
大模型对软件相关各个流程进行了赋能,都取得良好的效果。特别是代码辅助生成方面的应用,更是实现基础编程能力的平权,使通用功能编码效率大幅提升。
但是,对于强私域知识,由于通用大模型模型中没有这部分知识,通常的prompt就无法高效地生成代码。
这个很容易理解,代码其实是业务知识的载体,通用大模型就像一个计算机系的毕业生,编程能力很强,但是没有业务知识和经验,自然他就无法独立完成写成业务代码。
从一个例子看起:
这是我们产品的一个功能,其核心逻辑是一个算法,抽象出来描述如下:
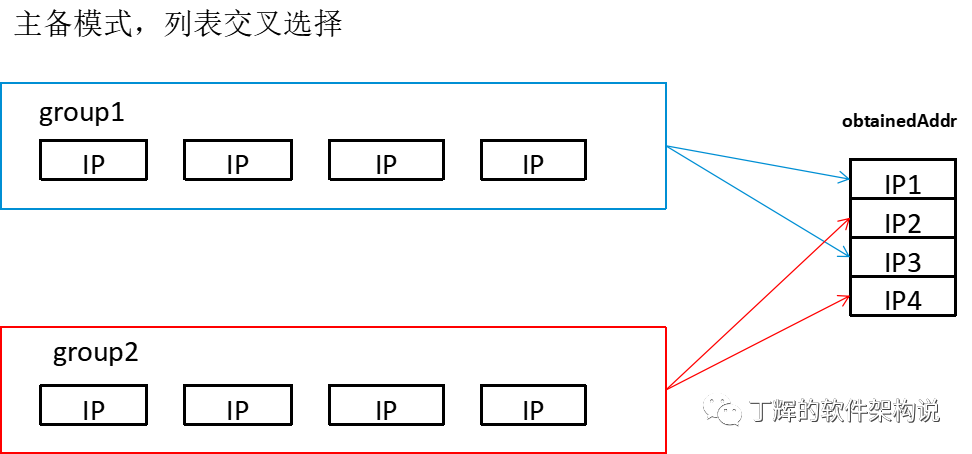
- 有两个数组列表分别存储不同的地址,数组分主备两种属性,算法目的是从两个列表中分别取出地址放到一个输出列表中
- 模式分主备和负荷分担,主备模式时保证主列表地址放在输出列表的第一位,负荷分担模式放在输出列表第一位是随机的
- 选择方式分列表交叉和列表优先,列表交叉表示分别从两个列表中交替获取地址,列表优先表示先存其中一个列表的地址,再存另一个列表的地址
要求通用大模型给上述功能输出测试用例和实现代码。
见下图:

按这个需求,我写了一个生成测试用例的prompt:
## 任务要求
你是一个C语言专家,擅长TDD,下面我需要你根据需求生成测试用例。
## 函数功能当bSelMode为1的时候,表示主备模式,该函数会从列表group1和group2中交叉获取T_P,按获取顺序保存到obtainedAddr中,第一个元素要从group1中获取
## 函数签名
VOID getpBySelMode(T_Group &group1,T_Group &group2, ObtainedAddr &obtainedAddr, BYTE bSelMode)
## 数据结构### 公共的数据结构```ctypedef struct T_P{ BYTE ucWeight; BYTE dAddress[16];} T_P;```
### 输入的数据结构```ctypedef struct T_Group{ T_P atP[4];}T_Group;
```
### 输出的数据结构```cstruct T_outP{ T_P t[4];};
struct ObtainedAddr{ T_outP tIpv4;};```
## 任务重申
你是一个C语言专家,擅长TDD,下面我需要你根据上面的上下文生成测试用例。通用大模型输出:
## 测试用例
1. 给定两个类表group1和group2,其中group1包含4个T_P结构,group2包含3个T_P结构。bSelMode为1。2. 调用getpBySelMode函数。3. 验证obtainedAddr是否包含前两个元素从group1获取的T_P结构,以及后两个元素从group2获取的T_P结构。
```cvoid test_getpBySelMode(){ // 给定输入数据 T_Group group1 = { { {1, {0x01, 0x02}}, {2, {0x03, 0x04}}, {3, {0x05, 0x06}}, {4, {0x07, 0x08}} } }; T_Group group2 = { { {5, {0x09, 0x0A}}, {6, {0x0B, 0x0C}}, {7, {0x0D, 0x0E}} } }; ObtainedAddr obtainedAddr; BYTE bSelMode = 1;
// 调用函数 getpBySelMode(group1, group2, obtainedAddr, bSelMode);
// 验证输出 assert(obtainedAddr.tIpv4.t[0].ucWeight == 1 && memcmp(obtainedAddr.tIpv4.t[0].dAddress, "x01x02", 2) == 0); assert(obtainedAddr.tIpv4.t[1].ucWeight == 2 && memcmp(obtainedAddr.tIpv4.t[1].dAddress, "x03x04", 2) == 0); assert(obtainedAddr.tIpv4.t[2].ucWeight == 5 && memcmp(obtainedAddr.tIpv4.t[2].dAddress, "x09x0A", 2) == 0); assert(obtainedAddr.tIpv4.t[3].ucWeight == 6 && memcmp(obtainedAddr.tIpv4.t[3].dAddress, "x0Bx0C", 2) == 0);
printf("Test passed.n");}```大家可以看到,用例生成的不对

从图中红线部分可以看出,结果ip列表obtainedAddr中的数据没有实现交替从group1和group2中获取,看来通用大模型没有理解交叉这个词的含义。
针对这种强私域场景下,大模型如果一定要用,这里我们给出两种思路:
一、私域知识剥离
把私域知识人工转换为通用数据结构和算法,把私域知识剥离,然后通过prompt告诉大模型,相当于有个ba帮通用大模型做好业务分析和设计,然后通用大模型再发挥擅长基础编程能力的特长,快速生成相对通用的代码和用例。
有时这些生成的代码和用例需要反向补充业务知识,还需要人工进行手工注入私域知识到生成物中。
这一步对开发人员的能力有较高要求,也会耗费较多工作量。
二、私域知识注入
1、上线文prompt注入
大家看下我提供的生成测试用例的prompt,需要把每个出现的接口的原型(入参、出参、返回值、抛出的异常等)、结构体(含义、字段、使用场景等)、关键业务概念和行为都提供详细的解释。
比如需要增加详细解释的交叉含义:
### 交叉的含义交叉是指对于两个列表来说,依次分别从两个列表中逐个取元素的意思这一部分也需要投入工作量。
2、Few-shot learning
短样本学习,通过短样本给通用大模型举例来解释清楚私域知识,从而让它学会这些私域知识,然后通用大模型再去应用。
比如案例中,我提供了一个短样本并放入prompt中:
###以下例子说明了什么是交叉的含义两个列表a={1,2,3,4}和b={5,6,7,8},将a和b包含的元素交叉放入到列表c中,c的值为{1,5,2,6,3,7,4,8}这样通用大模型就学会了交叉的含义。
下面咱们用私域知识注入的方式来修改案例的prompt:
## 任务要求
你是一个C语言专家,擅长TDD,下面我需要你根据需求生成测试用例。
## 函数功能当bSelMode为1的时候,该函数会从列表group1和group2中交叉获取T_P,按获取顺序保存到obtainedAddr中,第一个元素要从group1中获取
### 交叉的含义交叉是指对于两个列表来说,依次分别从两个列表中逐个取元素的意思
## 函数签名
VOID getpBySelMode(T_Group &group1,T_Group &group2, ObtainedAddr &obtainedAddr, BYTE bSelMode)
## 数据结构### 公共的数据结构```ctypedef struct T_P{ BYTE ucWeight; BYTE dAddress[16];} T_P;```
### 输入的数据结构```ctypedef struct T_Group{ T_P atP[4];}T_Group;
```
### 输出的数据结构```cstruct T_outP{ T_P t[4];};
struct ObtainedAddr{ T_outP tIpv4;};```
## 任务重申
你是一个C语言专家,擅长TDD,下面我需要你根据上面的上下文生成测试用例。大模型输出:
## 测试用例
1. 给定两个列表group1和group2,其中group1包含4个T_P结构,group2包含3个T_P结构。bSelMode为1。2. 调用getpBySelMode函数。3. 验证obtainedAddr是否包含按交叉顺序获取的T_P结构。
```cvoid test_getpBySelMode(){ // 给定输入数据 T_Group group1 = { { {1, {0x01, 0x02}}, {2, {0x03, 0x04}}, {3, {0x05, 0x06}}, {4, {0x07, 0x08}} } }; T_Group group2 = { { {5, {0x09, 0x0A}}, {6, {0x0B, 0x0C}}, {7, {0x0D, 0x0E}} } }; ObtainedAddr obtainedAddr; BYTE bSelMode = 1;
// 调用函数 getpBySelMode(group1, group2, obtainedAddr, bSelMode);
// 验证输出 assert(obtainedAddr.tIpv4.t[0].ucWeight == 1 && memcmp(obtainedAddr.tIpv4.t[0].dAddress, "x01x02", 2) == 0); assert(obtainedAddr.tIpv4.t[1].ucWeight == 5 && memcmp(obtainedAddr.tIpv4.t[1].dAddress, "x09x0A", 2) == 0); assert(obtainedAddr.tIpv4.t[2].ucWeight == 2 && memcmp(obtainedAddr.tIpv4.t[2].dAddress, "x03x04", 2) == 0); assert(obtainedAddr.tIpv4.t[3].ucWeight == 6 && memcmp(obtainedAddr.tIpv4.t[3].dAddress, "x0Bx0C", 2) == 0);
printf("Test passed.n");}```可以看出私域知识注入已经取得了不错的效果,下图中红线部分标明通用大模型输出已经实现了列表交叉,说明通用大模型已经理解了该私域知识。

小结
通用大模型对通用基础编程效果较好,但是对于强私域知识的场景下,需要对通用大模型进行私域知识的剥离或注入,才能使通用大模型学习并理解这些强私域知识,进而才可能输出正确的代码和用例。
另外,强私域知识场景下,如果想大幅提高prompt的效率,让开发人员写prompt更简单,必须对通用大模型进行精调或增量预训练把强私域知识注入,把通用大模型变成领域垂直大模型,这样prompt的难度就会大幅降低,真正借助大模型进一步提升软件研发效率。
声明:文中观点不代表本站立场。本文传送门:https://eyangzhen.com/372980.html



