是常见的,这与CPU上的情况有显著不同。首先假设当前写的kernel需要使用的资源如下(下图右侧),每个block是256个线程、每个线程使用64个寄存器,每个block的共享显存是48KB:
然后A100的一个SM的资源如下,我们写的这个kernel可以安排三个block到这个SM上,再多了共享显存不够放了:
如果我们把算法重构一下,减少shared memory的使用,比如从48K→32K,那么就可以塞4个block到这个SM上了,这个时候occupancy也就提升了:
所以为了保持GPU的忙碌状态,我们可以进一步尝试填补空闲时间。实际上,GPU可以同时运行多个程序,最多可以同时运行128个不同的程序。因此,如果我们没有完全填满GPU,就可以尝试将另一个程序“俄罗斯方块”式地放置在旁边。
比如我们想象另一个case,这次是一个大量线程、很少寄存器和没有共享内存的情况。实际上就是一个数据移动kernel的典型表示,可能是对数据进行排序或只是将数据从一个地方复制到另一个地方。
GPU很聪明,它会尝试将一个绿色网格块填充到空隙中,如果不能再放置绿色网格块,那么就会尝试另一个。
现在我们每个SM使用的线程比之前增加了三分之二,这几乎是免费的性能提升。这个“俄罗斯方块”问题又增加了一个维度,但硬件会为你解决这个问题,让内核去帮你处理就行了。
未完待续。
