
自大模型兴起以来,在各个方面都获得长足的应用,各种场景都以落地应用大模型为自己的标签,那可真是应了时来天地同协力。
但是大模型本身是基于概率的,要实现大模型特别是通用大模型的确定性输出效果必然有很多局限:
1、必须缩窄应用的范围,特定narrow的领域。
2、需要外挂知识库,实现确定性增强搜索。
但是,有个领域却可以天然使用通用大模型,它可以天生克制大模型输出的不确定性。这就是软件编码领域,因为无论如何大模型生成的代码被取用的部分都必须通过代码审查、修改、调测跑通之后才会被采纳并最终合入代码库。
换句话说软件编码领域会对大模型输出的确定性进行兜底,这也是为啥大模型在软件编码领域这么火的原因。
从软件设计的角度来说,设计的本质就是把业务逻辑(具体的一个个垂直的业务功能)用业务流程(水平的编排组合手段)串接的过程。
设计的本质就是把业务逻辑和业务流程相分离然后重新抽象组合的过程。
对于业务逻辑来说,其通过业务知识剥离都基本可以转换成通用大模型的prompt,利用大模型帮你生成(类似下图的样子)代码。

对于业务流程来说,则基本都是私域知识,通用大模型(使用私域知识训练过的领域编码大模型另当别论)往往生成不了,很多时候都需要你手工实现串接。
这个过程可以参见下图,其中小圆圈就是业务逻辑,箭头就是业务流程,业务流程把业务逻辑编排组合起来。

大模型编程基本可以分为全新功能开发和遗留代码新增功能开发两种,对于全新功能开发,就可以利用上述软件设计的方式,把业务逻辑和业务流程相分离,业务逻辑通过大模型生成,然后手工把业务逻辑编排串接起来形成业务流程的方式进行。
大模型如何辅助编程生成代码我们讲了很多,也可以参照我以往的文章《程序员不会被大模型替代,只会被更会用大模型的同行替代。不想被替代的速看代码生成确定性prompt怎么做!!!》
但是遗留代码中新增功能如何利用大模型进行代码生成呢?
一提遗留代码,一般统称shi山代码。典型特征为系统严重耦合,功能肆意蔓延,逻辑私搭乱建,语句一团乱麻,非常难以理解和难以维护。
大家常说的:晦涩的命名、无序的排版、混乱的逻辑,超高的圈复杂度就是这类代码的集中表现。


遗留代码本身的强耦合的最大恶果是波及影响大,造成彼此纠缠、互相嵌套,理不清道不明。在遗留代码上新增功能,本身就是一件非常痛苦的事,其表现如下:
1、变量生命周期过长
很多时候,修改的功能可能就几行代码,但是知道改哪几行代码以及怎么改却需要读懂周围几十行甚至几百行代码,成本非常高。试想一个临时变量(假设是i)作用域就超过上百行,i在不同的位置都有不同的业务含义,谁敢轻易对i进行修改?
2、发散式变化
我们都希望一个实体(模块、类/文件、函数)只承担一个职责,比如在一个数据库访问模块中,我们期望数据库权限控制和数据访问DML这两种职责相分离,这样可以相互独立变化,便于维护、便于理解,但遗留代码可不这样,往往都是一个实体承担多种职责,任何一种职责的代码细微修改,都会波及到其他职责,一不留神,重大看起来跟修改代码八竿子打不着的深层故障就出现了。
3、霰弹式修改
这里又可以分两种情况:
- 职责分散
代码功能不内聚,一个职责代码散落到多个实体(模块、类/文件、函数)中,必须多处修改才能完成该职责。
- 职责重复
不同模块逻辑重复,这种重复很多时候还不是长的一样的代码,而是不同功能入口的重复代码,比如GUI、API、命令行等后面相同的业务都是重复实现,这样就造成的实现逻辑重复。
以上两种情况,会造成任一个业务领域模型职责的修改都需要多点修改,很容易造成修改点遗漏,造成重大故障。
上述情形的遗留代码中,当使用大模型进行新增代码生成时往往束手无策,新增功能时无法将上下文不同实体代码都进行prompt的知识注入(超出大模型最大token数),或者耦合过大,注入时遗留知识/知识错乱造成大模型生成错误。
这时开发人员一般不会吐槽遗留代码(自己维护的),大部分都会吐槽大模型(心中暗喜,这下不会被大模型替换掉了):
大模型编程能力不强,我们的代码都搞不定咋用啊,大模型还需要进行私域代码的再训练和精调;
大模型的能力很强,但我们产品比较特殊,不适合大模型,还是别推广大模型编程了。
这时候如果进行遗留代码架构重构,往往代价过大。我们需要一种手段,把新增功能用足够内聚的方式隔离出来,先行用大模型生成代码进行交付。
其实针对上述遗留代码,我们可以使用发芽模式进行大模型的代码生成,即新增代码中的业务逻辑委托到一个修改点实体中,然后在遗留代码的多点修改中调用该实体中的业务逻辑,就像一个植物的枝杈上发出新芽一样。
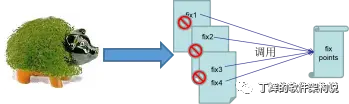
具体步骤如下:
1、拆分出新增功能中的业务逻辑
2、把这些业务逻辑内聚成一个实体(模块、类/文件、函数)
3、使用大模型根据提示词生成该实体中的业务逻辑
4、遗留代码修改点中调用这些业务逻辑
5、后续择机再对遗留代码进行重构
至此,我们解释了遗留代码新增功能使用大模型生成代码的困境、原因和解决思路。
从这里可以看到,大家很容易高估软件开发中代码编写的工作量,而很容易低估软件开发中设计的重要性,无论有没有大模型,软件设计都是不可或缺的。
软件设计对于大模型不是可有可无的,而是缺了软件设计,再厉害的大模型也会束手束脚,能力会大打折扣。
声明:文中观点不代表本站立场。本文传送门:https://eyangzhen.com/389007.html



