
:引子
最近看到一个故障,开发人员在处理自研内存数据库(不支持sql)查询优化时引入的。
引入过程如下:
有个场景要求高性能查询区间[start,end)。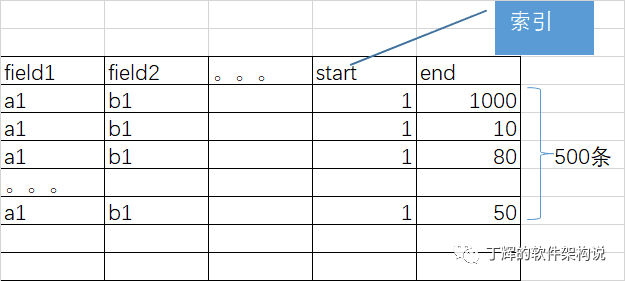

由于该自研内存数据库只支持单索引,应用程序查询时利用start索引返回满足start的所有记录,然后逐条遍历end,过滤出同时满足start和end的记录。 又由于每次返回的最大记录条数(假设10条)有限制,需要应用程序多次查询并对结果比较和汇聚,因此查询性能不足(近似O(n))。
应用团队开发人员为了优化查询速度,设计了一种优化方案,在范围起点字段start上使用索引,范围终点end采取了用空间换时间的方式提升性能: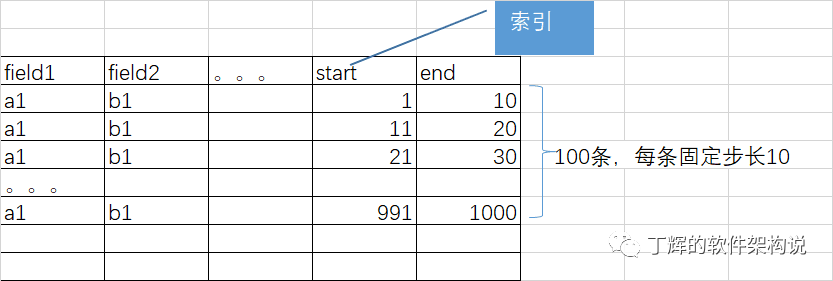
性能优化一般思路:
- 预先计算
- 延迟计算
- 分散计算
- 批量计算
一种或几种方式的组合。
这里通过预先计算+分散计算的方式,增加了end数据条数,并使end数据排序并按固定步长(比如10)连续递增,这样先用索引快速查到起点start,从满足条件的end开始沿着固定步长累加搜索满足条件的最终end。这样通过有限的查询次数(近似O(1))就可以快速定位出数据。
但没想到按下去葫芦起了瓢。
上述方案大幅增加了表中记录条数,另一个场景偏偏是通过filed1查询记录,记录条数的增加波及影响恶化了该场景的性能,被波及场景使用率不高,测试也没有测试到,但上线后恰恰出现了该场景,并对其他网元造成波及影响,造成重大线上级联故障。。。
根因
这个问题根因很多,项目也做了很多深刻的反思,有设计人员波及影响识别遗漏的问题,有开发人员能力不足的问题,有测试人员测试场景和数据不全的问题。。。。
但是我觉得还有个角度需要我们探讨,那就是架构能量密度的问题。
记得一部纪录片,讲的是陶器时代的随葬品都是很多的普通陶罐等,出现这种情况的原因是当时的人们无法通过普通陶器这种手段把财富高度凝聚起来,那时的财富就无法高效传递,只能通过数量来解决。
架构设计也有类似问题,就上述故障来说,对于自研内存数据库查询特定场景这种高复杂度的特有知识散落到各个应用团队,这种情况会造成以下严重问题:
- 对特有知识的认知高度不够,特定问题可能选择不是最恰当的解决方式
- 对特有知识关键细节的遗失,造成解决方案的波及影响识别不全
- 架构散落后,不同应用团队都在解决同样高复杂度问题,造成设计开发测试工作的大量重复
解决思路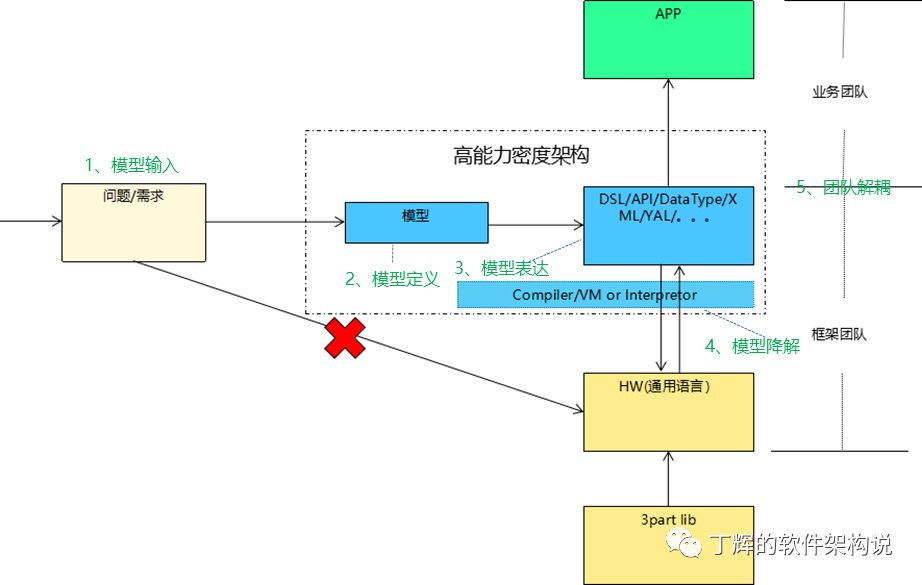
1.模型输入
选取影响系统架构的关键需求作为模型的输入
2.模型定义
对于复杂庞大的系统,需要进行系统建模,模型包括领域模型和脚手架。
- 领域模型
对需求进行离散化和符号化,找出其中一个个的功能内聚的点以及点与点之间的联系,抽象这些点代表的业务原语,分别表达出业务流程原语和业务逻辑原语,这些原语具备很强的能力密度,并且原语间兼具组合语义,这些原语就形成了领域模型。
如果问题领域模型足够narrow,规则性比较强的话,业务原语就可以表达为业务原子(处理独立的业务逻辑)、组合原子(处理业务流程),并且满足组合设计三规则:
- 原子相对独立
- 原子间可以组合
- 组合后的原子还具备原子性
还可以和其他原子进行组合,这样就很容易实现组合式设计。
- 脚手架
接口适配、协议编解码、基础设施、三方库、依赖隔离等。
3.模型表达
通过接口协议、API、DSL、DataType、XML、YAL等作为模型载体表达出领域模型,便于应用二次编排、组合、扩展出应用逻辑。
4.模型降解
- 解释器降解
通过自定义的解释器(执行引擎,把已编排的模型载体逐行转换成通用编程语言执行)
- 编译器降解
如果每次都解释自行,遍历AST(抽象语法树),执行性能较低。
可以通过编译器+自定义虚拟机方式执行,通过编译器把已编排的模型模型载体解释转换成自定义中间码流,然后把码流交给自定义虚拟机进行顺序执行,归并每次解释执行的时间,提升执行效率。
反康威定律&团队解耦
- 框架团队
模型、模型表达、模型降解执行三部分高复杂度的模块形成框架层,由框架团队进行维护,进行新模型的开发、自动化测试和守护、bug修复、性能调优。框架团队由经验丰富的员工组成。
- 应用团队
应用团队对模型表达的元素进行编排、组合形成业务功能,并进行端到端测试。一般以老带新,由比例较高的新员工组成。
应用团队一些员工随着能力提升,也可以下沉到框架团队,形成人员流动。
专业人做专业的事形成专业分工,根据大卫·李嘉图在其代表作《政治经济学及赋税原理》中提出了比较成本贸易理论(后人称为“比较优势贸易理论”),这种人才分布和分工才能最大程度提升团队效能。
小结
回到最初提到的问题,如果对自定义内存数据库的范围[start,end)高性能查询能定义出between .. and操作原语,应用开发人员可以直接使用这个原语进行范围查询;框架团队可以对这个原语进行正确的实现和性能优化。
这样才能提升架构的能量密度,由经验丰富的人维护高能量密度的架构,这样可以既做到更高的维护性价比,形成更为合理的专业分工,又可以大幅提升架构质量和易用性。
综上
架构的能量密度就是把系统中复杂度最高,最为僵化的部分内聚起来,并提供可组合语义的抽象描述和表达,框架团队对组合语义进行降解到通用语言实现,化僵化为灵活,变分散为聚焦;应用团队基于组合语义进行编排实现业务功能,各司其职,各尽所长,最大程度提升整体团队的知识积累和沉淀,最大程度复用已有框架,使得整体团队效能大幅提升。
声明:文中观点不代表本站立场。本文传送门:https://eyangzhen.com/213237.html



