
- 背景
代码覆盖率是衡量测试用例对代码的覆盖程度的指标,可以帮助开发人员和测试人员优化测试用例、提高代码质量。此外,代码覆盖率也可以帮助领导和项目经理评估开发进度和质量,以便及时调整计划和资源分配。总之,代码覆盖率功能对于保证软件质量、提高开发效率和降低维护成本都具有重要意义。转转公司内部已经成功实现了针对Java项目的增量代码覆盖率,但是前端项目的覆盖率并没有得到有效的监测和管理。为此我们开发了针对fe项目的增量代码覆盖率功能,并在本文中与大家分享我们的经验、挑战和解决方案。希望能够抛砖引玉,与各位同行进行深入的探讨和交流。 - 技术选型
Istanbul, ScriptCover和JsCover都是常用的代码覆盖率工具,它们可以用于跟踪JavaScript代码的测试覆盖情况。下面是它们的简要对比:
工具 特点
Istanbul 支持语句覆盖、分支覆盖、条件覆盖和路径覆盖等多种覆盖率度量,可以集成到各种测试框架中,生成的覆盖率报告通常以lcov格式输出
ScriptCover 支持语句覆盖、分支覆盖、条件覆盖等多种度量,可以集成到各种测试框架中,特点之一是可以在浏览器中实时查看代码覆盖率
JsCover 支持语句覆盖和分支覆盖,可以生成HTML格式的覆盖率报告,提供了直观的可视化界面来展示代码覆盖情况,可以集成到各种测试框架中
前端测试框架(如jest、karma、cypress)内置了代码覆盖率统计,统一使用了istanbul工具。istanbul是一种成熟的前端代码覆盖率技术方案,虽然维护不活跃,但几乎是唯一可选方案。诸多前端测试框架的覆盖率统计都使用了它,在一定程度上也能说明 istanbul 是可行的。它提供了插桩、合并和生成覆盖率报告的工具,但是没有完全适配转转的增量代码覆盖率的统计方案。因此我们基于istanbul设计了覆盖率统计流程,结合公司内部的后端代码覆盖率统计平台,完成了前端代码覆盖率的统计和可视化工作。 - 实现方案
基于 istanbul 做的覆盖率统计大致可以分为以下五步:插桩,覆盖率数据收集,数据上报,数据接收,报告生成。
3.1 插桩
插桩是通过在源代码中插入特定的监测代码来跟踪程序运行过程中的路径和条件分支的执行情况。istanbul 只会对 js 代码插桩,也就是仅跟踪我们程序的逻辑执行。
测试代码如下:
function istanbul_test() {
console.log(‘istanbul_test’);
}
function istanbul_test2() {
console.log(‘istanbul_test2’);
}
var test = false
if (test) {
istanbul_test();
} else {
istanbul_test2();
}
插桩后
var cov_GpzNBZZeWVNtWXQEPAI_7w = (Function(‘return this’))(); if (!__cov_GpzNBZZeWVNtWXQEPAI_7w.__coverage) {
cov_GpzNBZZeWVNtWXQEPAI_7w.__coverage = {};
}
cov_GpzNBZZeWVNtWXQEPAI_7w = __cov_GpzNBZZeWVNtWXQEPAI_7w.__coverage;
if (!(__cov_GpzNBZZeWVNtWXQEPAI_7w[‘/istanbul/index.js’])) {
__cov_GpzNBZZeWVNtWXQEPAI_7w[‘/istanbul/index.js’] = {
“path”: “/istanbul/index.js”,
“s”: {
“1”: 1,
“2”: 0,
“3”: 1,
“4”: 0,
“5”: 0,
“6”: 0,
“7”: 0,
“8”: 0
},
“b”: {
“1”: [0, 0]
},
“f”: {
“1”: 0,
“2”: 0
},
“fnMap”: {
“1”: {
“name”: “istanbul_test”,
“line”: 1,
“loc”: {
“start”: {
“line”: 1,
“column”: 0
},
“end”: {
“line”: 1,
“column”: 25
}
}
},
“2”: {
“name”: “istanbul_test2”,
“line”: 5,
“loc”: {
“start”: {
“line”: 5,
“column”: 0
},
“end”: {
“line”: 5,
“column”: 26
}
}
}
},
“statementMap”: {
“1”: {
“start”: {
“line”: 1,
“column”: 0
},
“end”: {
“line”: 3,
“column”: 1
}
},
“2”: {
“start”: {
“line”: 2,
“column”: 4
},
“end”: {
“line”: 2,
“column”: 33
}
},
“3”: {
“start”: {
“line”: 5,
“column”: 0
},
“end”: {
“line”: 7,
“column”: 1
}
},
“4”: {
“start”: {
“line”: 6,
“column”: 4
},
“end”: {
“line”: 6,
“column”: 34
}
},
“5”: {
“start”: {
“line”: 9,
“column”: 0
},
“end”: {
“line”: 9,
“column”: 16
}
},
“6”: {
“start”: {
“line”: 11,
“column”: 0
},
“end”: {
“line”: 15,
“column”: 1
}
},
“7”: {
“start”: {
“line”: 12,
“column”: 4
},
“end”: {
“line”: 12,
“column”: 20
}
},
“8”: {
“start”: {
“line”: 14,
“column”: 4
},
“end”: {
“line”: 14,
“column”: 21
}
}
},
“branchMap”: {
“1”: {
“line”: 11,
“type”: “if”,
“locations”: [{
“start”: {
“line”: 11,
“column”: 0
},
“end”: {
“line”: 11,
“column”: 0
}
}, {
“start”: {
“line”: 11,
“column”: 0
},
“end”: {
“line”: 11,
“column”: 0
}
}]
}
}
};
}
__cov_GpzNBZZeWVNtWXQEPAI_7w = __cov_GpzNBZZeWVNtWXQEPAI_7w[‘/istanbul/index.js’];
function istanbul_test() {
__cov_GpzNBZZeWVNtWXQEPAI_7w.f[‘1’]++;
__cov_GpzNBZZeWVNtWXQEPAI_7w.s[‘2’]++;
console.log(‘istanbul_test’);
}
function istanbul_test2() {
__cov_GpzNBZZeWVNtWXQEPAI_7w.f[‘2’]++;
__cov_GpzNBZZeWVNtWXQEPAI_7w.s[‘4’]++;
console.log(‘istanbul_test2’);
}
__cov_GpzNBZZeWVNtWXQEPAI_7w.s[‘5’]++;
var test = false;
__cov_GpzNBZZeWVNtWXQEPAI_7w.s[‘6’]++;
if (test) {
__cov_GpzNBZZeWVNtWXQEPAI_7w.b[‘1’][0]++;
__cov_GpzNBZZeWVNtWXQEPAI_7w.s[‘7’]++;
istanbul_test();
} else {
__cov_GpzNBZZeWVNtWXQEPAI_7w.b[‘1’][1]++;
__cov_GpzNBZZeWVNtWXQEPAI_7w.s[‘8’]++;
istanbul_test2();
}
对于前端来说,覆盖率主要有四个准则:
1.行覆盖率(Line Coverag):是否每一行都执行了
2.函数覆盖率(Function Coverage):是否每个函数都调用了
3.分支覆盖率(Branch Coverage):是否每个分支都执行了
4.语句/指令/声明 覆盖率(Statement Coverage):是否每个语句都执行了
在上述代码中可以看到,我们用 _cov 收集了 文件中函数和语句的执行次数,由此就能知道代码有没有被覆盖(是否执行过)。
全局变量中记录了这些信息:
path:路径
s:statement 数量
b:branch 数量
f:function 数量
fnMap:function 的开始结束位置信息
statementMap:statement 的开始结束位置信息
branchMap: branch 的开始结束位置信息
覆盖率的原理就是对每个 statement、function、branch 都插入一段计数代码,记录在一个全局对象中。
需要注意的是插桩会侵入源码(会在代码中插入一些计数器),istanbul 统计前端代码覆盖率的这套方案设计上即是如此,因此难以避免会增加项目打包后的包体积。目前我们要求只在测试环境 编译代码时对发生变更的类进行插桩和覆盖率统计,因此不会影响生产环境的代码。虽然破坏了Devops的从测试到上线使用同一个包的基本原则,但是考虑到插桩的基本原理是插入计数器,原则认为他们能是同一个包。
3.2 数据收集
从用户浏览器中开始进行功能测试到用户关闭浏览器,这个过程中产生的覆盖率数据是累计的。如果我们能够获取到本次测试的”覆盖率对象”并将其存储起来,就能用来生成本次访问的覆盖率报告。
getAllCoverage() {
const coverage = window.coverage
if(coverage == undefined) return []
return Object.entries(coverage).reduce((prev,cur)=>{
const [key,value] = cur
prev.push({
pathName: key,
coveredLines: this.getLines(value),
totalLines: this.getLineCoverages(value)
})
return prev
},[])
}
getLines(data = {}){
const lines = []
const { s = {}, statementMap = {} } = data
Object.entries(s).forEach(([key,count])=>{
if(count > 0){
const { start, end } = statementMap[key]
for(let i = start.line; i<= end.line; i++){
lines.push(i)
}
}
})
return [...new Set(lines)]
}
getLineCoverages(data) {
const lines = []
const { s = {}, statementMap = {} } = data
Object.entries(s).forEach(([key,count])=>{
const { start, end } = statementMap[key]
for(let i = start.line; i<= end.line; i++){
lines.push(i)
}
})
return [...new Set(lines)]
}3.3 数据上报
我们通过webpack的插件来实现的数据上报,每10s上报一次数据到覆盖率统计平台或者用户关闭页面自动触发上报,由覆盖率统计平台对改动的代码进行统计,并对插桩成功和已覆盖行进行标注,生成增量代码覆盖率统计报告。
上报文件级别的代码行统计数据是生成可视化覆盖率报告的基础,为后续方便研发和测试人员查看代码的执行和覆盖情况提供数据支撑。针对转转当前测试环境申请标签并在标签上部署服务的现状,目前上报数据格式定义在(标签,服务,分支,用户)的维度,方便覆盖率统计平台快速统计用户在单个标签上的某个服务的覆盖率数据并完成格式化的展示。
const PAGE_META = window.PAGE_META
if(PAGE_META == undefined) return
const submitData = {
clusterName: PAGE_META.cluster,
branchName: PAGE_META.branch,
ipOrTagName: PAGE_META.tag,
uniqId: this.uid,
feClassCoverInfoList: data.map(item=>{
return {
…item,
pathName: this.handlePath(item.pathName),
}
}),
nowTimestamp: Date.now()
}
通过构建工具,我们将页面中全部变量注入到 _window.PAGE_META 。从而在上报数据的时候,可以获取到项目信息、分支信息、插桩行和覆盖行信息,同时也方便开发者快速排查代码行是否覆盖的正确性问题。
此外,为了减少上报数据的量级,降低覆盖率统计系统处理数据的复杂度,我们只对发生变更的文件进行插桩和数据上报。通过构建平台在编译阶段向项目中写入增量目录到diffFileList.conf文件,然后在babel-plugin-istanbul中传入include参数来控制只对比增量。
3.4 数据接收
在功能测试阶段,覆盖率系统负责接收统计数据。如果上报数据的时间间隔太长会导致用户查看覆盖率有较大的延迟,如果间隔太短,会增加系统需要处理的数据量级,综合评估,目前我们将时间间隔定义为10S。
为了提高数据接收接口的性能,我们采用同步记录DB后立刻返回结果,线程异步处理历史数据的方案。在异步处理阶段,因为每个用户在同一个环境进行测试时,产生的覆盖率数据会一直上报最新的全量覆盖率数据,因此我们会对当前环境当前用户上报的数据进行预处理,将最新上报的数据和历史数据合并然后插入数据库,以便后续用户获取最终覆盖率结果时,减少需要处理的数据量,降低接口响应耗时。
接受数据处理逻辑示意图
以上图为例,同学A和同学B在并行测试同一个环境上的同一个分支的服务,浏览器上报了同学A的数据1和数据3,同学B的数据2和数据4,由于数据预处理阶段会将最新上报的数据和历史数据合并然后插入数据库,因此自动将1和2置为无效数据。在生成报告阶段,只需要将有效的数据取并集,即可获取全量的覆盖率数据。
3.5 生成报告
3.5.1 数据预处理
预处理阶段主要是用户在提交完代码完成编译之后,后端系统会通过调用gitlab原生接口获取当前业务分支和线上主分支的差异,并将发生变更的文件列表、每个文件中发生变更的行号和代码记录覆盖率系统数据库中,为后续用户查看代码变更及统计覆盖率提供基础数据。
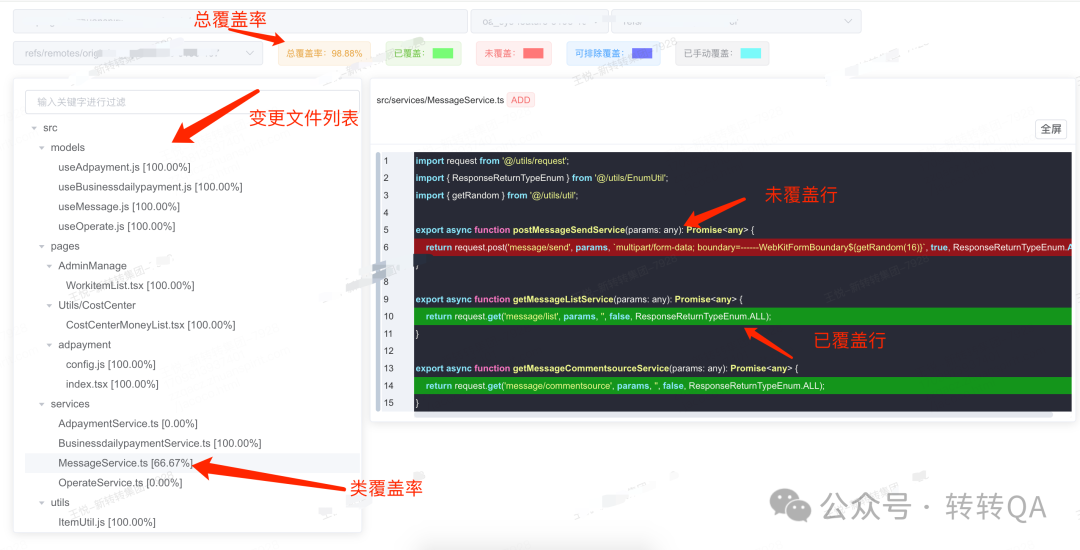

增量代码和覆盖率展示示例
3.5.2 覆盖率计算
鉴于目前fe项目插桩方案的局限性,目前对于没有插桩的代码行,并没有记入覆盖率统计的范畴。

覆盖率计算公式
4 过程中遇到的问题
4.1 上报过程中数据丢失
在插件使用初期,因为系统问题,偶尔会出现数据不上报的问题,但是复现过程比较麻烦。需要配置项目的代理,走一遍测试流程。同时很多项目有权限限制等问题,导致复现问题比较耗费时间。为了方便排查我们添加了日志功能,通过日志来记录操作流程。
4.2 覆盖率数据延迟
部分用户完成功能测试后,马上查看覆盖率发现数据不准确,为了降低延迟,我们将数据上报的频率提高,但是数据量的上升增加了处理数据的难度,因此我们采用了异步处理的方案。
4.3 插件迭代升级
插件使用初期会不断迭代修复,每次都需要通知用户升级插件版本。我们添加了版本号的校验机制,当插件版本号发生变化时,会自动的更新插件版本。保证用户使用的插件一直是最新的版本。
4.4 编译时间增加
使用Istanbul工具统计代码覆盖率时需要编译测试包和线上包,串行编译会导致编译时长的增加。我们通过并行编译,减少了整个编译过程的时间。这样一来,即使使用了Istanbul工具进行代码覆盖率的检测和分析,也能够保持较高的开发效率。
5 总结
本文介绍了转转团队如何实现增量代码覆盖率统计的问题并给出得解决方案,是对前端项目代码质量管理的重大改进。通过执行本方案,我们不仅优化了测试流程,确保了新提交的部分代码得到了有效的覆盖,同时也提升了我们的开发效率和软件的稳定性。
目前公司内前端项目的代码覆盖率整体接入率为 80% ,迭代中的前端项目基本都已经完成接入。实践证明,代码覆盖率统计可以有效的帮助我们拦截不经过测试就上线的代码,现在代码覆盖率已经成为上线前的一道保障。
6 展望
在未来,我们将继续优化增量代码覆盖率统计的实现方案。后续计划探索以下几个方向:
新技术适配:随着前端技术栈的发展,我们也需要确保覆盖率工具能与时俱进,例如适应Vue3等新技术。
扩展覆盖性:目前我们主要覆盖JS代码,未来我们会探索包含CSS和HTML在内的全面覆盖率解决方案。
我们期望与社区共同进步,持续分享我们的经验与挑战,并希望能得到更多专业人士的反馈和建议。
作者
陈金鑫 转转高级前端工程师
王悦 转转高级测试开发工程师
声明:文中观点不代表本站立场。本文传送门:https://eyangzhen.com/413592.html



